Vor dem Start im Oktober zeigen Mitarbeitende von OpenAI und Nutzerinnen und Nutzer aus der Forschungsgemeinschaft Beispiele von DALL-E 3-Kreationen. Der Sprung zum Vorgängermodell ist gewaltig.
OpenAI führte DALL-E 3 mit dem Bild einer Avocado in einer Therapiesitzung ein, die ihrem Psychiater, einem Löffel, ihr Leid klagt: "Ich fühle mich so leer".

Natürlich hat OpenAI dieses Bild bewusst gewählt, denn es zeigt zwei neue Kernkompetenzen von DALL-E 3, die in bisherigen Text-zu-Bild-Systemen zu kurz kommen:
- DALL-E 3 kann schreiben und, was noch wichtiger ist,
- DALL-E 3 kann die Vorgaben eines Prompts exakt in ein Bild umsetzen.
Dank ChatGPT-Unterstützung schreibt sich DALL-E 3 diese Prompts sogar selbst. Alles, was es dazu benötigt, ist eine in Worte gefasste Bildidee des Benutzers. Das Ganze funktioniert so gut, dass OpenAI mit dem Launch von DALL-E 3 das viel beschworene "Prompt Engineering" zumindest für Bildsysteme für beendet erklärt, bevor es richtig begonnen hat.
Video: OpenAI
Eindrucksvolle DALL-E 3 Beispiele bei Twitter
Wer den Start von DALL-E 2 miterlebt hat, weiß, dass die Bildmaschine im Nachhinein überbewertet und schnell veraltet war. OpenAI hat zudem bei der Vorstellung von DALL-E 2 Beispiele ausgewählt, die besonders eindrucksvoll waren. Das ist natürlich legitimes Marketing. In der Praxis war es aber viel schwieriger, mit DALL-E 2 brauchbare Bilder zu generieren als beispielsweise mit Midjourney.
Wird das bei DALL-E 3 anders sein? Ja, wenn man sich die Beispiele anschaut, die erste OpenAI-Mitarbeitende und Nutzer mit DALL-E 3-Zugang auf der Plattform zeigen, die früher Twitter hieß. Sie geben zum Teil auf Zuruf anderer Nutzer Prompts ein und zeigen die Ergebnisse.
Wie ein roter Faden zieht sich die Detailverliebtheit von DALL-E 3 durch Beispiel-Bilder, die wohl auf das überlegene Textverständnis durch die Einbindung von GPT-4 zurückzuführen ist.
Im folgenden Beispiel gelingt es DALL-E 3, den Sturm, der durch das Fenster zu sehen ist, wie im Prompt gefordert in der Kaffeetasse wiederzugeben. Eine hochkomplexe Bildidee, die DALL-E 3 korrekt umsetzt.


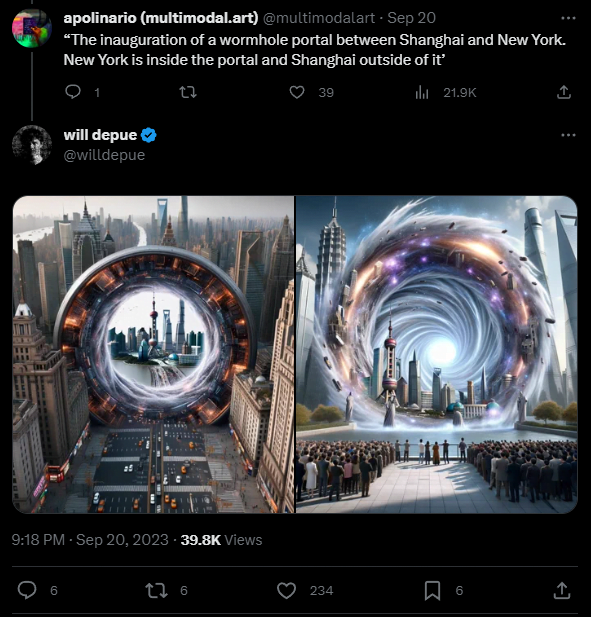
Ähnlich komplex ist das folgende Beispiel, bei dem man, wie im Prompt beschrieben, durch ein Wurmloch in New York auf die Stadt Shanghai blicken kann. Die Stadtkulissen zeigen typische Merkmale, die mit der Stadt in Verbindung gebracht werden, wie den Oriental Pearl Tower oder New Yorker Taxis.
