
Ende November beendete der südkoreanische Go-Spieler Lee Sedol seine professionelle Go-Karriere. Der ehemals weltbeste Spieler unterlag 2016 einer Künstlichen Intelligenz und sieht sich nun nur noch als Nummer Zwei.
Gebrochen wurde Sedol von Deepminds KI AlphaGo: Die Künstliche Intelligenz hatte Millionen menschlicher Spielzüge analysiert und entwickelte so nahezu perfekte Vorhersagen für den Spielverlauf. Kein Mensch kann mit dieser Fähigkeit konkurrieren.
Im November 2017 trat dann AlphaGo Zero an, den Vorgänger zu übertrumpfen: Die neue Deepmind-KI lernte Go ohne menschliche Vorlage. Nur mit den Regeln des Spiels ausgestattet, spielte sie unzählige Partien gegen sich selbst - und schlug nach drei Tagen AlphaGo hundertmal in 100 Spielen.

Deepmind baute AlphaGo Zero im selben Jahr noch weiter aus: AlphaZero spielt neben Go auch Schach und die japanische Schach-Variante Shōgi.
Zukunftsträchtige Lernmethode im Hintergrund
Grundlage für AlphaZeros Erfolg ist die KI-Trainingsmethode bestärkendes Lernen: Eine KI wird belohnt, wenn sie eine Aufgabe erfolgreich ausführt oder ihrem Ziel näherkommt.
Für was genau eine KI belohnt wird, bestimmen die Entwickler im Einzelfall – die Belohnung hängt von der zu erledigenden Aufgabe ab. Bei Space Invaders beispielsweise kann es Punkte geben für Abschüsse. In Schach wird ein Spielzug belohnt, der die Wahrscheinlichkeit einer Niederlage minimiert.
Nun hat Deepmind mit MuZero eine neue KI vorgestellt, die AlphaZeros Brettspiel-Niveau erreicht und zusätzlich Highscores in alten Atari-Computerspielen knackt. Um zu verstehen, warum das etwas Besonderes ist, müssen wir einen kurzen Blick auf AlphaZeros Geheimrezept werfen.
Modell-basiertes Spiele-Genie
AlphaZero spielt Brettspiele. Im Vergleich zu vielen Computerspielen haben diese eindeutige Spielregeln, die sich gut in Regelstrukturen, sogenannte Modelle, für Künstliche Intelligenz übersetzen lassen. Die KI weiß genau, wo Spielfiguren stehen können, welche Spielzüge erlaubt sind und wann ein Spiel vorbei ist.
Für AlphaZero programmierten Deepmind-Entwickler ein entsprechendes Modell für Schach, Shogi und Go. Basierend auf diesem Modell kann AlphaZero Spielzüge planen und vorhersagen, welche Aktionen wahrscheinlich zum gewünschten Ergebnis führen. Diese Variante der KI-Programmierung heißt Modell-basiertes bestärkendes Lernen.

Schachprofi aber Pong-Noob
Mit dieser Methode trainierte KIs schlagen zwar Weltmeister in Brettspielen. Sie liegen jedoch in alten Atari-Videospielen weit hinter KIs zurück, die ohne vorkonfiguriertes Modell auskommen. Wie kommt das?
Das Modell-freie bestärkende Lernen setzt auf das Versuch-und-Irrtum-Prinzip: Die KI absolviert ein Computerspiel, indem sie herumprobiert, bis eine Aktion funktioniert. Ob sie funktioniert, signalisiert ihr die Belohnung, die sie maximieren soll.
Dass die Modell-freie KI bei Computerspielen besser funktioniert als die Modell-basierte, hat einen einfachen Grund: Die Modellierung von Computerspielen ist aufwendig. Das Bildschirmgeschehen kann nicht mit einfachen Spielregeln beschrieben werden. KI-Forscher sprechen von einer "visuell komplexen Domäne" – für eine KI gibt es viel zu sehen und zu verstehen.

