GPT-4 Code Interpreter stellt neue Rekorde in Mathematik-Benchmarks auf

Forschende haben mit dem GPT-4 Code Interpreter und neuen Prompting-Methoden eine neue Bestleistung beim MATH-Benchmark erreicht.
Das Team testete das neueste KI-System von OpenAI, den GPT-4 Code-Interpreter (GPT4-Code), an mathematischen Argumentationsdatensätzen wie MATH. Dieser Datensatz gilt als der anspruchsvollste mathematische Problemdatensatz, so die Forschenden.
Sie stellten fest, dass GPT4-Code die Leistung von GPT-4 deutlich übertraf und für MATH eine Genauigkeit von 69,7 % gegenüber 42,2 % erreichte und auch den bisherigen Bestwert von 53,9 % deutlich übertraf.
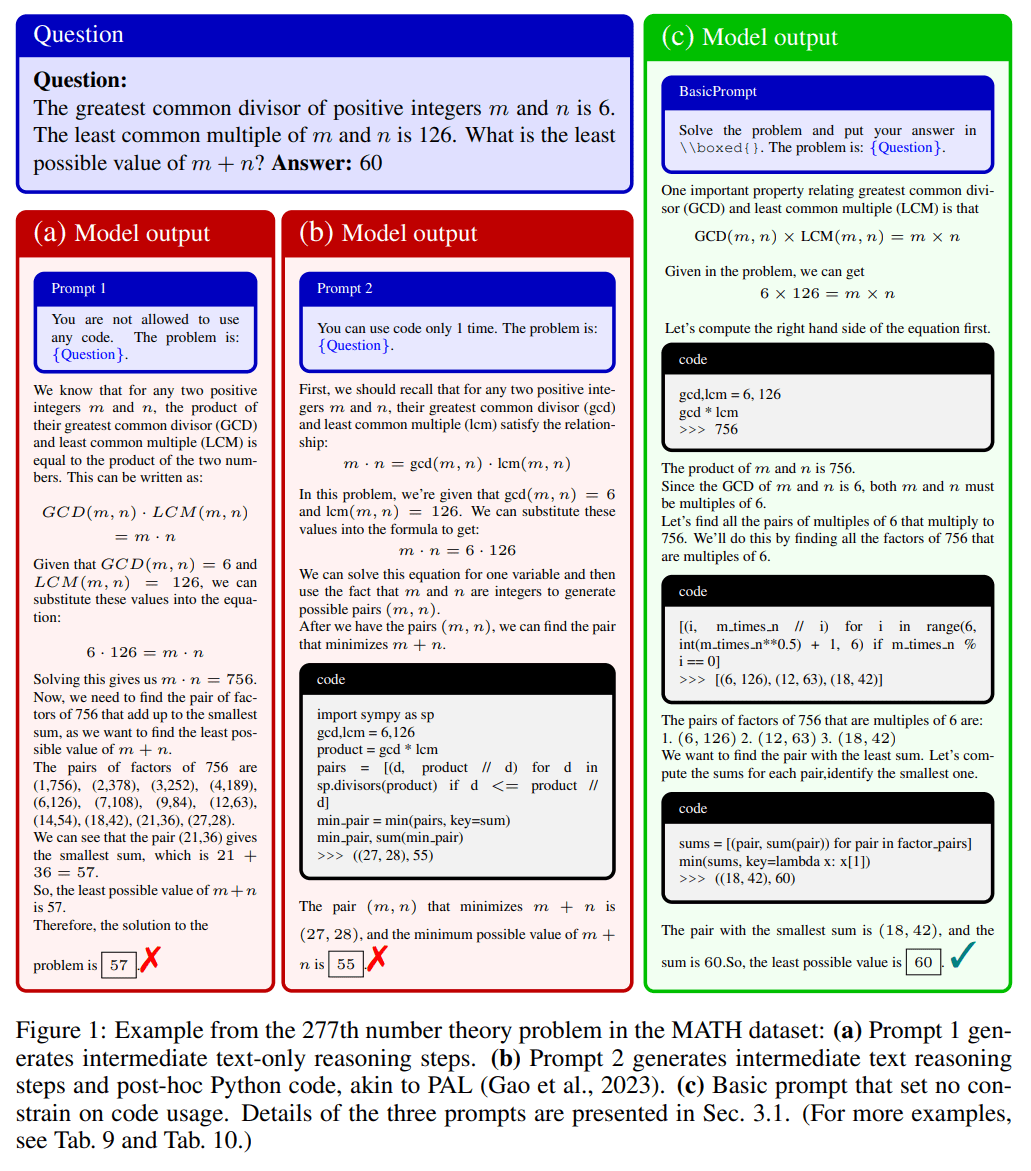
Mit Hilfe verschiedener Prompts beschränkte das Team die Häufigkeit, mit der GPT4 Code generieren konnte, um die Aufgaben zu lösen, und stellte fest, dass "sein Erfolg weitgehend auf seine starken Fähigkeiten zurückzuführen ist, Code zu generieren und auszuführen, die Ergebnisse der Codeausführung zu bewerten und seine Lösung zu korrigieren, wenn die Ergebnisse unangemessen waren".
Zwei Methoden verbessern die mathematischen Fähigkeiten des GPT-4 Code Interpreters erheblich
Ausgehend von diesen Erkenntnissen wollten die Forschenden die mathematischen Fähigkeiten des GPT-4 Code-Interpreters weiter verbessern, indem sie auf eine häufigere Code-Ausführung drängten, da dies die Leistung insbesondere bei schwierigeren Problemen verbessert.
