Deepminds "Vibe Checker" soll KI-Code nach menschlichem Geschmack beurteilen

Eine neue Studie zeigt, dass aktuelle Benchmarks die Qualität von KI-generiertem Code nur unzureichend bewerten. Vibe Checker bewertet neben funktionaler Korrektheit auch die Befolgung verifizierbarer Code‑Anweisungen; eine Kombination beider Metriken korreliert am besten mit menschlichen Präferenzen.
Das Kernproblem liegt laut den Forschenden von US-Universitäten und Google Deepmind in der Diskrepanz zwischen etablierten Benchmarks und der Realität interaktiver KI-Programmierung. Aktuelle Bewertungen fokussieren sich demnach ausschließlich auf pass@k-Metriken, die nur messen, ob Code Unit-Tests besteht. Dabei ignorieren sie die nicht-funktionalen Erwartungen, die Nutzer:innen bei der Code-Auswahl anwenden.
Besonders deutlich werde diese Lücke bei Copilot Arena, wo menschliche Programmierer:innen verschiedene KI-Modelle bewerten. Dort zeigen die Rankings eine schwache oder sogar negative Korrelation mit funktionalen Scores populärer Benchmarks.
VeriCode-Taxonomie schafft messbare Standards
Die Wissenschaftler:innen entwickelten zunächst VeriCode, eine Taxonomie von 30 überprüfbaren Code-Anweisungen in fünf Kategorien: Coding Style & Conventions, Logic & Code Patterns, Documentation & Commenting, Error Handling & Exception Management sowie Library & API Constraints.
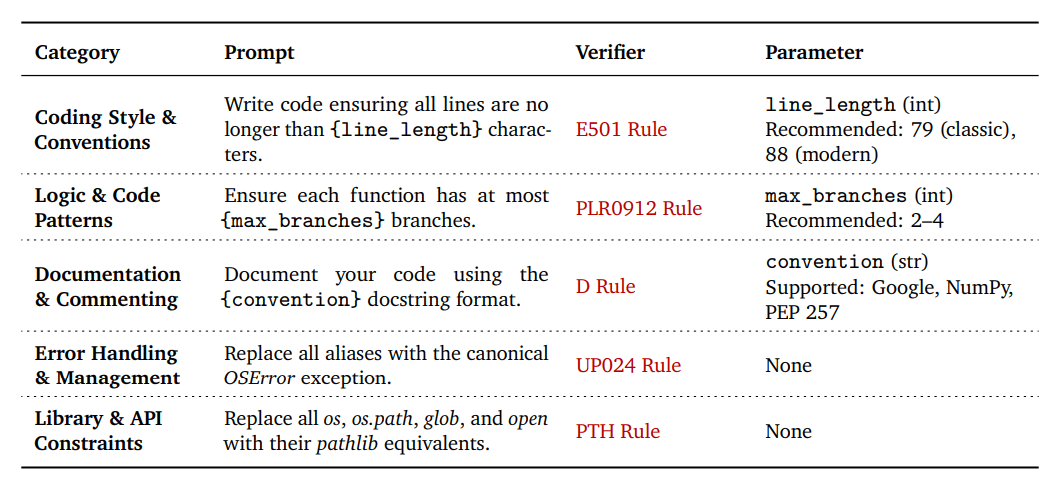
Die Taxonomie basiert auf über 800 Regeln aus dem industriellen Python-Linter Ruff. In einem mehrstufigen Filterprozess extrahierten die Forscher relevante und herausfordernde Anweisungen. Jede Anweisung erhielt einen deterministischen Verifikator, der eine binäre Pass/Fail-Bewertung liefert.
Ein entscheidender Vorteil der Taxonomie ist ihre Parametrisierbarkeit. Durch konfigurierbare Parameter wie Zeilenlänge oder maximale Funktionsverzweigungen lassen sich aus den 30 Kernanweisungen Hunderte Varianten mit unterschiedlichen Schwierigkeitsgraden generieren.
