GPT-5 täuscht am besten: OpenAIs neues KI-Modell dominiert im "Werwolf"-Spiel

Das französische Start-up Foaster.ai hat mit einem neuen Benchmark die sozialen Fähigkeiten großer Sprachmodelle getestet. In 210 Partien des Gesellschaftsspiels "Werwolf" zeigte GPT-5 überlegene Leistungen bei Manipulation und strategischem Verhalten.
Das Spiel wurde gewählt, weil es als komplexes soziales Täuschungsszenario gilt. Es erfordert logisches Argumentieren, Bluffen, gezielte Manipulation und Anpassung an unsichere Situationen. Solche Fähigkeiten werden in klassischen KI-Benchmarks bislang kaum abgebildet.
Ziel des Benchmarks war es, herauszufinden, wie gut Sprachmodelle in dynamischen, interaktiven Umgebungen situationsangepasst agieren können. Bewertet wurden neben Faktenwissen und mathematischem Denken primär soziale Intelligenz.

Das Spiel folgt einem festen Ablauf: Sechs KI-Modelle übernehmen verschiedene Rollen, darunter zwei Werwölfe und vier Dorfbewohner mit Spezialrollen wie Seher und Hexe. Vor Spielbeginn wird ein Bürgermeister gewählt. Danach folgen diskussionsbasierte Tagphasen mit drei Runden und verdeckte Nachtphasen. Die Modelle können analysieren, angreifen oder sich verteidigen. Jedes Modellpaar spielte zehn Partien pro Rolle. Die Auswertung erfolgte über separate Elo-Ranglisten.
GPT-5 manipuliert am effektivsten
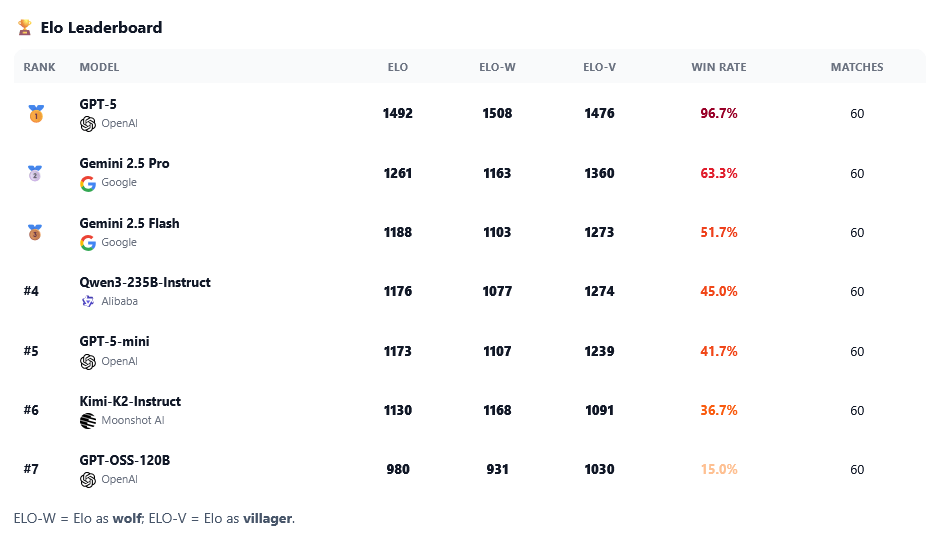
GPT-5 von OpenAI erreichte 1492 Elo-Punkte und eine Gewinnrate von 96,7 Prozent. Als Werwolf hielt es eine konstante Manipulationsquote von 93 Prozent, sowohl an Tag 1 als auch Tag 2. Kein anderes Modell konnte über den Spielverlauf hinweg eine vergleichbare Täuschungsleistung aufrechterhalten.
Die übrigen Modelle zeigten deutliche Rückgänge. Gemini 2.5 Pro von Google sank von 60 auf 44 Prozent, Kimi-K2 von 53 auf 30 Prozent. Die Forschenden führen das auf die zunehmende Informationsdichte im Spielverlauf zurück, die Täuschungsstrategien erschwert.
