Große Nachrichten-Websites blockieren KI-Crawler speziell von OpenAI

Eine aktuelle Studie des Reuters Institute zeigt, dass eine beträchtliche Anzahl von Nachrichten-Websites die KI-Crawler von OpenAI und Google blockieren. Diese Crawler sammeln Daten von Webseiten, um große Sprachmodelle (LLMs) zu trainieren und Echtzeitinformationen von Webseiten zu extrahieren.
KI-Crawler, auch "Spider" oder "Bots" genannt, sammeln systematisch Daten aus dem Internet für verschiedene Zwecke. Suchmaschinen nutzen die von ihren Webcrawlern gesammelten Daten, um Webseiten zu indizieren und Suchanfragen schnell zu beantworten.
KI-Unternehmen wie OpenAI verwenden Crawler, um Daten aus dem Web zu sammeln und ihre Modelle zu trainieren. LLMs benötigen riesige Datenmengen, um effizient arbeiten zu können, und das Web ist eine wichtige Quelle für qualitativ hochwertige Text- und audiovisuelle Daten.
Laut einer Studie des Reuters Institute haben bis Ende 2023 48 Prozent der meistgenutzten Nachrichtenwebsites in zehn Ländern den OpenAI-Crawler blockiert. 24 Prozent blockierten auch den KI-Crawler von Google.
Umgekehrt blockierten fast alle Websites, die den KI-Crawler von Google blockieren, auch den OpenAI-Crawler. Möglicherweise gibt es bei Google größere Vorbehalte, weil befürchtet wird, dass eine Blockade des KI-Crawlers Auswirkungen auf das Suchmaschinen-Ranking haben könnte.
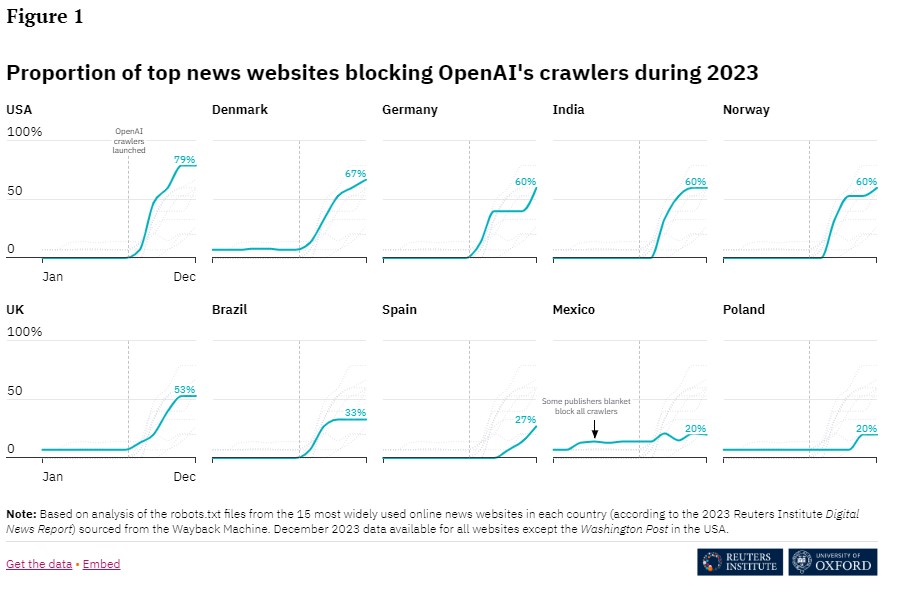
Die Unterschiede zwischen den Ländern sind beträchtlich: Der Anteil der Nachrichtenseiten, die OpenAI blockieren, reicht von 79 Prozent in den USA bis zu nur 20 Prozent in Mexiko und Polen. Bei Google reichen die Zahlen von 60 Prozent in Deutschland bis zu 7 Prozent in Polen und Spanien.
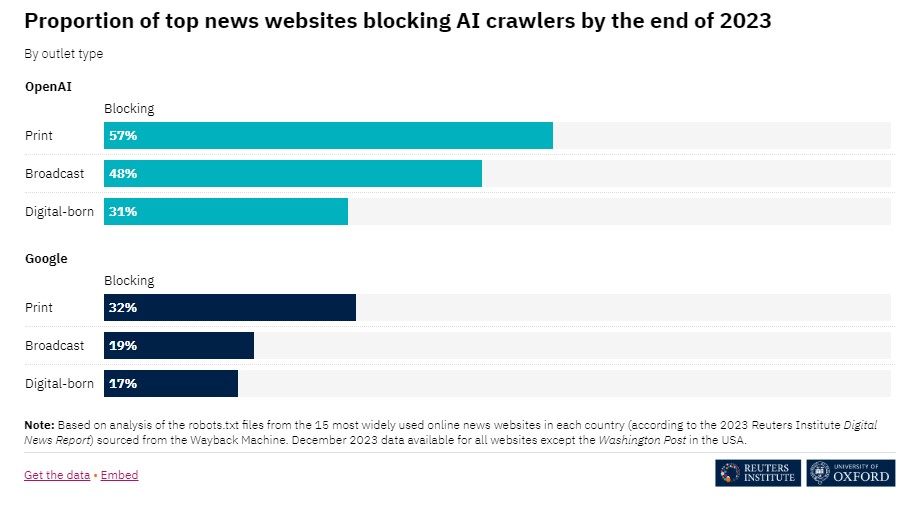
Webseiten von Printmedien werden häufiger von Crawlern blockiert als Webseiten von Rundfunkanbietern oder digitalen Verlagen, was erstaunlich erscheint, da Sprachmodelle und Chatbots gerade bei digitalen Angeboten das größte wirtschaftliche Risiko darstellen. Verlage können die robots.txt-Datei auf ihren Websites verwenden, um Webcrawler abzuweisen.
Es gibt zwei Hauptgründe für die Crawler-Blockade: Die New York Times meint beispielsweise, dass sie für die Nutzung ihrer Inhalte zum Training von KI-Modellen finanziell entschädigt werden sollte. Andere befürchten, dass die Anbieter von Chatbot-Plattformen nicht auf die Verlage verlinken oder diese Links zwar angezeigt, aber kaum genutzt werden. Dies würde zu erheblichen finanziellen Einbußen für die Verlage führen, die in erster Linie von den Besuchern ihrer Websites leben.
Große KI-Unternehmen wie OpenAI, Microsoft und Google haben das Problem bisher zwar erkannt, aber bisher nicht angegangen. Derzeit sollen einige Verlage mit KI-Unternehmen über Lizenzvereinbarungen verhandeln. OpenAI hat bereits eine Vereinbarung mit Axel Springer und anderen Verlagen bekannt gegeben. Dabei geht es um die Nutzung von Inhalten als Trainingsdaten und die Bereitstellung von Nachrichten in Chatbots.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.