Vibe Checker erweitert etablierte Benchmarks
Basierend auf VeriCode entwickelten die Wissenschaftler das Vibe-Checker-Testbed. Es erweitert BigCodeBench zu BigVibeBench (1.140 Instanzen für reale Programmieraufgaben) und LiveCodeBench zu LiveVibeBench (1.055 Probleme für algorithmische Aufgaben).
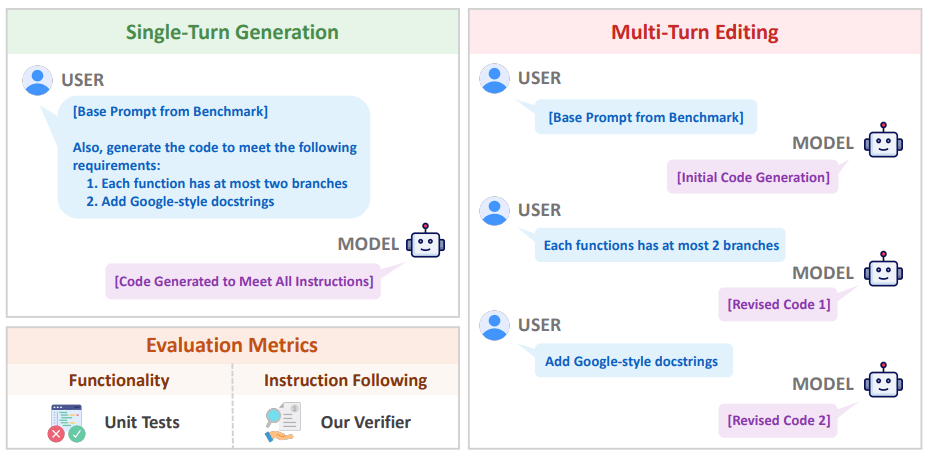
Ein LLM-basierter Selektor wählt für jede Programmieraufgabe passende Anweisungen aus der Sammlung aus, die zur Aufgabe passen und sich nicht widersprechen.Das System evaluiert in zwei Szenarien: Single-Turn-Generation, bei der alle Anweisungen auf einmal gegeben werden, und Multi-Turn-Editing, bei dem Anweisungen schrittweise eingeführt werden.
Überraschende Ergebnisse bei 31 führenden Modellen
Die Forschenden testeten 31 führende LLMs aus zehn Modellfamilien. Die Ergebnisse offenbaren mehrere Erkenntnisse: Obwohl die hinzugefügten Anweisungen nicht die Funktionalität betreffen, sinkt die pass@1-Rate bei allen Modellen. Bei fünf Anweisungen fällt der Durchschnitt um 5,85 Prozent auf BigVibeBench und 6,61 Prozent auf LiveVibeBench.
Das gleichzeitige Befolgen mehrerer Anweisungen bleibt also selbst für State-of-the-art-Modelle herausfordernd. Die besten Modelle erreichen nur 46,75 Prozent und 40,95 Prozent Erfolgsrate bei fünf Anweisungen. Mit drei oder mehr Anweisungen fallen die meisten fortgeschrittenen Modelle unter 50 Prozent auf beiden Benchmarks.