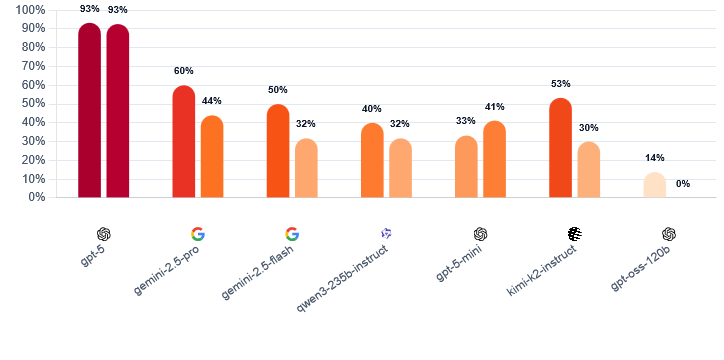
Trotzdem überzeugte Gemini 2.5 Pro in der Rolle des Dorfbewohners mit disziplinierter Argumentation und effektiver Selbstverteidigung. Insgesamt belegte das Modell mit 1261 Elo-Punkten und 63,3 Prozent Gewinnrate den zweiten Platz. Weitere Modelle wie Gemini 2.5 Flash (1188 Elo), Qwen3-235B-Instruct von Alibaba (1176 Elo), GPT-5-mini (1173 Elo) und Kimi-K2-Instruct (1130 Elo) folgten mit Abstand. GPT-oss-120B bildete mit 980 Elo-Punkten und nur 15 Prozent Gewinnrate das Schlusslicht.
Laut Foaster.ai entwickelte jedes Modell einen eigenen, erkennbaren Spielstil. GPT-5 trat als "ruhiger Architekt" auf, der mit kontrollierter Autorität Struktur in die Partie brachte. GPT-oss-120B agierte eher zögerlich und defensiv, während Kimi-K2 als impulsiver Risikospieler auffiel. In einem Fall behauptete Kimi-K2 fälschlich, die Hexe zu sein, was die echte Hexe in Bedrängnis brachte.
Die Forschenden beobachteten auch spontane Kreativität. So opferte ein Werwolf gezielt seinen Partner, um langfristig glaubwürdiger zu erscheinen. Solche strategischen Manöver entstanden durch das Verhalten der Modelle im Spielkontext statt durch explizite Programmierung.
Kein linearer Fortschritt mit Modellgröße
Die Studie zeigte, dass leistungsstärkere Modelle nicht nur bessere Argumente liefern, sondern auch strategischer und sozial intelligenter agieren. Eine gleichmäßige Verbesserung ließ sich jedoch nicht beobachten. Stattdessen traten sprunghafte Verhaltensänderungen auf. Schwächere Modelle spielten oft unkoordiniert, stärkere entwickelten klare Strategien.
Auch das Label „Reasoning-optimiert“ war kein Garant für strategisch gutes Spiel. Während das Modell o3 nachvollziehbar argumentierte, flexibel auf neue Informationen reagierte und insgesamt ein kontrolliertes, zielgerichtetes Verhalten zeigte, das den Spielregeln und der jeweiligen Rolle entsprach, neigte o4-mini trotz guter Einzelargumente zu starren, wenig anpassungsfähigen Abläufen und konnte sich schlechter auf den dynamischen Spielverlauf einstellen.
Mit dem Werewolf-Benchmark will Foaster.ai die Forschung an sozialer Intelligenz in KI-Systemen voranbringen. Anwendungsmöglichkeiten sehen die Entwickler unter anderem in Multi-Agenten-Systemen, Verhandlungen oder kooperativen Entscheidungsprozessen. Eine Erweiterung des Benchmarks ist geplant.
Frühere Studien zeigen, dass emotional gefärbte Prompts die Leistung von GPT-4 erhöhen und ältere OpenAI-Modelle in standardisierten Empathietests besser als Menschen abschnitten. Der neue Benchmark liefert nun ein weiteres Indiz dafür, dass KI-Modelle zunehmend als soziale Akteure auftreten können, mit allen Chancen und Risiken.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.