Ergebnisoffenheit ist der Schlüssel zur Super-KI, sagen Forscher von Google Deepmind

Die Fähigkeit, ergebnisoffen zu agieren, ist laut Forschern von Google Deepmind für die Entwicklung einer Super-KI von grundlegender Bedeutung.
In einem neuen Paper argumentieren Forscherinnen und Forscher von Google Deepmind, dass die Fähigkeit, sich ständig selbst zu verbessern, ein wesentliches Merkmal einer künstlichen Superintelligenz (Artificial Superintelligence, ASI) ist.
Nach Ansicht der Forscherinnen und Forscher reicht es nicht aus, immer größere Datensätze zu verwenden, um eine ASI zu erreichen. Sie beziehen sich damit auf aktuelle Skalierungsstrategien, die insbesondere auf die Faktoren mehr Rechenleistung und mehr Daten abzielen. Stattdessen müssen KI-Systeme in der Lage sein, selbst neues Wissen zu generieren und ihre Lernfähigkeit eigenständig zu verbessern.
Die Forscher definieren ein System als "open-ended", wenn es aus der Sicht eines Beobachters ständig neue und lernbare Artefakte erzeugt, die schwer vorherzusagen sind, auch wenn der Beobachter durch die Untersuchung vergangener Artefakte gelernt hat, diese besser vorherzusagen.
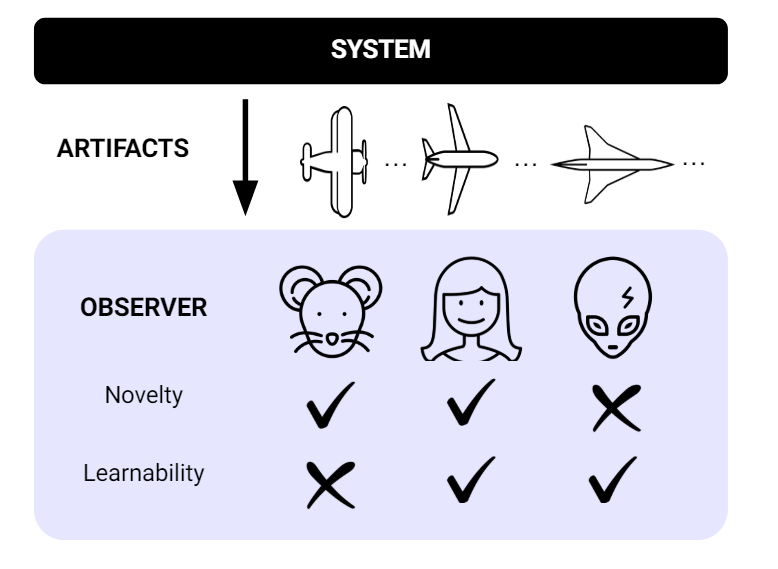
Die Forscher nennen einige Beispiele für offene Systeme und ihre Grenzen. AlphaGo könne immer wieder neue Strategien entwickeln, um selbst lernende Menschen zu schlagen - aber nur im Rahmen der von Menschen gemachten Regeln. Ein solches System sei daher trotz seiner Offenheit zu eng, um neue Wissenschaft oder Technologie zu entdecken.
Ein weiteres Beispiel ist der Agent "AdA", der Aufgaben in einer 3D-Umgebung mit Milliarden möglicher Varianten löst. Durch Training erwirbt AdA schrittweise Fähigkeiten für immer komplexere und unbekanntere Umgebungen.
Für menschliche Beobachter scheint das offen zu sein, da AdA ständig neue Fähigkeiten zeigen. Die Ergebnisse deuten jedoch darauf hin, dass die Neuartigkeit mit der Zeit ein Plateau erreicht und nur durch weitere Inhalte reaktiviert werden kann. Die Offenheit ist also zeitlich begrenzt.
Das POET-System trainiert Agenten, die jeweils an eine evolutionäre Umgebung gekoppelt sind. Durch periodischen Wechsel zwischen den Umgebungen lösen die Agenten schließlich hochkomplexe Aufgaben, die durch direkte Optimierung nicht lösbar wären.
Diese Offenheit wird allerdings durch die Parametrisierung der Umgebung selbst begrenzt: Irgendwann erreicht POET, ähnlich wie AdA, ein Plateau.
Foundation-Modelle auf Basis passiver Daten werden bald stagnieren
Im Gegensatz dazu seien aktuelle Foundation Modelle, wie die großen Sprachmodelle, nicht "open-ended". Da sie auf statischen Datensätzen trainiert werden, würden sie ab einem bestimmten Punkt keine neuen Artefakte mehr erzeugen. Sie würden bald ein Plateau erreichen, heißt es in dem Paper.
Sie könnten jedoch den Weg zu offenen Systemen ebnen, wenn sie kontinuierlich mit neuen Daten gefüttert und mit offenen Methoden wie Reinforcement Learning, Selbstverbesserung, automatischer Aufgabengenerierung und evolutionären Algorithmen kombiniert würden.
Foundation Models würden das Wissen der Menschheit zusammenführen und könnten so die Suche nach neuen relevanten Artefakten leiten, so die Forscher. Das mache sie potenziell zu einem Baustein für die Generalisierungsfähigkeit künstlicher Intelligenz.
"Wir sind der Meinung, dass Ergebnisoffenheit eine Eigenschaft jeder ASI ist und Grundlagenmodelle die fehlende Zutat für eine übergreifende Ergebnisoffenheit liefern. Darüber hinaus sind wir der Meinung, dass nur noch wenige Schritte notwendig sind, um Ergebnisoffenheit mit Hilfe der Grundlagenmodelle zu erreichen."
Aus dem Paper
Allerdings warnen die Wissenschaftler auch vor erheblichen Sicherheitsrisiken. Die ständig erzeugten Artefakte müssen für den Menschen nachvollziehbar und kontrollierbar bleiben. Sicherheitsüberlegungen müssen von Anfang an in die Entwicklung offener Systeme einfließen, um zu verhindern, dass eine künstliche Superintelligenz außer Kontrolle gerät.
Gelingt es jedoch, die Herausforderungen zu meistern, so die Hoffnung der Forscherinnen und Forscher, könnten ergebnisoffene Grundlagenmodelle zu einem Innovationsmotor werden, der bahnbrechende Durchbrüche in Wissenschaft und Technologie ermöglicht und die menschliche Kreativität in einer kollaborativen Feedbackschleife stärkt.
Der Mitbegründer von Deepmind, Demis Hassabis, deutete bereits vor einem Jahr an, dass Google Deepmind damit experimentiert, die Stärken von Systemen wie AlphaGo mit den Sprachfähigkeiten großer Modelle zu kombinieren. Das bisher veröffentlichte Gemini-Modell von Google bietet allerdings noch keine derartigen Fortschritte.
OpenAIs Q* soll ebenfalls Ideen, wie sie von Google Deepminds AlphaZero bekannt sind, mit Sprachmodellen verknüpfen - ähnlich dem, was Microsoft-Forscher kürzlich mit "Everything of Thoughts" gezeigt haben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.