Google: DataGemma soll Faktentreue in seinen Sprachmodellen erhöhen

Google hat DataGemma vorgestellt, eine Reihe von offenen Modellen, die darauf abzielen, die Genauigkeit und Zuverlässigkeit von großen Sprachmodellen zu verbessern, indem sie in realen Daten verankert werden.
Die Entwicklung von DataGemma ist laut Google eine Antwort auf die anhaltende Herausforderung der Halluzinationen in LLMs, bei denen KI-Modelle manchmal sehr überzeugend ungenaue Informationen präsentieren.
DataGemma nutzt Googles Informationsspeicher Data Commons, einen öffentlich zugänglichen Wissensgraphen, der über 240 Milliarden globale Datenpunkte aus geprüften Quellen wie den Vereinten Nationen, der Weltgesundheitsorganisation und verschiedenen Statistikämtern enthält.

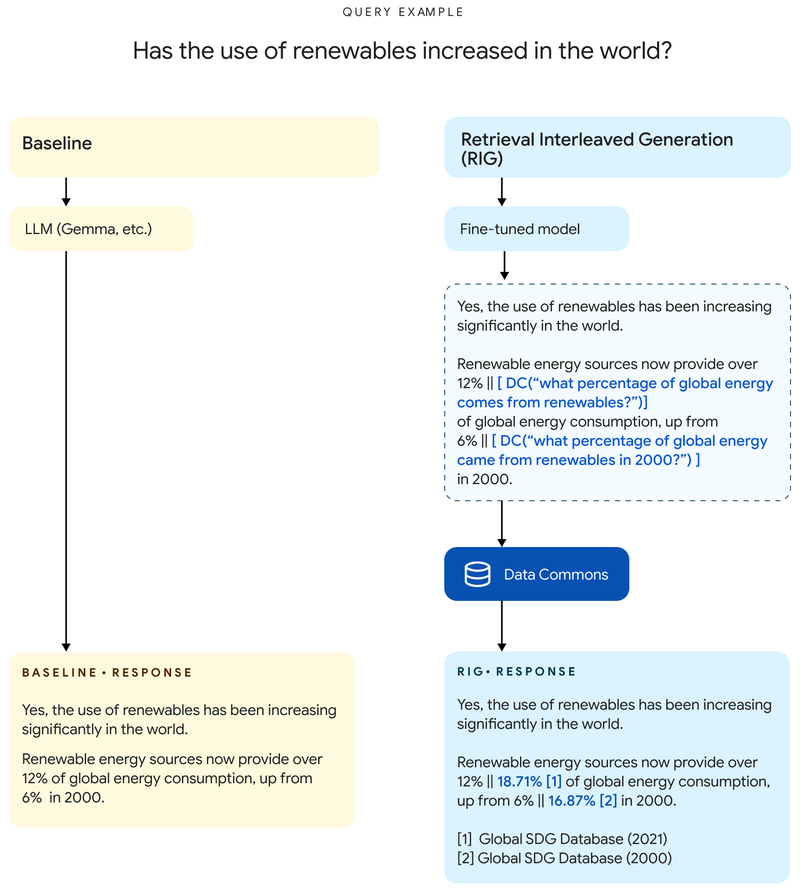
RIG erkennt Statistiken und prüft sie
Die Modelle unterscheiden sich hauptsächlich in zwei bereits bekannten Ansätzen: Retrieval Interleaved Generation (RIG) und Retrieval Augmented Generation (RAG).
RIG nutzt ein feinjustiertes Gemma-2-Modell, um Statistiken innerhalb seiner Antworten zu identifizieren und mit einem Abruf von Data Commons zu kombinieren, wodurch das Modell seine Ausgabe mit einer vertrauenswürdigen Quelle abgleichen kann.
"Anstelle der Aussage „Die Bevölkerung Kaliforniens beträgt 39 Millionen“ würde das Modell beispielsweise „Die Bevölkerung Kaliforniens beträgt [DC(Wie hoch ist die Bevölkerung Kaliforniens?) → ‚39 Millionen‘]“ ausgeben", erklärt Google.
RAG ruft relevante Informationen ab
Bei der RAG-Methode hingegen analysiert ein für diesen Anwendungsfall ebenfalls feinjustiertes Gemma-Modell zunächst die Nutzerfrage und bringt sie in die für Data Commons verständliche Form. Mit den aus dieser Abfrage gewonnenen Informationen wird die ursprüngliche Frage angereichert, bevor ein größeres Sprachmodell - etwa Gemini 1.5 Pro, wie Google vorschlägt - die finale Antwort generiert.
