Googles ImageInWords könnte eine zentrale Schwachstelle von Midjourney & Co. beheben

Wenn KI und Mensch zusammenarbeiten, entstehen detailliertere und akkuratere Bildbeschreibungen. Die Methode könnte nicht nur Google, sondern die Branche im Ganzen nach vorne bringen.
Ein Forschungsteam von Google hat mit ImageInWords (IIW) ein System entwickelt, das Bildbeschreibungen auf ein neues Level heben soll. IIW kombiniert präzise Anleitungen für menschliche Mitarbeiter:innen mit einem schrittweisen Beschreibungsprozess. Das Ergebnis sind extrem detaillierte Bildbeschreibungen, die bisherige Ansätze in Benchmarks übertreffen.
Aktuelle KI-Systeme zur Bildverarbeitung werden oft mit riesigen Datenmengen trainiert, die aus dem Internet stammen. Diese Daten sind jedoch häufig ungenau und verwenden simple Alt-Texte anstelle von aussagekräftigen Bildbeschreibungen. Das schränkt die Fähigkeiten dieser Systeme ein.
Bisherige Versuche, hochwertigere Bildbeschreibungen zu erstellen, hatten ebenfalls Schwächen - egal ob die Beschreibungen von Menschen oder KI-Modellen erstellt wurden, weil sie etwa subjektive Verzerrungen oder Halluzinationen vorwiesen.
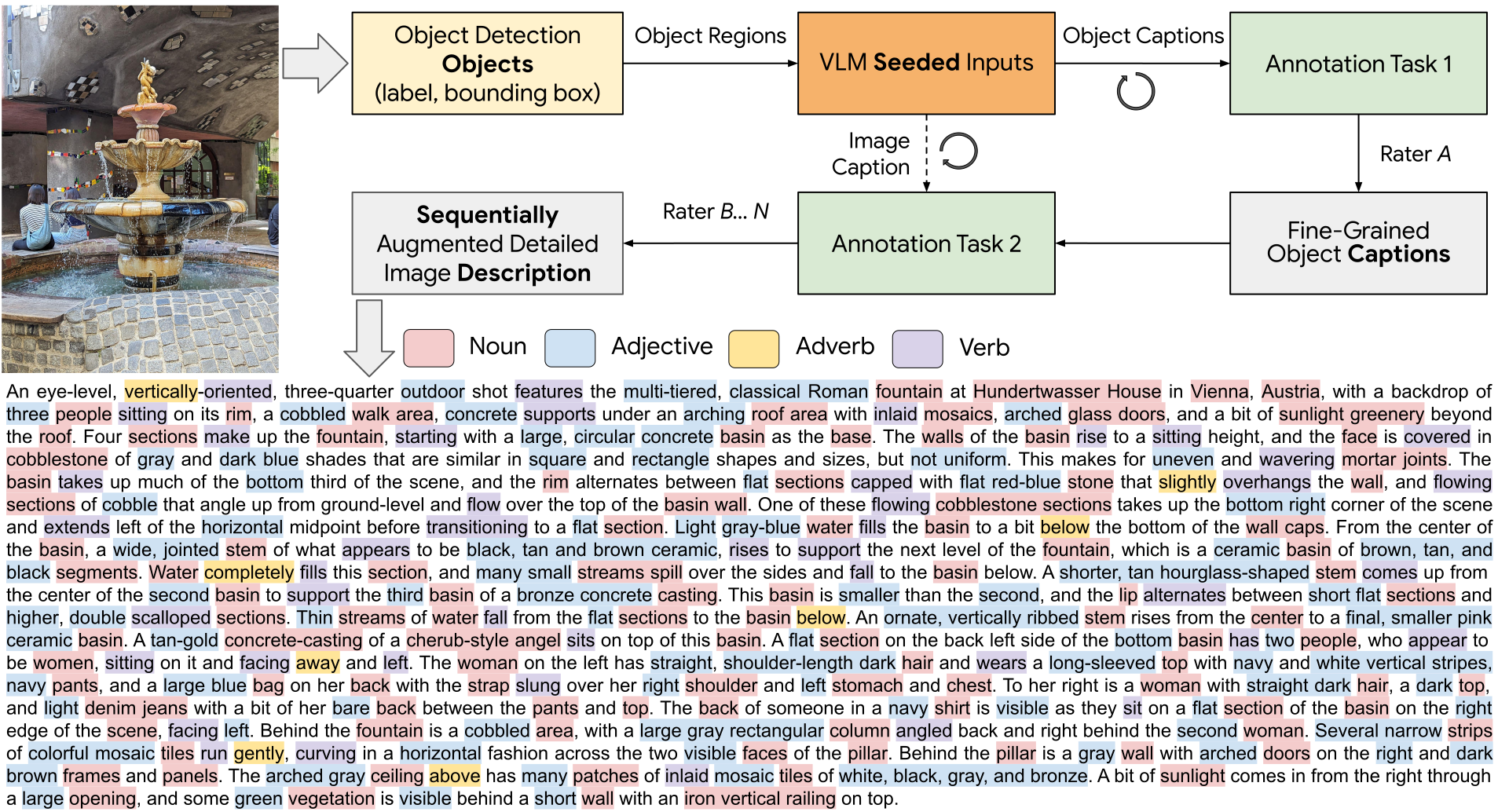
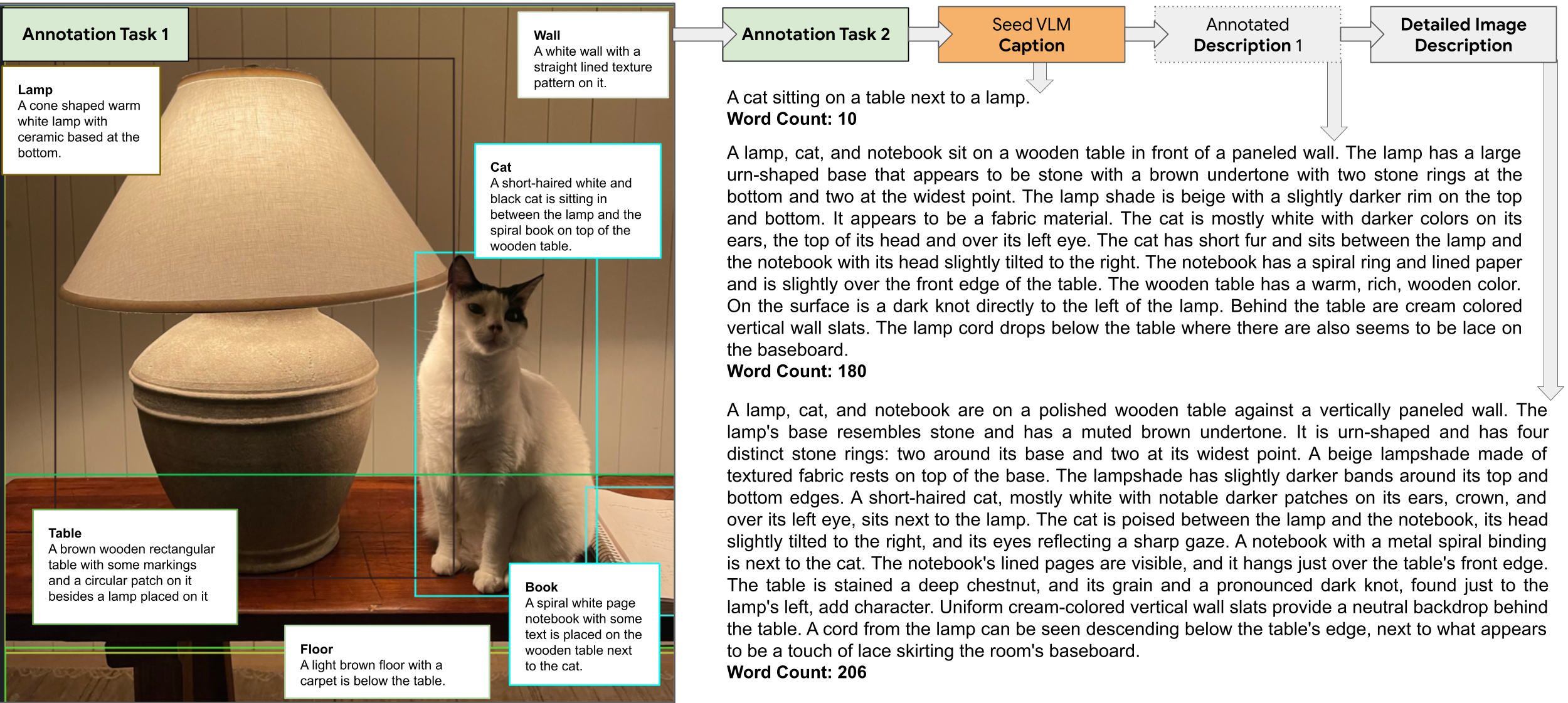
IIW geht diese Herausforderungen direkt an. Zunächst erkennt das System einzelne Objekte in einem Bild. Dann erstellt eine KI erste Beschreibungen für jedes Objekt. Diese dienen als Ausgangspunkt für menschliche Beschreiber:innen.
