Google Deepmind hat einen neuen KI-Fakten-Test, in dem Googles Gemini gewinnt
Google Deepmind stellt mit FACTS Grounding einen neuen Benchmark vor, der die Fähigkeit von KI-Modellen testet, faktenbasierte und detaillierte Antworten auf Basis von vorgegebenen Texten zu liefern.
Wie das Unternehmen mitteilt, umfasst der Test 1.719 sorgfältig ausgewählte Beispiele, bei denen KI-Modelle ausführliche Antworten auf Basis vorgegebener Dokumente generieren müssen.
Eine Besonderheit des Tests ist die Bewertungsmethode: Drei führende KI-Modelle - Gemini 1.5 Pro, GPT-4o und Claude 3.5 Sonnet - fungieren als Richter und bewerten die Antworten nach zwei Kriterien: Zunächst prüfen sie, ob die Antwort die Anfrage ausreichend beantwortet. Anschließend bewerten sie die faktische Korrektheit und ob die Antwort vollständig im bereitgestellten Dokument verankert ist.
Die Testdokumente decken laut Google Deepmind verschiedene Fachgebiete wie Finanzen, Technologie, Einzelhandel, Medizin und Recht ab. Sie können bis zu 32.000 Token (etwa 20.000 Wörter) lang sein.
Die Aufgaben reichen von Zusammenfassungen über Frage-Antwort-Generierung bis zu Umformulierungen. Sie wurden von Menschen erstellt und auf ihre Qualität geprüft, um sicherzustellen, dass sie keine kreativen Antworten, Expertenwissen oder mathematisches Verständnis erfordern.
Die Ergebnisse der verschiedenen Bewertungsmodelle werden zusammengeführt, um einen Gesamtscore für jede Antwort zu ermitteln. Der endgültige Score für die gesamte Aufgabe ist der Durchschnitt aller Bewertungsmodell-Scores über alle Beispiele. Ein FACTS Leaderboard stellt Google Deepmind bei Kaggle bereit.
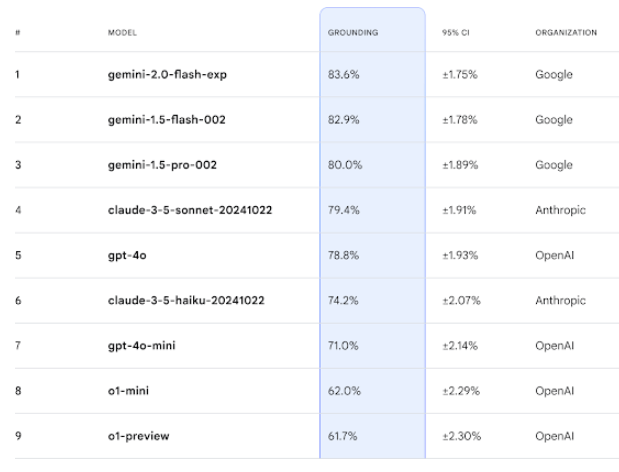
Öffentliche und private Testsets sollen vor Manipulation schützen
Um Manipulationen zu verhindern, teilt Google Deepmind den Benchmark in zwei Hälften: 860 öffentliche Beispiele stehen ab sofort zur Verfügung, während 859 Beispiele zurückgehalten werden. Die finale Bewertung basiert auf dem Durchschnitt beider Sets.
Das Unternehmen betont, dass der Benchmark kontinuierlich weiterentwickelt werden soll. "Faktentreue und Verankerung sind zentrale Faktoren für den künftigen Erfolg und Nutzen von Sprachmodellen und KI-Systemen", heißt es in der Ankündigung.
Der FACTS Grounding Benchmark unterscheidet sich deutlich von anderen Tests wie dem kürzlich vorgestellten SimpleQA von OpenAI. Während SimpleQA die Modelle mit 4.326 Wissensfragen testet, die sie aus ihrem Training beantworten müssen, prüft FACTS Grounding die Fähigkeit, neue Informationen aus bereitgestellten Dokumenten korrekt zu verarbeiten.
Im Kern geht es jedoch um das gleiche Ziel: Sprachmodelle zuverlässiger zu machen, um ihren Nutzen im Alltag zu erhöhen und sie für mehr Anwendungsszenarien nutzbar zu machen.
Dieses Problem erkennt auch Google Deepmind bei der Vorstellung von FACTS an. Große Sprachmodelle würden zwar die Art und Weise verändern, wie Menschen auf Informationen zugreifen. Aber ihre Kontrolle über die faktische Richtigkeit sei noch unvollkommen, insbesondere bei komplexen Eingaben könne es zu Halluzinationen kommen. Dies könne das Vertrauen in LLMs untergraben und ihre Einsatzmöglichkeiten einschränken.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.