
Alle generative KI-Modelle für Bilder nutzen aktuell Diffusionsmodelle, OpenAI zeigt eine Alternative, die deutlich schneller sein könnte.
DALL-E 2, Stable Diffusion oder Midjourney verwenden Diffusionsmodelle, die während der Bilderzeugung schrittweise ein Bild aus dem Rauschen synthetisieren. Das gleiche iterative Verfahren wird auch in Audio- oder Videomodellen verwendet.
Während Diffusionsmodelle deutlich bessere Ergebnisse liefern als GANs, sind sie vergleichsweise langsam und benötigen zwischen 10 und 2.000 Mal mehr Rechenleistung. Dies behindert ihren Einsatz in Echtzeitanwendungen.
OpenAI entwickelt daher eine neue Variante generativer KI-Modelle, die sogenannten "Consistency Models".
Consistency-Modelle sollen die Vorteile von Diffusionsmodellen und GANs vereinen
Consistency-Modelle unterstützen laut OpenAI eine schnelle, einstufige Bildsynthese, erlauben aber gleichzeitig auch eine mehrstufige Synthese, um beispielsweise mehr Rechenleistung gegen höhere Qualität zu ermöglichen. Consistency-Modelle können somit auch ohne iterativen Prozess zu brauchbaren Ergebnissen führen und sind für Echtzeitanwendungen geeignet.
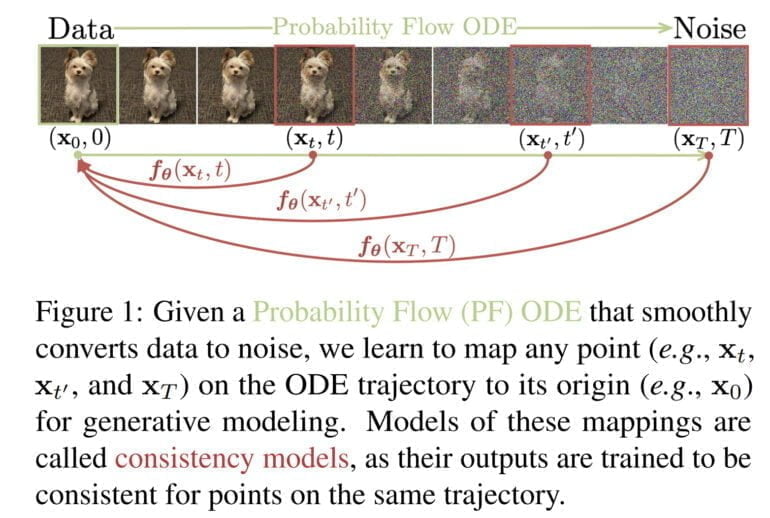
Wie Diffusionsmodelle können sie zudem Inhalte direkt bearbeiten, etwa für Inpainting, Kolorierung oder Super-Resolution-Aufgaben. Consistency-Modelle können entweder vortrainierte Diffusionsmodellen destillieren oder komplett eigenständig trainiert werden. Laut OpenAI hängen die Modelle Alternativen in der Destillation und in der One-Shot-Generierung (ausschließlich GANs) ab.

Das Unternehmen hat alle Tests mit relativ kleinen Netzen und Bilddatensätzen durchgeführt und beispielsweise ein Netz für die Synthese von Katzenbildern trainiert. Alle Modelle wurden von der Firma als Open Source für Forschungszwecke freigegeben.
Eine neue generative KI-Architektur für DALL-E 3 und Videosynthese?
Laut den Autor:innen gibt es auch auffallende Ähnlichkeiten zu anderen KI-Techniken, die in anderen Bereichen verwendet werden, wie zum Beispiel Deep Q-Learning aus dem Reinforcement Learning oder Momentum-basiertes kontrastives Lernen aus dem Semi-Supervised Learning. "Dies bietet interessante Perspektiven für den gegenseitigen Austausch von Ideen und Methoden zwischen diesen verschiedenen Domänen", so das Team.
In den Monaten vor der Veröffentlichung von DALL-E 2 hatte OpenAI mehrere Artikel über Diffusionsmodelle veröffentlicht und schließlich mit GLIDE damals extrem beeindruckendes Modell vorgestellt. Die Forschung an Konsistenzmodellen könnte also ein Hinweis darauf sein, dass OpenAI nach neuen und effektiveren generativen KI-Architekturen sucht, die beispielsweise ein deutlich schnelleres DALL-E 3 ermöglichen und für die Echtzeit-Videogenerierung eingesetzt werden können.

OpenAIs aktuelle Arbeit ist daher als Machbarkeitsstudie zu verstehen, ein größeres KI-Modell der wahrscheinlich nächste Schritt. Die gleiche Architektur könnte dann schließlich auch für andere Modalitäten oder für die Synthese von 3D-Inhalten verwendet werden.




