Drei Faktoren machen KI-Agenten deutlich intelligenter
Forschende identifizieren Datenqualität, Algorithmus-Design und Reasoning-Modi als Schlüssel für erfolgreiches KI-Training. Ein daraus entwickeltes 4-Milliarden-Parameter-Modell schlägt 32-Milliarden-Parameter-Konkurrenten.
Bisherige Trainingsmethoden für KI-Agenten führten oft zu instabilen Ergebnissen und ineffizientem Lernen, so das Team von der National University of Singapore, Princeton University und University of Illinois. Die Wissenschaftler:innen analysierten systematisch, warum aktuelle Reinforcement-Learning-Ansätze häufig versagen und wie sich dies beheben lässt.

Faktor 1: Datenqualität entscheidet über Erfolg
Der erste kritische Faktor betrifft die Art der Trainingsdaten. Die Forschenden verglichen echte Lernverläufe mit künstlich zusammengesetzten Beispielen, bei denen Denkschritte nachträglich durch Werkzeug-Ergebnisse ersetzt wurden.
Tests mit mathematischen Aufgaben in AIME-Benchmarks zeigten große Unterschiede. Mit echten Trainingsdaten erreichte ein 4-Milliarden-Parameter-Modell 29,79 Prozent Genauigkeit bei durchschnittlicher Leistung. Künstliche Daten erzielten dagegen weniger als 10 Prozent.
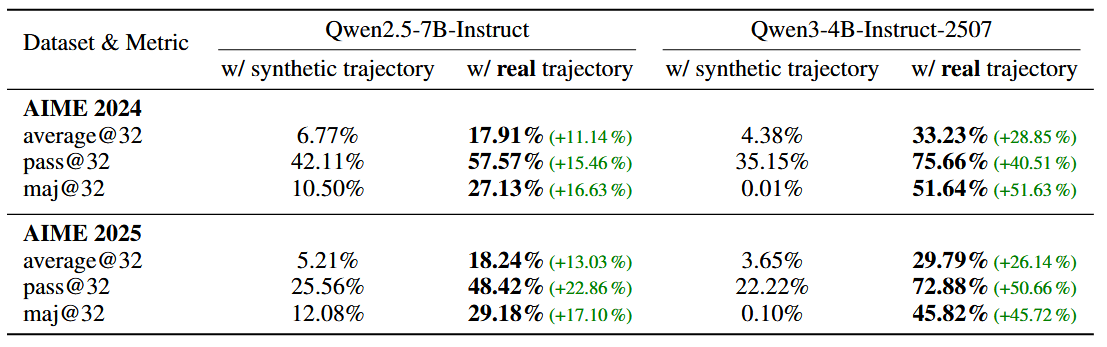
Echte Daten erfassen laut der Studie vollständige Denkprozesse: die Analyse vor Werkzeugaufruf, überwachte Ausführung, Fehlerkorrektur und Selbstreflexion. Künstliche Daten können diese natürlichen Verbindungen nicht nachbilden.
Die Vielfalt der Trainingsdaten erwies sich als ebenso wichtig. Ein gemischter Datensatz aus 30 000 Beispielen aus Mathematik, Wissenschaft und Programmierung beschleunigte das Lernen erheblich. Die KI erreichte 50 Prozent Genauigkeit bereits nach 150 Trainingsschritten, während ein rein mathematischer Datensatz 220 Schritte benötigte.
Faktor 2: Algorithmus-Design optimiert Lernprozess
Der zweite Faktor betrifft die Art der Leistungsoptimierung. Die Forschenden entwickelten drei verschiedene Varianten ihres Trainingsalgorithmus und verglichen deren Wirksamkeit systematisch.
Die erfolgreichste Variante kombiniert mehrere Verbesserungen: Token-basierte Bewertung (jeder Wortbaustein wird separat bewertet statt ganzer Sätze), erweiterte Clipping-Bereiche für mehr Exploration und eine spezielle Belohnungsstruktur gegen zu lange Antworten. Diese Kombination nennen die Wissenschaftler:innen GRPO-TCR.