Menschen sollen Bild "wie einem Maler" beschreiben
Die menschlichen Beschreiber:innen verfeinern und erweitern die objektbezogenen Beschreibungen und sollen darauf achten, dass die Beschreibungen gleichzeitig umfassend und akkurat sind.
Die Kommentatoren werden gebeten, sich so zu verhalten, als ob sie einen Maler anweisen würden, mit ihren Worten zu malen, und nur die Details aufzunehmen, die sich aus den visuellen Anhaltspunkten ableiten lassen, wobei eine größere Genauigkeit anzustreben ist. Um flüssige und kohärente Beschreibungen zu verfassen, sollten unnötige Fragmentierungen von Sätzen vermieden werden; die Kommentatoren sollten die Verwendung von Füllwörtern wie "in diesem Bild", "wir können sehen", "es gibt ein" und "dies ist ein Bild von" vermeiden, da sie wortreich sind und keine visuellen Details hinzufügen.
Aus dem Paper
Der vollständige Leitfaden für die Beschreibungen findet sich im Anhang des Papers unter Kapitel 7.1 und umfasst mehrere Seiten. Unter anderem sollen die Mitarbeitenden auf diese Eigenschaften eines Bildes achten:
- Funktion: Zweck der Komponente oder die Rolle, die sie im Bild spielt
- Form: Spezifische geometrische Form, organisch oder abstrakt
- Größe: Groß, klein oder relative Größe zu anderen Objekten
- Farbe: Spezifische Farbe mit Nuancen wie einfarbig oder bunt
- Design/Muster: Einfarbig, Blumen oder geometrisch
- Textur: Glatt, rau, bucklig, glänzend oder matt
- Material: Holz, Metall, Glas oder Kunststoff
- Zustand: Gut, schlecht, alt, neu, beschädigt oder abgenutzt
- Opazität: Transparent, transluzent oder opak
- Ausrichtung: Aufrecht, horizontal, umgekehrt oder geneigt
- Ort: Vordergrund, Mittelgrund oder Hintergrund
- Beziehung zu anderen Komponenten: Interaktionen oder relative räumliche Anordnung
- Auf Objekten geschriebener Text: Wo und wie er geschrieben ist, Schriftart und ihre Eigenschaften, einzeilig/mehrzeilig oder mehrere einzelne Textstücke
