Code Llama 70B: Metas neue Open Source Code-KI übertrifft GPT-4 in Code-Benchmark

Update –
- Veröffentlichung von Code Llama 70B ergänzt
Aktualisierung vom 29.01.2024:
Meta hat die neueste Version von Code Llama veröffentlicht. Code Llama 70B ist ein leistungsfähiges Open-Source-LLM für die Codegenerierung. Es ist zusätzlich zum grundlegenden Modell in zwei Varianten erhältlich, CodeLlama-70B-Python und CodeLlama-70B-Instruct. Laut Meta eignet es sich für die Forschung und für kommerzielle Projekte. Es gelten die üblichen Llama-Lizenzen.
Die neue 70B-Instruct-Version erreichte bei HumanEval eine Bewertung von 67,8 und liegt damit knapp vor GPT-4 und Gemini Pro bei Prompts ohne Beispielen (zero-shot). Die erste Version von Code Llama erreichte bis zu 48,8 Punkte.
Die Leistungsfähigkeit von Code Llama macht es laut Meta zur idealen Basis für die Verfeinerung von Codegenerierungsmodellen und soll die Open-Source-Community insgesamt voranbringen. Schon die erste Code-Llama-Variante konnte von der Open-Source-Community signifikant verbessert werden.
Code Llama 70B und weitere Llama-Modelle können hier bei Meta angefordert werden. Weiter Informationen gibt es auch bei Github.
Ursprünglicher Artikel vom 24. August 2024:
Code Llama ist Metas verfeinerte Llama-2-Variante zur Codegenerierung.
Code Llama ist laut Meta eine Weiterentwicklung von Llama 2, die zusätzlich mit 500 Milliarden Code-Tokens und codebezogenen Tokens aus den code-spezifischen Datensätzen von Llama 2 trainiert wurde. Für das Training von Code Lama wurden mehr Codedaten über einen längeren Zeitraum verwendet.
Im Vergleich zu Llama 2 verfügt Code Lama über erweiterte Programmierfähigkeiten und kann beispielsweise auf die natürlichsprachliche Aufforderung "Schreib mir eine Funktion, die die Fibonacci-Folge ausgibt" den entsprechenden Code generieren. Ähnlich wie Microsoft Copilot kann es auch Code vervollständigen und Fehler im Code finden.
Video: Meta AI
Code Lama unterstützt gängige Programmiersprachen wie Python, C++, Java, PHP, Typescript (Javascript), C#, Bash und andere.
Drei Modelle und zwei Varianten
Meta veröffentlicht Code Llama in drei Größen mit 7 Milliarden, 13 Milliarden und 34 Milliarden Parametern. Das besonders große Kontextfenster liegt bei 100.000 Tokens, was das Modell vor allem für die gleichzeitige Verarbeitung großer Codemengen interessant macht.
"Wenn Entwickler einen großen Teil des Codes debuggen müssen, können sie die gesamte Codelänge an das Modell übergeben", schreibt Meta AI.
Die Variante mit 34 Milliarden Parametern soll die höchste Codequalität liefern und eignet sich daher als Code-Assistent. Die kleineren Modelle sind für die Code-Vervollständigung in Echtzeit optimiert. Sie haben eine geringere Latenz und sind standardmäßig auf Fill-in-the-Middle (FIM) trainiert.

Zusätzlich veröffentlicht Meta eine für Python optimierte Code-Llama-Variante, die mit weiteren 100 Milliarden Python Code Tokens trainiert wurde, sowie eine Instruct-Variante, die mit Codeaufgaben und deren Musterlösungen optimiert wurde. Diese Variante wird von Meta für die Codegenerierung empfohlen, da sie den Prompts besonders genau folgen soll.
KI für Code: Code Llama übertrifft andere Open-Source-Modelle, aber GPT-4 bleibt vorne
In den Benchmarks HumanEval und Mostly Basic Python Programming (MBPP) erzielt Code Llama 34B Ergebnisse auf dem Niveau von GPT-3.5, liegt aber in Human Eval weit hinter GPT-4. Das nicht für Code optimierte Llama 2 übertrifft Code Llama ebenso wie andere getestete Open-Source-Modelle.
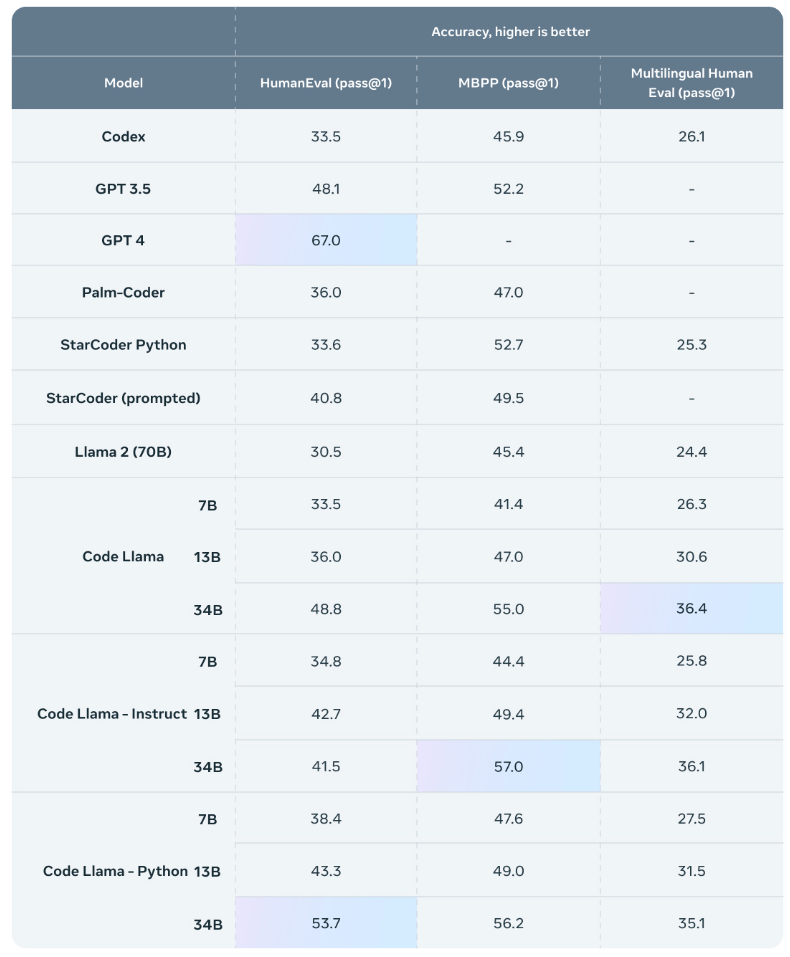
Meta veröffentlicht Code Llama unter derselben Llama Lizenz wie Llama 2 auf Github. Die Anwendung und die damit generierten Inhalte können für wissenschaftliche und kommerzielle Zwecke genutzt werden.
Die Open-Source-Initiative kritisiert Meta für die Vermarktung der Modelle als Open Source, da die Lizenz die kommerzielle Nutzung und bestimmte Anwendungsbereiche einschränke und damit nicht vollständig der Open-Source-Definition entspreche.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.