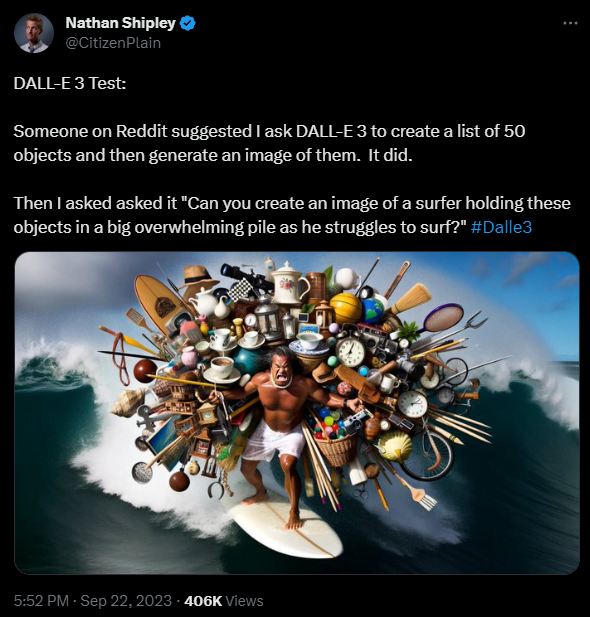
Mindestens ebenso eindrucksvoll ist die folgende Demonstration von Nathan Shipley. Er lässt DALL-E 3 zunächst eine Liste mit 50 Objekten erzeugen. Dann weist er DALL-E 3 an, zu zeigen, wie ein Surfer diese 50 Objekte auf dem Rücken trägt und dadurch Probleme beim Surfen hat.

Im folgenden Video zeigt Shipley, wie er mit DALL-E 3 zunächst die Idee eines wolkenförmigen Dackels visualisiert und daraus dann ein Logo, Merchandising und sogar eine Videospielverpackung ableitet.
Played around with DALL-E 3 this morning!
Here's a little screen capture of my how my "cloud made out of dogs" prompt evolved into... the Sky Dachshund franchise 🤣#Dalle3 @OpenAI pic.twitter.com/6OvN4nbtqs
— Nathan Shipley (@CitizenPlain) September 21, 2023
Auch der OpenAI-Forscher Will Depue zeigt zahlreiche DALL-E-3-Generierungen. Symbolisch ist das Pferd, das auf einem Astronauten reitet. Bisherige Bildsysteme konnten dieses ungewöhnliche Konzept ("Pferd reitet Mensch") nicht visualisieren. Stattdessen zeigten sie einen Astronauten auf einem Pferd oder einfach nur Unsinn.
Für KI-Kritiker war dies lange Zeit ein Beispiel für die mangelnde Generalisierungsfähigkeit und das fehlende Sprachverständnis von KI. Diese Kritik dürfte dank DALL-E 3 verstummen.
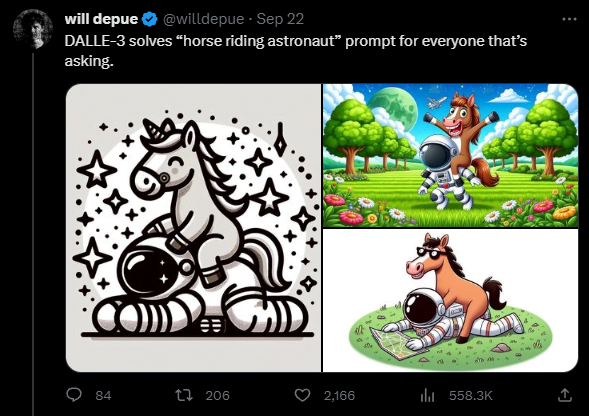

Laut Depue gelingt das anspruchsvolle Bild nicht unbedingt auf Anhieb. Aber mit zwei, drei Nachbesserungen könne man das Ziel zuverlässig erreichen. "Mit etwas Einsatz bekommt man fast alles, was man will", schreibt Depue.
Dank der ChatGPT-Unterstützung kann DALL-E 3 auch Lücken im Prompt selbst füllen. Im folgenden Beispiel fragt der Benutzer nach einer Comic-Szene mit zwei Zwiebeln, die sich unterhalten, und fordert einen witzigen Dialog, gibt aber nicht den genauen Text vor.