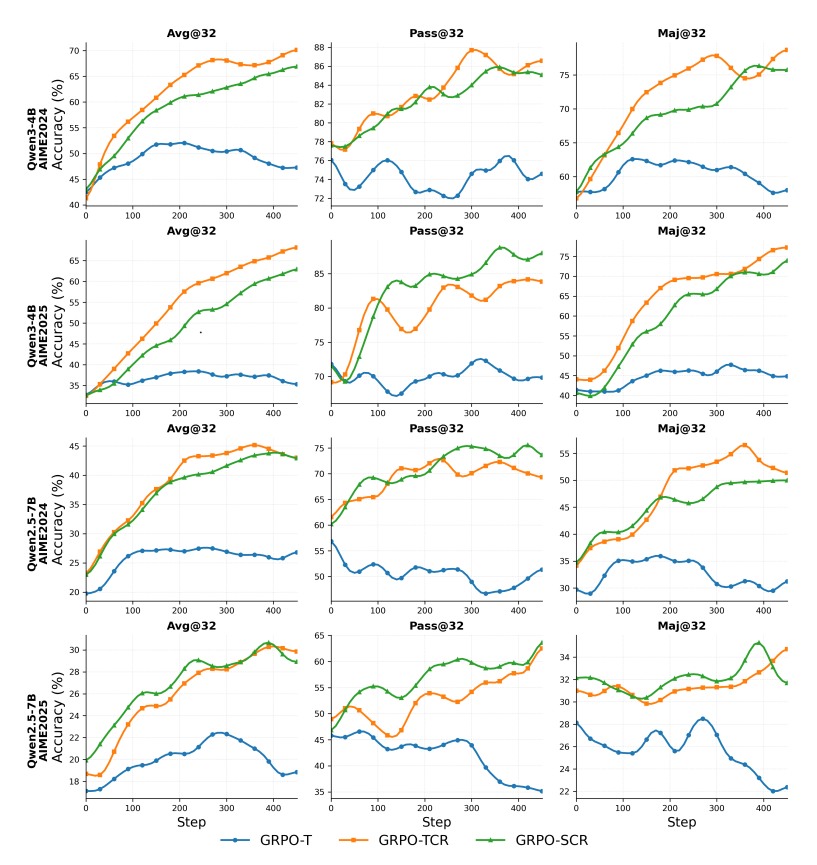
Mit diesem optimierten Verfahren erreichten sie 70,93 Prozent Genauigkeit auf einem mathematischen Benchmark und 68,13 Prozent auf einem anderen. Die Token-basierte Bewertung erwies sich als besonders wichtig und übertraf satzbasierte Methoden um etwa 4 Prozent, da jedes einzelne Wort gleichmäßig zum Lernfortschritt beiträgt.
Anders als bei herkömmlichem Reinforcement Learning können KI-Agenten durch Werkzeug-Interaktionen sowohl ihre Explorationsfähigkeit als auch ihre Präzision gleichzeitig verbessern. Dies ermöglicht stabileres und effektiveres Training.
Faktor 3: Denkweise bestimmt Effizienz
Der dritte entscheidende Faktor ist die Art, wie KI-Agenten ihre Denkprozesse organisieren. Die Forschenden identifizierten zwei grundlegend verschiedene Strategien: reaktives Verhalten mit kurzem Nachdenken und häufiger Werkzeug-Nutzung sowie überlegtes Vorgehen mit längerem Nachdenken und seltenerem Werkzeug-Einsatz.
Die leistungsstärksten Modelle bevorzugten durchweg die überlegte Strategie und erreichten über 70 Prozent Erfolgsrate bei der Werkzeug-Nutzung. Reaktive Modelle zeigten deutlich niedrigere Erfolgsraten, da ihre schnellen und häufigen Werkzeugaufrufe oft ineffektiv oder fehlerhaft waren.
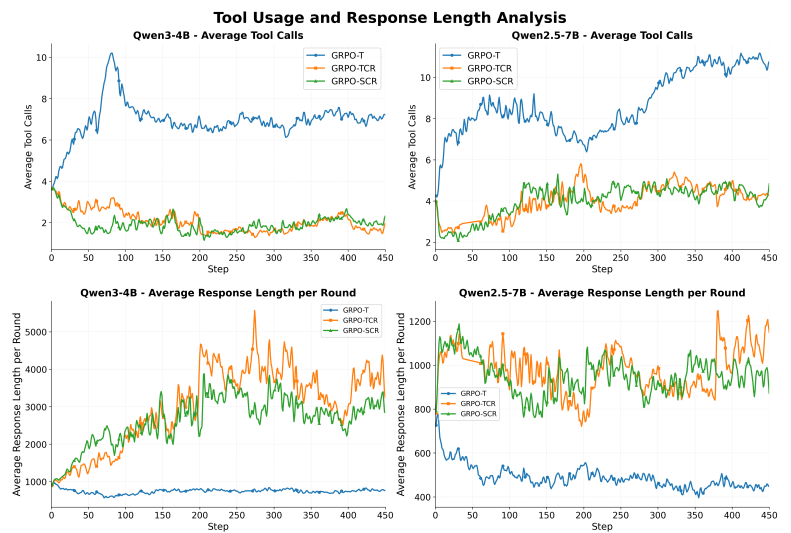
Die Wissenschaftler:innen schlussfolgern, dass Qualität wichtiger ist als Quantität: KI-Agenten, die mehr Zeit ins Nachdenken investieren, treffen letztlich bessere Entscheidungen beim Werkzeugeinsatz.
