
Q*, AGI und ein kurzfristig arbeitsloser CEO. Der Staub hat sich gelegt. Was wir über den vermeintlichen Durchbruch wissen.
Ein vermeintlicher KI-Durchbruch von OpenAI, bekannt als Q*, soll laut einem Bericht von Reuters intern Besorgnis über eine mögliche Bedrohung für die Menschheit hervorgerufen haben. Die Entdeckung ging der Entlassung des ehemaligen CEO von OpenAI, Sam Altman, voraus und war Teil einer Liste von Beschwerden, die dem Vorstand von besorgten Forschern vorgelegt wurden - so heißt es zumindest.
Während die genaue Natur von Q* unklar bleibt, tut das Internet das, was es am besten kann, und liefert alles von nüchternen Vermutungen bis hin zu wilden Spekulationen.
Warum ein Q* nötig wäre
Gegenwärtige KI-Technologien wie ChatGPT von OpenAI sind in der Lage, Muster zu erkennen, aus ihnen rudimentäre Schlüsse zu ziehen und Antworten zu generieren, die auf zuvor gesehenen Mustern basieren. Allerdings fehlen ihr viele Fähigkeiten, die wir als zentral für die menschliche Intelligenz ansehen, wie etwa mehr oder weniger fundiertes logisches Denken. Ein anschauliches Beispiel: Ein Experiment zeigte kürzlich, dass Sprachmodelle die einfache Formel "A ist B" nicht zu "B ist A" verallgemeinern können.
Berichten zufolge kann Q* einige mathematische Probleme lösen. Aktuelle große Sprachmodelle sind ziemlich schlecht in Mathematik und OpenAI verwendet daher externe Plugins wie Advanced Data Analytics, um die mathematischen Fähigkeiten von ChatGPT zu erweitern. Wichtiger für diese Geschichte ist jedoch ein Artikel, den das Unternehmen vor einigen Monaten veröffentlicht hat. Darin ist es einem Team des Unternehmens gelungen, die mathematischen Fähigkeiten der Sprachmodelle durch sogenanntes "Process Supervision" deutlich zu verbessern.
Die Prozessüberwachung ist eine Form des Reinforcement-Lernens, bei der das Modell für jeden Schritt seiner Argumentation ein menschliches Feedback erhält und so zu einer richtigen Antwort geführt wird. Dies steht im Gegensatz zur "Outcome Supervision", die für die RLHF in ChatGPT verwendet wird. Für die Prozessüberwachung können "Process-supervised Reward Models" (PRMs) verwendet werden, die vom menschlichen Feedback lernen. Der OpenAI-Forscher John Schulman erläuterte in einem Vortrag die zentrale Rolle dieser Prozesse.
Was Experten über Q* sagen
Was haben PRMs mit Q* zu tun? Sie könnten ein wichtiger Bestandteil des Systems sein, das nach der Meinung einiger Experten wahrscheinlich LLMs mit Planung kombiniert.

Neben Sprachmodellen setzt Q* wohl auf eine nicht linearer Methode zur Erforschung von "Gedanken", ähnlich zu Tree-of-Thoughts, Monte-Carlo Tree Search (MCTS), den oben erwähnten PRMs und einem Lernalgorithmus wie Q-learning. Nvidias Jim Fan erklärt die Details in einem ausführlichen Post auf Twitter.com.
Wenn die Vermutung stimmt, kombiniert Q* also Ideen, wie sie in AlphaZero gefunden wurden, mit Sprachmodellen - ähnlich dem, was Microsoft-Forscher kürzlich mit "Everything of Thoughts" gezeigt haben. Das Team von Microsoft erzielte bei Spielen wie "Game of 24" oder "8-Puzzle" beeindruckende Leistungen - aber keine hundertprozentige Zuverlässigkeit.
Dass eine solche Kombination grundsätzlich gute Ergebnisse verspricht, ist kein Geheimnis: Demis Hassabis, CEO von Google Deepmind, verriet in einem Interview, dass man Ideen von AlphaGo in Gemini einfließen lassen wolle.
