Google veröffentlicht native Sprachmodell-Bildgenerierung für Gemini

Googles Gemini-Modelle sind von Grund auf multimodal trainiert, verstehen also auch Bilder - und können sie generieren. Das soll zu präziseren Bildausgaben führen als bei klassischen Bildmodellen.
Google macht die native Bildgenerierung in seinem Sprachmodell Gemini 2.0 Flash (gemini-2.0-flash-exp) für Entwickler zugänglich. Laut einem Blogbeitrag des Unternehmens können Entwickler die Funktion ab sofort über Google AI Studio und die Gemini API in allen unterstützten Regionen testen.
Die Bildgenerierung lässt sich über wenige Zeilen Code in Anwendungen integrieren. Google stellt dafür eine experimentelle Version von Gemini 2.0 Flash bereit.
Native LML-Generierung soll präziser und konsistenter sein
Das Besondere an Geminis Bildgenerierung ist der multimodale Ansatz: Das LML (Large Multimodal Model) kombiniert Textverstehen, verbessertes Reasoning und multimodale Eingaben, um präzisere Bilder zu erzeugen als klassische Bildgenerierungsmodelle.
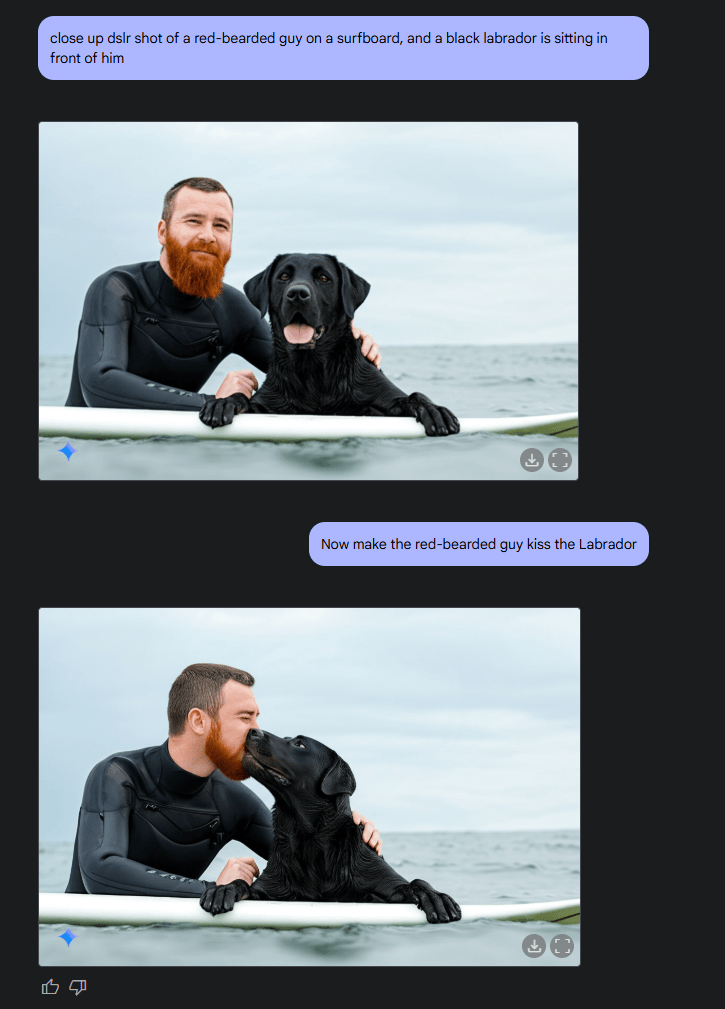

Google hebt vier zentrale Anwendungsfälle hervor: Erstens kann das Modell Text und Bilder für Storytelling kombinieren, wobei es Charaktere und Settings über mehrere Bilder hinweg konsistent darstellt.
Zweitens ermöglicht es konversationelle Bildbearbeitung über mehrere Dialogschritte. Dies eigne sich besonders für iterative Verbesserungen, wobei der Kontext über mehrere Gesprächsrunden hinweg erhalten bleibt.
Video: via Oriol Vinyals
Die dritte Stärke ist laut Google das dem LLM antrainierte Weltwissen, das helfen soll, realistische und akkurate Bilder zu erstellen - etwa für Rezeptillustrationen. Google betont jedoch, dass das Wissen des Modells breit, aber nicht absolut sei.
Als vierte Fähigkeit hebt Google die präzise Textdarstellung in Bildern hervor. Interne Benchmarks zeigen demnach bessere Ergebnisse bei der Textintegration als führende Wettbewerbsmodelle.
OpenAI könnte bald nachziehen
Bereits im Mai 2024 hatte OpenAI mit seinem GPT-4o-Modell ähnliche Bildgenerierungsfähigkeiten demonstriert. Damals zeigte OpenAI, dass GPT-4o, ebenfalls ein natives multimodales KI-Modell, das Text, Audio, Bild und Video als Eingabe verarbeiten und Text, Audio sowie Bilder ausgeben kann.
Zu den vorgeführten Fähigkeiten gehörten visuelle Erzählungen, detaillierte Charakterdesigns, kreative Typografie und realistische 3D-Renderings. Allerdings hat OpenAI diese Funktionen bislang nicht öffentlich verfügbar gemacht. Gerüchten zufolge könnte OpenAI, möglicherweise auch als Reaktion auf Googles Vorstoß, noch im März 2025 nachziehen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.