Herausforderung dieser Methode sei es, dass die von Data Commons zurückgegebenen Daten eine große Anzahl von Tabellen enthalten können, die sich über mehrere Jahre erstrecken. In Googles Test seien die Eingaben im Schnitt 38.000 Token und maximal 348.000 Token lang gewesen.
"Daher ist die Implementierung von RAG nur aufgrund des langen Kontextfensters von Gemini 1.5 Pro möglich, das es uns erlaubt, die Benutzerabfrage mit solch umfangreichen Data-Commons-Daten zu ergänzen", behauptet Google. Das Kontextfenster von Gemini 1.5 Pro fasst bis zu 1,5 Millionen Token, das nächstgrößere der kommerziell verfügbaren Sprachmodelle wäre Claude 3 mit 200.000.
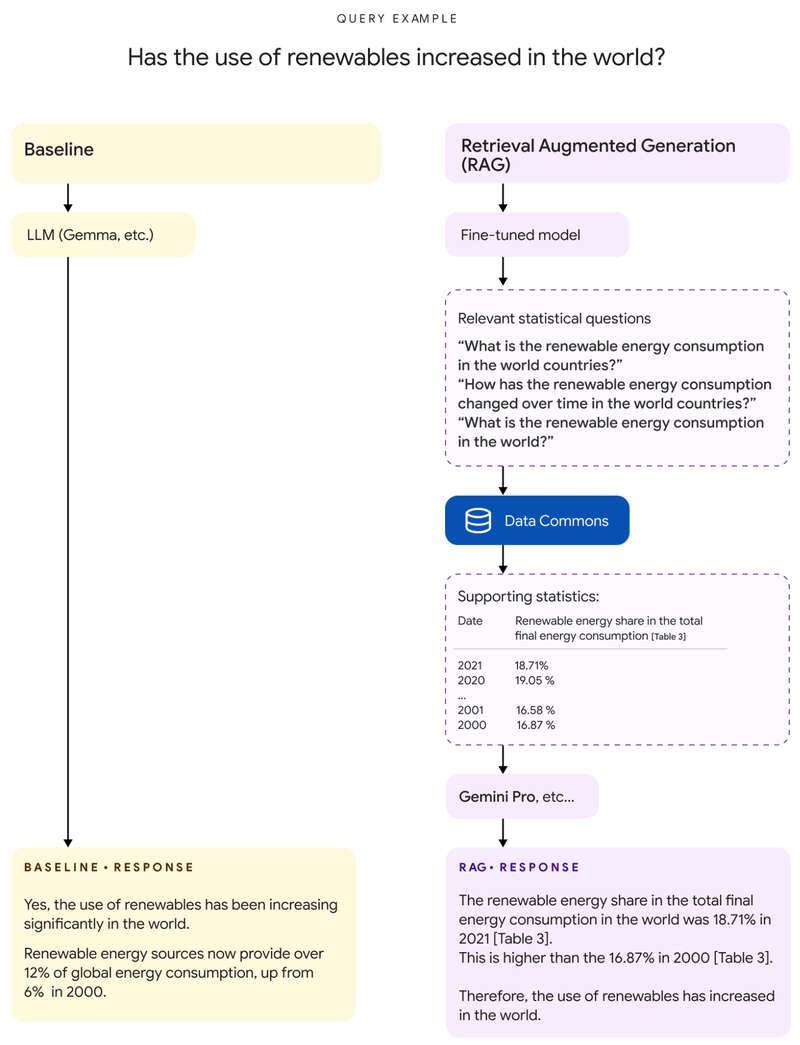
Bild: Google
Beide Ansätze haben Vor- und Nachteile
Beide Ansätze haben ihre eigenen Stärken und Schwächen. RIG funktioniert laut den Google-Forschenden in allen Kontexten effektiv, ermöglicht es dem LLM jedoch nicht, seit dem Finetuning hinzugekommene Daten von Data Commons zu lernen. Außerdem benötigt Finetuning spezielle Datensätze, die auf die jeweilige Aufgabe zugeschnitten sind.
RAG hingegen profitiert automatisch von der laufenden Entwicklung neuer Modelle, aber kann abhängig vom Nutzerprompt manchmal zu einer weniger intuitiven Benutzererfahrung führen.
Google hat die Modelle zum Download auf Hugging Face und Kaggle (RIG, RAG) bereitgestellt, zusammen mit Quickstart-Notebooks sowohl für den RIG- als auch den RAG-Ansatz.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.