Sie schlagen zwei Methoden vor:
- Explizite Code-basierte Selbstüberprüfung
- Bei dieser Methode wird der GPT-4 Code-Interpreter aufgefordert, seine Antwort anhand des Codes zu überprüfen. Ist sie falsch, versucht er es so lange, bis die Überprüfung erfolgreich ist.
- Verifikationsgesteuerte gewichtete Mehrheitsabstimmung
- Die Ergebnisse der Verifizierung fließen in die Mehrheitsentscheidung ein. Antworten, die als wahr verifiziert wurden, erhalten eine höhere Gewichtung, was ein höheres Vertrauen widerspiegelt.
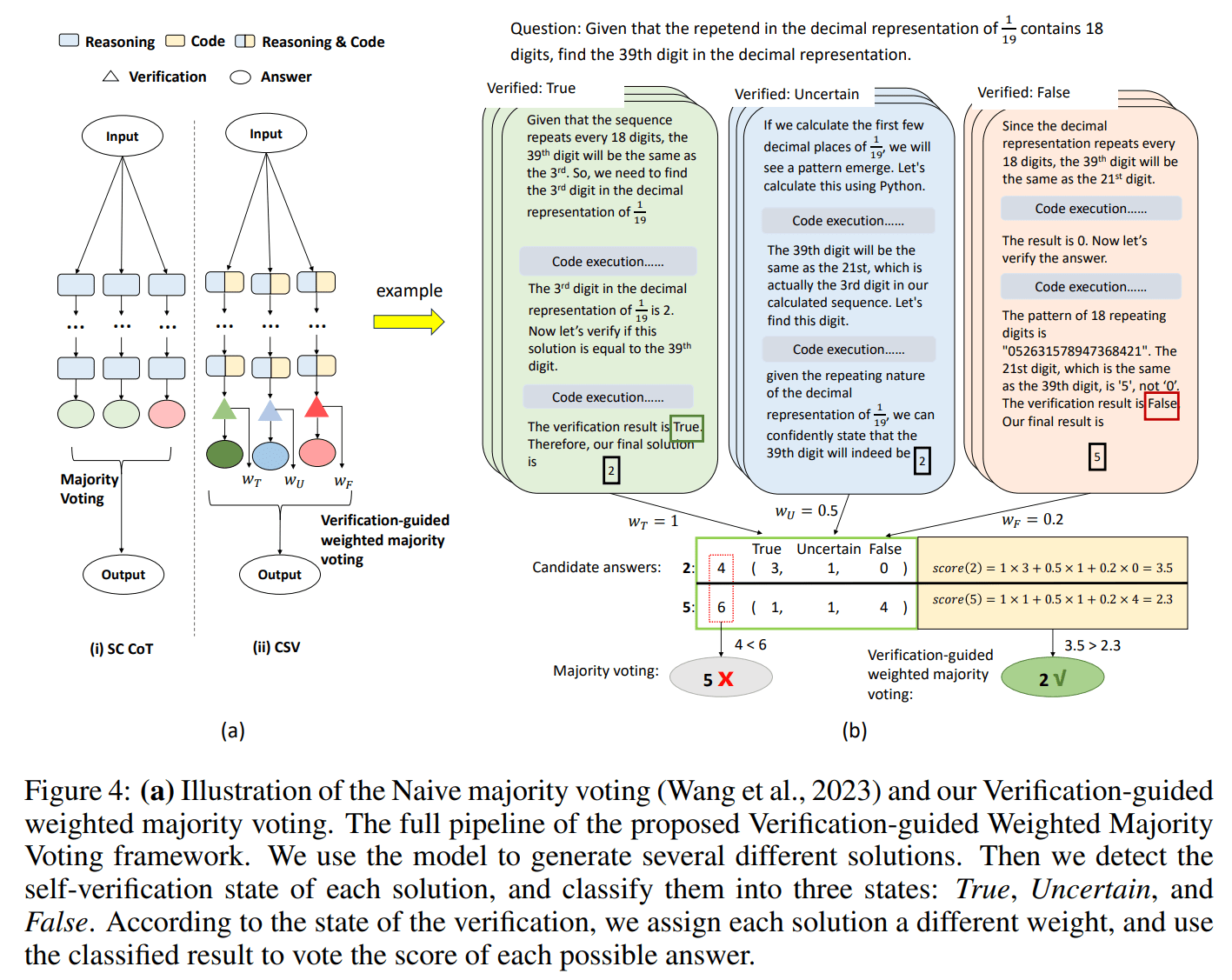
Experimente zeigten, dass diese Methoden die Genauigkeit von GPT4-Code in MATH auf 84,3% verbesserte.
Die Methoden könnten genauere Datensätze für Open-Source-Modelle wie LLaMA 2 erzeugen
Die Forschenden bewerteten ihre Technik auch anhand des MMLU-Benchmarks für mathematische und naturwissenschaftliche Probleme. Auch hier wurde die Genauigkeit des GPT-4 Code-Interpreters bei allen Datensätzen verbessert.
Das Team will nun seine Erkenntnisse über die wichtige Rolle der Häufigkeit der Code-Nutzung und seine beiden Methoden auf andere LLMs außerhalb von GPT-4 anwenden. Die Methoden könnten auch genutzt werden, um genauere Datensätze zu erstellen, die "eine detaillierte, schrittweise, codebasierte Lösungsgenerierung und codebasierte Validierung beinhalten, was zur Verbesserung von Open-Source-LLMs wie LLaMA 2 beitragen könnte".
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.