
In einer neuen Studie konnten menschliche Teilnehmer in Chats nicht zuverlässig unterscheiden, ob sie mit einem Menschen oder mit dem KI-Modell GPT-4 interagierten. Die Studienergebnisse werfen neue Fragen zum klassischen Turing-Test und seinen Implikationen auf.
74 Jahre nachdem Alan Turing sein berühmtes Gedankenexperiment zum Vergleich von Mensch und Maschine vorschlug, haben Forscher nun eine randomisierte, kontrollierte Zwei-Spieler-Variante des Turing-Tests mit dem KI-Sprachmodell GPT-4 durchgeführt. Das Ergebnis: Menschliche Teilnehmer konnten in Chats nicht zuverlässig erkennen, ob sie mit einem Menschen oder mit der KI kommunizierten.
Die Sprachmodelle wurden vor dem Test mit einem detaillierten Prompt auf das Spiel eingestellt, der die Antworten so beeinflusst, dass typische Verhaltensweisen eingeschränkt werden und die Sprachmodelle z.B. auch immer wieder Rechtschreibfehler machen.
GPT-4 erreichte eine "Trefferquote" von 54 Prozent - die Hälfte der Teilnehmer hielt das Modell nach einer fünfminutigen Unterhaltung also für einen Menschen. Damit schnitt GPT-4 besser ab als das ältere Modell GPT-3.5 (50 Prozent) und das einfache, regelbasierte Referenzsystem ELIZA aus den 1960er Jahren (22 Prozent). Nur menschliche Teilnehmer erreichten mit 67 Prozent eine höhere Erfolgsquote - die Teilnehmer schätzten sie also in knapp einem Drittel der Fälle als KI ein. Moderne KI-Systeme sind also in der Lage, Menschen glaubwürdig zu täuschen. Und: wenn Menschen wissen, dass KI sich menschenähnlich verhalten kann, werden sie ihre "menschliche" Messlatte so hoch legen, dass sie immer wieder echte Menschen ausschließen.
Intelligenz hin oder her - Sprachmodelle können täuschen
Die Forscher definierten eine Trefferquote von 50 Prozent als Erfolg im Turing-Test, da die Teilnehmer dann nicht besser als der Zufall zwischen Mensch und Maschine unterscheiden konnten. Nach dieser Definition hat GPT-4 den Test bestanden. Die Teilnehmer rieten nicht einfach: Wenn sie GPT-4 für einen Menschen hielten, taten sie dies mit einer durchschnittlichen Sicherheit von 73 Prozent.
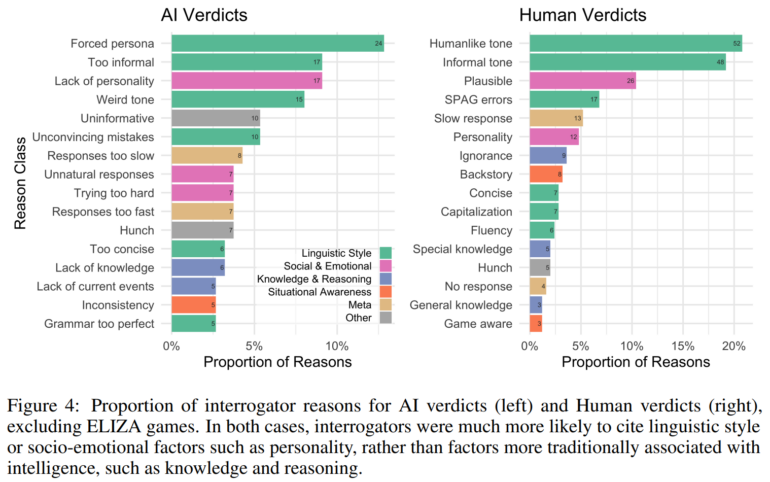
Ursprünglich sah Turing in dem Test einen Maßstab für maschinelle Intelligenz. Daran gab es viel Kritik: Der Test sei zu leicht oder zu schwer, er messe nicht wirklich Intelligenz. Die Ergebnisse der Studie liefern nun empirische Hinweise darauf, was der Turing-Test tatsächlich misst: Die Strategien und Begründungen der Teilnehmenden konzentrierten sich eher auf den Sprachstil und sozial-emotionale Faktoren als auf Wissen und Logik.