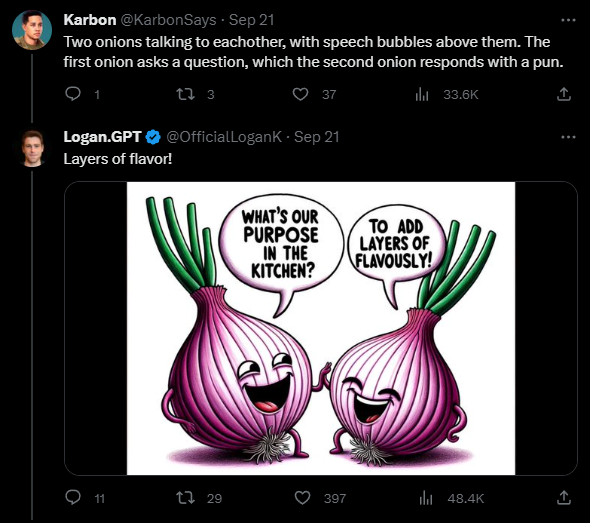
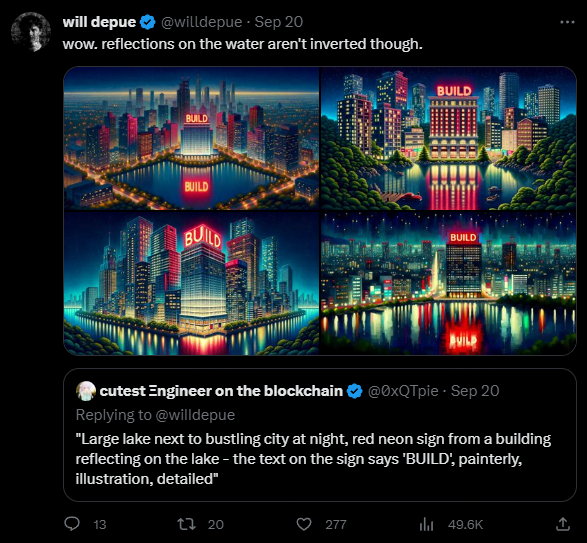
Sogar Spiegelungen beherrscht DALL-E 3, wenn auch (noch) nicht spiegelverkehrt. Depue arbeitet sich zudem spektakulär am Pepe-Meme ab.
OpenAI-Forscher Andrej Karpathy stellt einen neuen möglichen Arbeitsablauf für Content-Anbieter vor: Anhand einer Überschrift des Wall Street Journals lässt er DALL-E 3 ein Bild generieren, das er dann mit dem Video-Tool Pika Labs animiert. Er hält es für möglich, dass Nachrichten oder Geschichten mit solchen Arbeitsprozessen automatisch in audiovisuelle Formate umgewandelt werden können.
#randomfun playing with new genai toys
Go to WSJ, find random article
"The New Face of Nuclear Energy Is Miss America" [1]
Copy paste into DALLE-3 to create relevant visual
Copy paste into @pika_labs to animate
fun! 🙂 many ideas swirling
[1] https://t.co/sa4yDmVfyo pic.twitter.com/Pj3gEQgjD1— Andrej Karpathy (@karpathy) September 24, 2023
OpenAI hat sich bisher nicht zur Technik hinter DALL-E 3 geäußert. Vermutlich werden neu entwickelte Consistency Models anstelle der bisher verwendeten Diffusion Models zum Einsatz kommen. Sie ermöglichen schnelles Rendering, hohe Qualität und nachträgliche Bildbearbeitung.
Alles in allem sieht es so aus, als würde mit DALL-E 3 ab Oktober ein neuer Branchenprimus in Sachen Bildgenerierung auf den Markt kommen. Zwar sind die Bilder nicht perfekt, viele Beispiele zeigen KI-typische Ungenauigkeiten und Inkonsistenzen. Insgesamt ist der Qualitätssprung aber enorm.
Konkurrent Midjourney hat mit v6 ebenfalls einen großen Versionssprung in Arbeit, der insbesondere das Textverständnis des Modells verbessern und noch in diesem Jahr erscheinen soll.