Interessant ist, dass aktuelle Long-Chain-of-Thought-Modelle, die für langes Nachdenken optimiert wurden, bei der Integration von Werkzeugen versagen. Sie neigen dazu, Werkzeugaufrufe ganz zu vermeiden und sich ausschließlich auf interne Denkprozesse zu verlassen.
Kompaktes Modell schlägt große Konkurrenten
Als praktische Anwendung ihrer Erkenntnisse entwickelten die Forschenden DemyAgent-4B mit nur 4 Milliarden Parametern. Das Modell erreichte 72,6 Prozent auf dem AIME2024-Mathematik-Benchmark, 70 Prozent auf AIME2025, 58,5 Prozent auf dem wissenschaftlichen GPQA-Diamond-Test und 26,8 Prozent beim Programmier-Benchmark LiveCodeBench-v6. Damit zeigte es eine Leistung, die mit deutlich größeren Modellen mit 14 bis 32 Milliarden Parametern konkurrieren kann und diese teilweise sogar übertrifft.
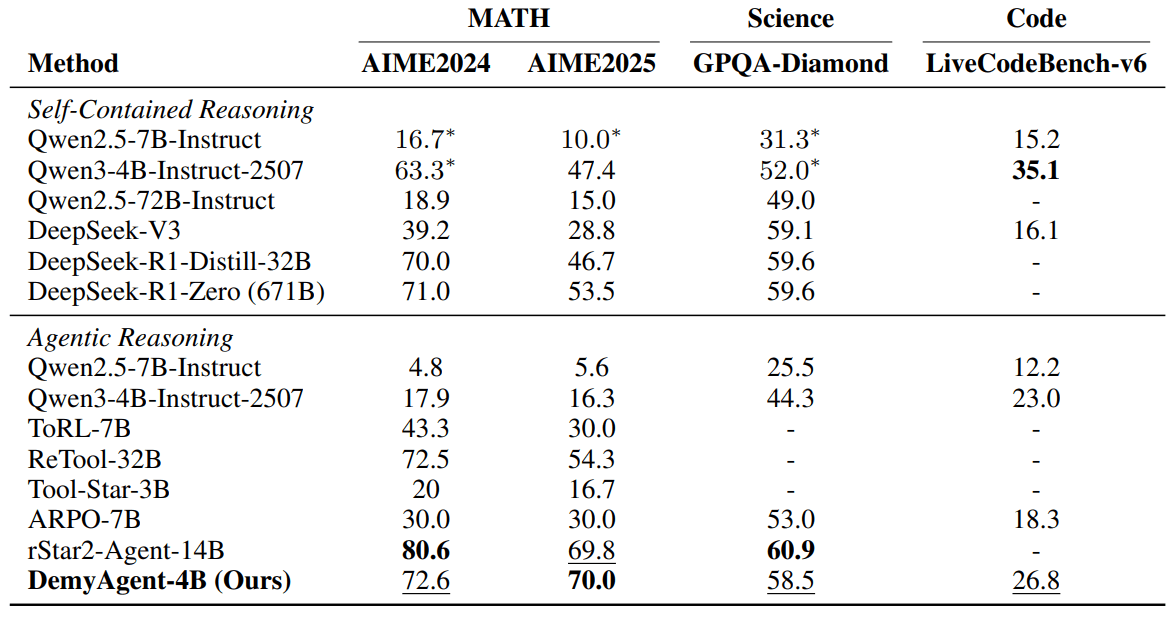
Die Forschenden stellen ihre Trainingsdaten und Modelle der wissenschaftlichen Gemeinschaft zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.