So sind die "Spielfelder" bei Videospielen umfangreicher als bei Brettspielen und können sich je nach Level ändern. Spielfiguren sind außerdem zu vielen unterschiedlichen Handlungen fähig: Sie können beispielsweise Gegenstände sammeln, Türen öffnen, Geschossen ausweichen oder zwischen Plattformen springen. Die KI muss daher jeden einzelnen Pixel verarbeiten, anstatt nur grundlegende Spielregeln zu verstehen.
Schwer zu beschreiben, einfach zu lernen
Modell-freie KIs wiederum haben jedoch zwei Nachteile:
- Sie benötigen umfangreiches Training
- und eignen sich nicht gut für planungsintensive Aufgaben.
Bei einfachen Aufgaben kann eine Modell-freie KI zwischen zehn und 100 Millionen Trainingsdurchläufen benötigen, bis sie die Aufgabe verlässlich meistert. Eine Modell-basierte KI kann vergleichbare Ergebnisse schon nach wenigen hundert Trainings erreichen.
In Spielen wie Go, Schach oder dem Videospiel Montezumas Revenge ist für einen Erfolg außerdem Planung gefragt. Hier versagen Modell-freie KIs, da sie ohne Modell schlicht nicht planen können.
Je komplexer eine Umgebung, desto schwieriger ist es also, sie perfekt für eine KI zu modellieren. Aber: Gerade in komplexen Umgebungen ist Planung erforderlich, um eine Aufgabe erfolgreich zu bewältigen. Und umso mehr Planung erforderlich ist, desto wichtiger wird ein Modell.
Eine Sackgasse? Vielleicht nicht, wenn Deepminds Lösung für dieses Problem greift: Die KI lernt ihr Trainingsmodell einfach selbst.
MuZero lernt Bretter und Bildschirme beherrschen
Hier kommt Deepminds MuZero ins Spiel: Die KI lernt die Spielregeln von Go, Schach, Space Invaders und anderen Spielen selbstständig. Dafür spielt die KI einfach drauflos, ohne fertiges Modell im Hintergrund.
Dieses Modell erstellt MuZero selbstständig während ihrer Spielversuche. Dafür nimmt sie den vorherigen Spielzustand, die geplante nächste Aktion und prognostiziert daraus den nächsten Zug (Strategie), den vorhergesagten Gewinner (Nutzenfunktion) und die zu erwartende direkte Belohnung, etwa Punkte, die durch einen Spielzug erzielt werden (Belohnung).
So nähert sich MuZeros Modell des Spiels mehr und mehr der Realität von Schach oder Space Invaders an – und wird immer genauer. Nach nur zwölf Stunden Training erreichte MuZero die Klasse von AlphaZero. In Go übertraf MuZero seinen Vorgänger sogar bei geringerem Energieverbrauch.
In Atari-Spielen übertraf MuZero den bisherigen Modell-freien Spitzenreiter (R2D2) in 42 von 57 Spielen und alle anderen bisher veröffentlichten Modell-basierten KIs.
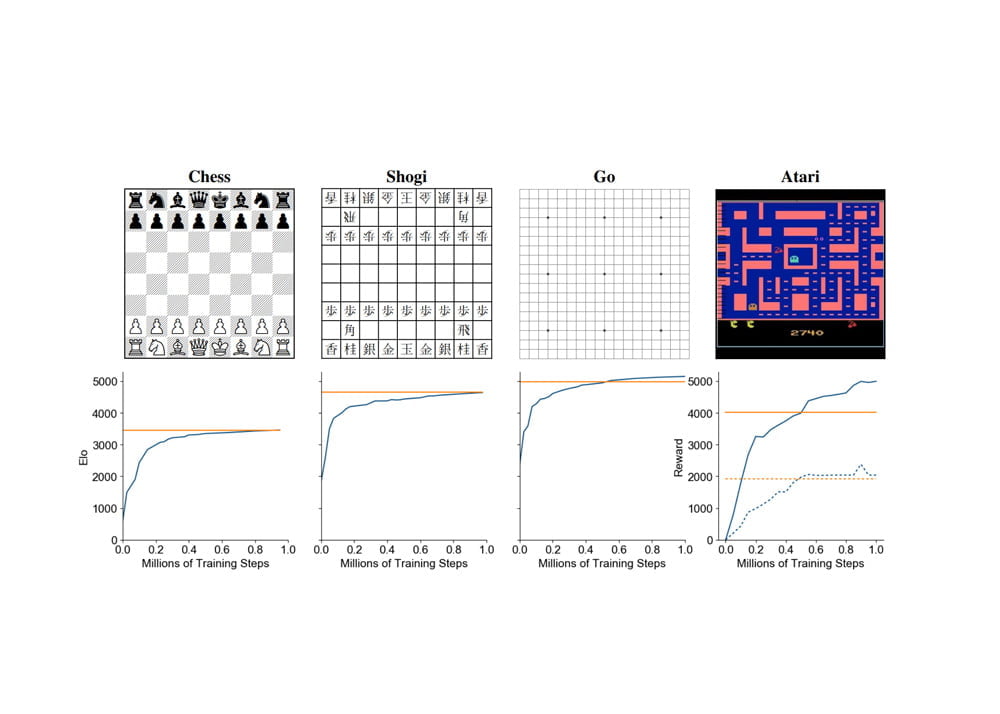
Deepmind schuf mit MuZero also eine KI, die Spielregeln selbstständig lernt und sich eigenständig ein Modell eines Spiels für die Planung erstellt – egal ob Brett- oder Videospiel. So lernt die KI, wie ihre Umgebung funktioniert und leitet daraus ihr Verhalten ab. Das macht sie flexibler als bisherige KIs.
MuZero könnte so Modell-basierten KIs den Weg ebnen, die in der echten Welt planungsintensive Aufgaben lösen, bei denen es für Menschen zu aufwendig oder sogar unmöglich ist, Modelle im Vorfeld zu definieren und vorzugeben. Ein mögliches Beispiel für so ein Szenario: der Straßenverkehr.
Quelle: Arxiv


