Online-Journalist Matthias ist Gründer und Herausgeber von THE DECODER. Er ist davon überzeugt, dass Künstliche Intelligenz die Beziehung zwischen Mensch und Computer grundlegend verändern wird.
Das KI-Startup Resemble AI hat mit Chatterbox ein quelloffenes Sprachsynthese-Modell veröffentlicht, das unter MIT-Lizenz verfügbar ist. Chatterbox kann Stimmen mit nur wenigen Sekunden Referenz-Audio klonen und erlaubt per Emotionsparameter die Steuerung des Sprechstils – etwa dramatisch oder monoton. Die Software läuft lokal und soll in Echtzeit mit unter 200 Millisekunden Latenz reagieren. Sie funktioniert laut Foren stabil auf Windows, Mac, Linux und mit nur 5–6 GB VRAM. Alle generierten Audiodateien enthalten ein kaum hörbares Wasserzeichen ("PerTh") zur Erkennung von KI-Stimmen. In internen Blindtests wurde Chatterbox laut Resemble AI häufiger als ElevenLabs bevorzugt. Das Modell richtet sich in erster Linie an Entwickler und scheint primär auf Englisch optimiert zu sein:
"The OpenAI Files" ist eine öffentlich zugängliche Plattform, die dokumentierte Kritik an OpenAIs Führungsstruktur, Unternehmenskultur und strategischer Ausrichtung bündelt. Veröffentlicht am 18. Juni 2025, enthält das Projekt Berichte ehemaliger Mitarbeitender, Analysen zu geplanten Umstrukturierungen sowie Einschätzungen zur Rolle von CEO Sam Altman. Im Zentrum steht die Frage, ob OpenAI seine gemeinnützige Mission zugunsten unbegrenzter Investorenrenditen aufgibt. Die Website bietet Einsicht in interne Dokumente und fordert Veränderungen in Transparenz, Sicherheit und Aufsicht. Ziel ist es laut Betreiber, eine öffentliche Debatte über OpenAIs Verantwortung bei der Entwicklung leistungsstarker KI-Modelle anzustoßen.
OpenAI hat den Modus "ChatGPT Record" – vorerst nur für die macOS-Desktop-App und Pro-, Team-, Enterprise- und Edu-Nutzer – veröffentlicht. Damit lassen sich Audioaufnahmen etwa für Besprechungen oder Sprachnotizen aufzeichnen, transkribieren und automatisch als strukturierte Zusammenfassungen speichern. Die Funktion ist auf 120 Minuten pro Sitzung begrenzt und soll derzeit am besten auf Englisch funktionieren. Audioaufnahmen werden nach der Transkription gelöscht und laut Hersteller nicht fürs Modell-Training verwendet. Für Enterprise- und Edu-Nutzer gibt es die Funktion auch über die Compliance-API. Erstmals wurde die Funktion Anfang Juni vorgestellt.
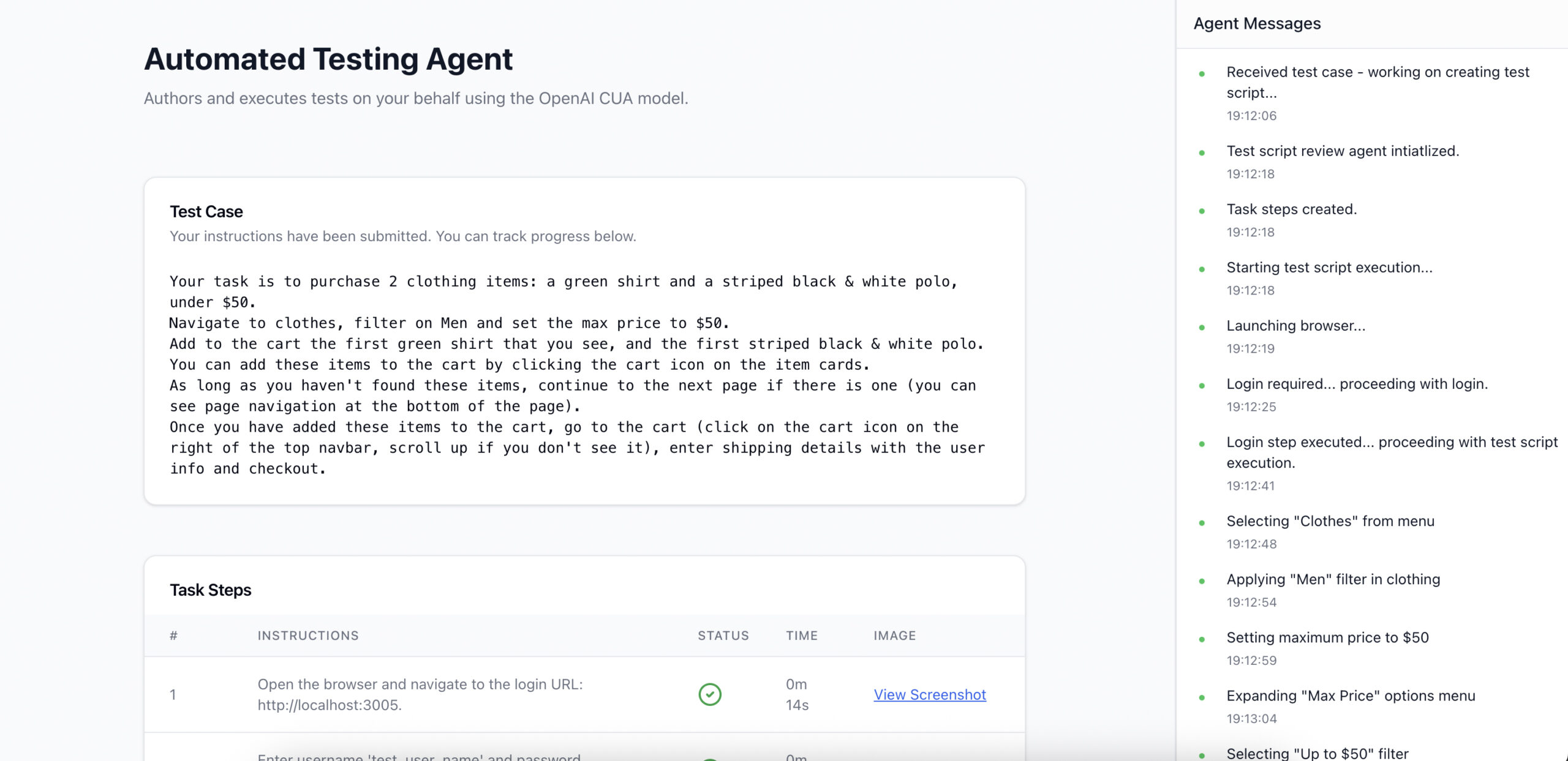
OpenAI veröffentlicht eine Demo für einen KI-gestützten UI-Testagenten auf GitHub, der automatisiert Frontends testet. Das Tool basiert auf dem OpenAI Computer-Using Agent (CUA) und dem Open-Source-Framework Playwright. Es kann selbstständig auf Basis von Beschreibungen Testfälle erstellen, durchführen und auswerten. Ziel ist laut OpenAI, die Effizienz und Qualität von Softwaretests zu verbessern, indem KI-Modelle den gesamten Testprozess unterstützen. Das Projekt ist derzeit noch eine Konzeptstudie.