Test-Time Compute und Brettspiele
Wie The Information berichtet, spielt ein weiteres Konzept dabei eine wichtige Rolle: "Test-Time Compute". Dabei geht es im Wesentlichen um die Rechenzeit, die einem System zur Verfügung steht, um eine Antwort zu finden. Von AlphaGo ist bekannt, dass es seine Leistung deutlich verbessert, wenn es mehr Zeit für die Baumsuche erhält. Eine systematische Untersuchung dieses Phänomens mit KI-Systemen, die Hex spielen, hat gezeigt, dass Trainingscompute und Inferenzcompute von MCTS in manchen Fällen fast eins zu eins ausgetauscht werden können.
Ein ähnliches Phänomen wurde bei der Poker-KI Libratus beobachtet. Noam Brown, einer der Autoren des Papiers, ist seit diesem Sommer bei OpenAI beschäftigt und hat auf Twitter.com einen Beitrag über die Bedeutung des Kompromisses zwischen Trainingszeit und Testzeit veröffentlicht.
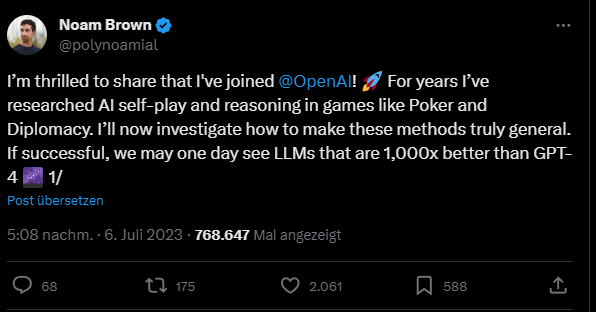
Er verspricht sich viel von einer Generalisierung solcher Methoden über Spiele hinaus.
"Alle bisherigen Methoden sind spezifisch für Spiele. Aber wenn wir eine allgemeine Version finden, könnte das enorme Vorteile bringen. Ja, die Inferenz könnte 1000 Mal langsamer und teurer sein, aber welche Inferenzkosten würden wir für ein neues Krebsmedikament bezahlen? Oder für einen Beweis der Riemannschen Hypothese?"
Mehr Informationen über Q*, Q-Learning und Spekulationen
Was auch immer Q* ist, es ist wahrscheinlich keine AGI und stellt vielleicht nicht einmal einen grundlegenden Durchbruch dar. Aber es ist wahrscheinlich ein Beispiel für die nächste Generation von KI-Systemen, die zuverlässiger sind und einige oder viele der Probleme heutiger Systeme wie ChatGPT lösen.
Auf weitere Antworten müssen wir warten, während die Interpretation der Q*-Gerüchte bereits Ausmaße angenommen hat, die eher an eine Silicon-Valley-Variante von Q-Anon erinnern, mit kurzen, aus dem Zusammenhang gerissenen Zitaten, der Interpretation emotionaler Zustände aus Videos und allgemeiner AGI-Exegese. Ein mutmaßlich gefälschter Brief, der Q* als gefährliches KI-System darstellt, das Verschlüsselungen knacken kann, existiert bereits.
Wer dennoch tiefer in das Thema eintauchen möchte, findet viele Artikel und Videos, die über Q* spekulieren. Forbes hat einen ausführlichen Artikel veröffentlicht, der auf viele Details der hier erwähnten Methoden und Konzepte eingeht. Der KI-Forscher Nathan Lambert hat einen der ersten Blogeinträge veröffentlicht, in dem er die Hypothese aufstellt, dass Q* Gedankenbäume und PRMs verwendet.
Einige relevante Videos:
CBCNews - kleiner Überblick inklusive eines Interviews mit dem KI-Forscher Yoshua Bengio.
Yannic Kilcher: Erläuterung von Q-Learning
AI Explained - DeepDive und einige Spekulationen über die Details von Q*.
Wer mehr über Reinforcement Learning, AGI und die Gefahren von Superintelligenz oder Sprachmodellen erfahren möchte, kann dies in unseren DEEP MINDS Podcast-Folgen #1 mit Tim Rocktäschel, Folge #4 mit Connor Leahy und Folge #5 mit Sebastian Riedel tun.