Anschließend erstellt ein Vision Language Model eine Beschreibung für das gesamte Bild. Die Annotator:innen nutzen diese zusammen mit den objektbezogenen Beschreibungen, um eine vollständige und stimmige Bildbeschreibung zu erstellen.
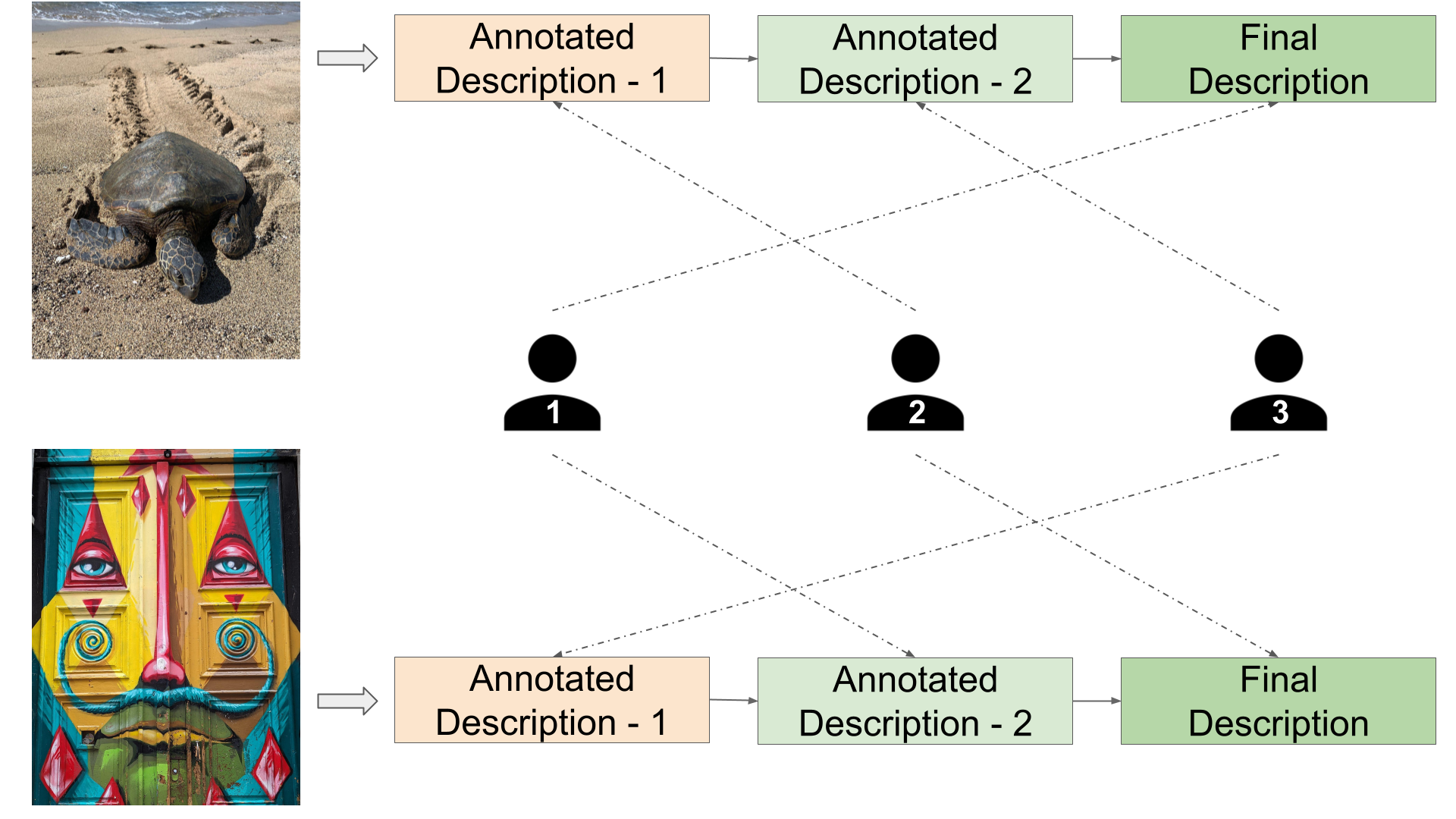
Die ersten KI-generierten Beschreibungen in IIW geben den menschlichen Beschreiber:innen einen Ausgangspunkt und beschleunigen den Prozess. IIW nutzt zudem einen schrittweisen Ansatz, bei dem die Annotator:innen auf vorherigen Beschreibungen aufbauen. Das führe zu hochwertigeren Ergebnissen in kürzerer Zeit.
Googles Methode schlägt andere in Tests sehr oft
Bei Tests mit nachgelagerten Aufgaben aus Prompts die Eingabebilder zu rekonstruieren, schnitt IIW unabhängig von der Beschreibungslänge in menschlichen Bewertungen am besten ab. IIW-Beschreibungen glänzten auch bei Aufgaben, die ein tieferes Verständnis der Bildinhalte erfordern. Sie enthielten die notwendigen Details, um echte von falschen Bildinformationen zu unterscheiden.

Google plant, IIW weiter zu verbessern, auf andere Sprachen auszuweiten und den Anteil menschlicher Arbeit zu reduzieren. IIW habe das Potenzial, verschiedenste KI-Anwendungen zu beeinflussen, von der Bildersuche über visuelle Frage-Antwort-Systeme bis hin zur Erstellung synthetischer Daten und damit der kontinuierlichen Verbesserung von Text-zu-Bild-Modellen.
Während aktuelle Technologien wie Midjourney v6, SDXL oder Firefly 3 schon Bilder in verblüffend hoher Qualität produzieren können, ist das sogenannte Prompt-Following, also wie genau das Modell die Texteingabe umsetzt, noch ein Bereich mit Optimierungspotenzial. IIW scheint ein wichtiger Baustein zu sein, von dem nicht nur Googles Software wie Imagen, sondern auch die anderer Unternehmen profitieren könnte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.