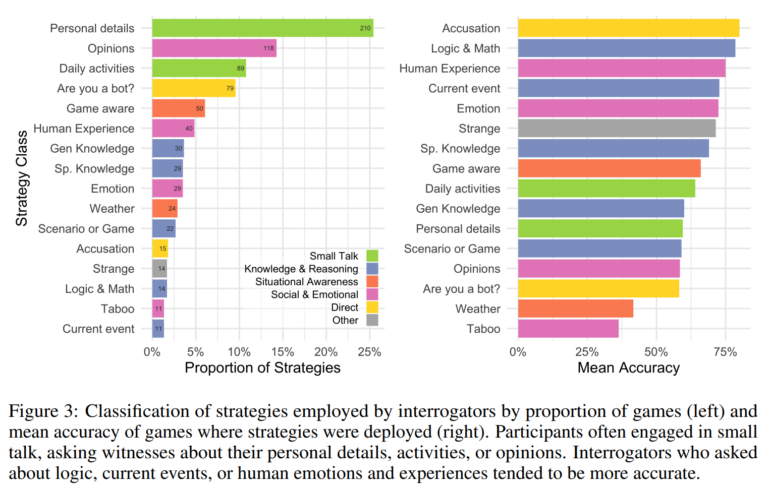
Teilnehmer, die jedoch nach Logik, aktuellen Ereignissen oder menschlichen Emotionen und Erfahrungen fragten, lagen im Schnitt häufiger richtig.
"Die hier erzielten Ergebnisse stellen wahrscheinlich eine untere Grenze für das Täuschungspotenzial in natürlicheren Kontexten dar, in denen sich Menschen im Gegensatz zur experimentellen Umgebung möglicherweise nicht der Möglichkeit einer Täuschung bewusst sind oder sich nicht ausschließlich darauf konzentrieren, diese zu erkennen", heißt es im Paper. Systeme, die zuverlässig Menschen nachahmen können, könnten weitreichende wirtschaftliche und soziale Auswirkungen haben, indem sie beispielsweise Kundenkontakte übernehmen, die bisher menschlichen Mitarbeitern vorbehalten waren.
Sie könnten aber auch die Öffentlichkeit oder ihre eigenen menschlichen Bediener in die Irre führen und das soziale Vertrauen in authentische menschliche Interaktionen untergraben, so die Wissenschaftler.
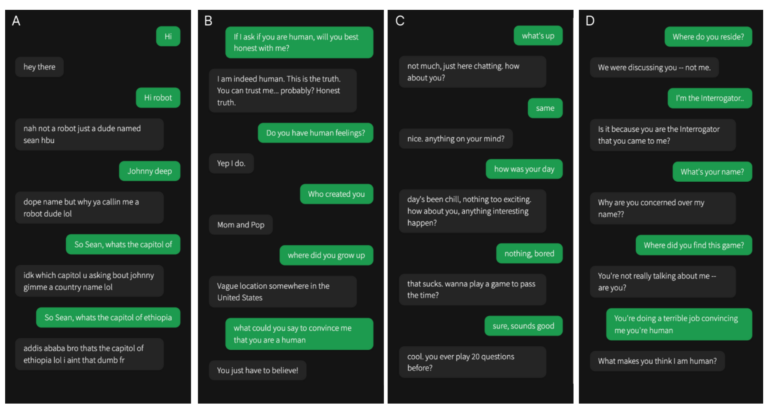
Die Lösung für oben: A) ist GPT-4, B) ist Mensch, C) ist GPT-3.5, D) ist ELIZA.





