Googles Gemini 2.5 Pro schlägt OpenAI o3 beim Verständnis langer Texte
Googles Gemini 2.5 erzielt Bestwerte beim Fiction.Live-Benchmark für lange Textverarbeitung. Dennoch sind große Kontextfenster kein Selbstzweck.
Googles Gemini 2.5 Pro erzielt im Fiction.Live-Benchmark derzeit die besten Ergebnisse unter den getesteten KI-Modellen. Der Test prüft die Fähigkeit von Sprachmodellen, komplexe Geschichten und Zusammenhänge in langen Texten zu verstehen und korrekt wiederzugeben – eine realitätsnahe Anwendung, die über reine Suchfunktionen wie im häufig zitierten "Needle in the Haystack"-Test hinausgeht.
Laut dem Bericht erreicht OpenAIs aktuelles Modell o3 bis zu einem Kontextfenster von 128.000 Tokens (etwa 96.000 Wörter) vergleichbare Leistungen. Bei 192.000 Tokens fällt die Leistung jedoch deutlich ab. Das neue Gemini 2.5 Pro aus dem Juni (preview-06-05) bleibt hingegen stabil.
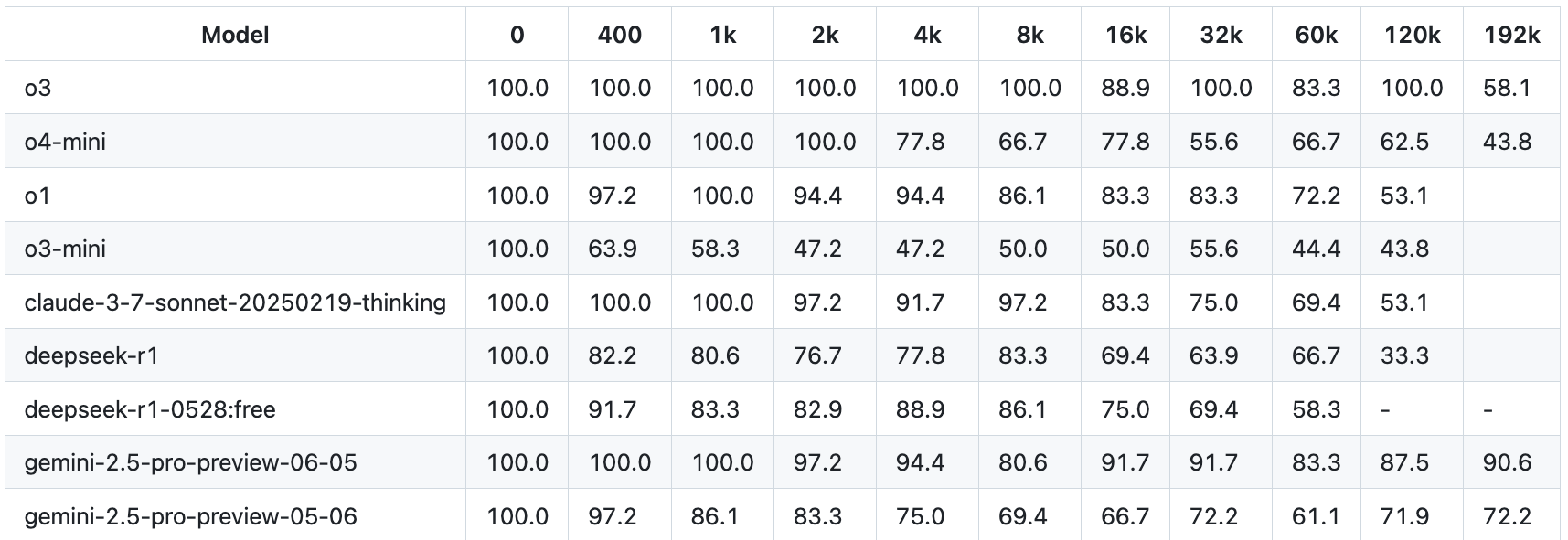
Die getestete Tokenzahl liegt allerdings noch weit unter der maximalen Kontextfenstergröße von einer Million Token liegt, die Google für Gemini 2.5 Pro angibt. Mit zunehmender Fenstergröße dürfte auch bei Gemini die Genauigkeit abnehmen.
Meta etwa bewirbt für Llama 4 Maverick eine Kontextfenstergröße von bis zu zehn Millionen Token. In der Praxis zeigt sich jedoch, dass das Modell bei komplexen Langkontext-Aufgaben kaum brauchbar ist, weil schlicht zu viele Informationen ignoriert werden.
Fokus statt Fülle: Deepmind-Forsher warnt vor überlangen Kontexten
Dennoch gilt auch bei wachsenden Kontextfenstern die alte Regel: Shit in, shit out. Nikolay Savinov von Google Deepmind erklärte kürzlich, dass Sprachmodelle bei vielen Tokens im Kontext mit einem grundlegenden Verteilungsproblem kämpfen: "Mehr Aufmerksamkeit für ein Token bedeutet automatisch weniger für andere."
Savinov empfiehlt daher, irrelevante Informationen möglichst nicht in den Kontext aufzunehmen. Zwar arbeite man daran, dieses Problem durch bessere Modelle zu beheben. Aktuell sei es jedoch effizienter, den Kontext bewusst zu wählen: "Man sollte einfach keine irrelevanten Kontexte einfügen", so Savinov.
Auch aktuelle Studien kommen zu dem Schluss, dass KI-Modelle beim Schlussfolgern in langen Kontexten noch Schwächen zeigen. In der Praxis bedeutet das: Selbst wenn ein Sprachmodell große Dokumente wie sehr umfangreiche PDFs akzeptiert, sollte man vorab irrelevante Seiten entfernen – etwa Einleitungen, die für die konkrete Aufgabe keine Rolle spielen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.