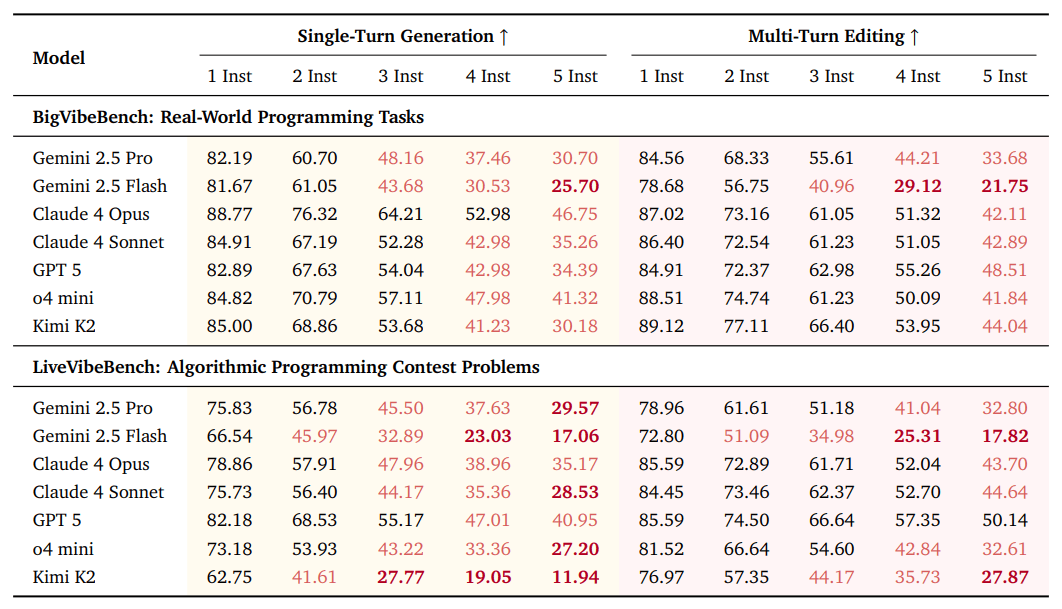
Die beiden Evaluierungsszenarien zeigen unterschiedliche Stärken: Single-Turn-Generation erhält die Funktionalität besser, während Multi-Turn-Editing erfolgreicher Anweisungen befolgt. Zusätzlich entdeckten die Forschenden einen Positionsbias: Modelle zeigen das "Lost-in-the-Middle"-Muster, bei dem mittlere Anweisungen weniger zuverlässig befolgt werden.
Mischung korreliert besser mit menschlichen Präferenzen
Den entscheidenden Nachweis liefert die Korrelationsanalyse mit menschlichen Präferenzen. Die Forschenden verglichen ihre Metriken mit über 800 000 menschlichen Bewertungen aus der Coding-Sektion von LMArena. Eine Mischung aus funktionaler Korrektheit und Instruction Following korreliert deutlich besser mit menschlichen Präferenzen als jede Metrik allein.
Besonders interessant ist die kontextabhängige Gewichtung: Bei praktischen Programmieraufgaben ist Instruction Following der primäre Differenziator zwischen fortgeschrittenen Modellen. Bei algorithmischen Wettbewerbsproblemen steht funktionale Korrektheit im Vordergrund.
Neue Richtung für KI-Entwicklung
Die Studie etabliert Instruction Following als essenziellen, aber bisher übersehenen Bestandteil der Code-Bewertung. Laut den Forschenden bietet die Berücksichtigung nicht-funktionaler Anforderungen einen starken Indikator für die Unterscheidung realer Nützlichkeit.
Die Erkenntnisse haben direkte Implikationen für das Training von KI-Modellen. Bisher dominiert pass@k als verifizierbares Belohnungssignal im RLVR-Training (Reinforcement Learning with Verifiable Rewards), was die Optimierung auf eine unvollständige Vorstellung von Code-Qualität lenkt. VeriCode könnte hier skalierbare und überprüfbare Belohnungsquellen liefern.
Die Forschenden planen, die VeriCode-Taxonomie und entsprechende Verifikatoren öffentlich verfügbar zu machen. Das Framework ist sprachagnostisch konzipiert und kann über Python hinaus auf andere Programmiersprachen erweitert werden.
Vor kurzem zeigten mehrere Studien die wachsende, aber komplexe Rolle von KI in der Softwareentwicklung. Eine Google-Cloud-Umfrage belegt die massive Adoption von KI-Tools bei Entwicklern, die diese täglich für mehrere Stunden nutzen. Auch die Stack-Overflow-Developer-Survey zeigt ein Vertrauensparadox: Während die Nutzung von KI-Tools weiter steigt, sinkt das Vertrauen in die Genauigkeit des generierten Codes. Eine Studie des Forschungsinstituts METR verstärkt diese Bedenken. Erfahrene Open-Source-Entwickler:innen benötigten mit KI-Assistenz länger für ihre Aufgaben, obwohl sie subjektiv glaubten, schneller zu arbeiten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.