Ein neu entstehendes Chatbot-Ökosystem baut auf bestehenden Webinhalten auf und könnte traditionelle Websites verdrängen. Dabei sind Lizenzierung und Finanzierung weitgehend ungeklärt.
OpenAI bietet daher Verlagen und Webseitenbetreibern ein Opt-Out an, wenn sie ihre Inhalte nicht kostenlos für die Entwicklung von Chatbots und KI-Modellen zur Verfügung stellen wollen. Dazu muss der Webcrawler "GPTBot" von OpenAI über die Datei robots.txt blockiert werden. Der Bot sammelt Inhalte, um zukünftige KI-Modelle zu verbessern.
Mittlerweile blockieren viele große Medienunternehmen wie die New York Times, CNN, Reuters, Chicago Tribune, ABC und Australian Community Media (ACM) den GPTBot. Auch andere webbasierte Content-Angebote wie Amazon, Wikihow oder Quora blockieren den OpenAI-Crawler.
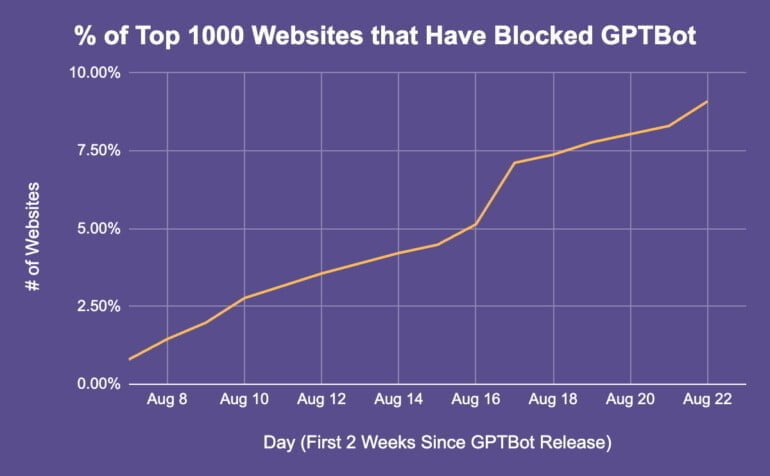
Laut einer Analyse von Originality.ai blockierten Ende August 9,2 Prozent der Top-1000-Websites den GPTBot, mit einer wöchentlichen Wachstumsrate von fünf Prozent pro Woche. Unter den Top-100-Websites liegt der Anteil bei 15 Prozent. Von 759 untersuchten robots.txt-Dateien hatten 69 den Block installiert. Dokumentiert ist die Sperrfunktion seit Anfang August.
Die größten deutschen Nachrichtenportale Bild.de, t-online.de und n-tv.de blockieren den GPTbot bisher nicht. Auch Spiegel Online lässt OpenAI noch auf die Seite. Andere Online-Nachrichtenportale wie sueddeutsche.de, zeit.de und welt.de haben dagegen eine Sperre eingebaut. Mit dem SWR hat auch der öffentlich-rechtliche Rundfunk bereits eine erste Seite mit GPTBot-Ausschluss.
Chatbots vs. WWW
Die Blockade des GPTBot ist eigentlich nur der halbe Schritt: Relevanter könnte die Blockade des ChatGPT User Agent sein. Denn über diesen greifen ChatGPT-Plugins wie OpenAIs Browsing-Funktion auf Webseiten zu, ziehen Inhalte einer Webseite in den Chat und diskutieren sie dort.
Dadurch entfällt der Klick auf die Webseite und damit die Monetarisierung - ein direkter Schaden für Webseitenbetreiber, auch wenn die Inhalte nicht langfristig gespeichert und für das KI-Training verwendet werden. Wer also den GPTBot blockiert, dürfte in den meisten Fällen auch ein Interesse daran haben, den ChatGPT User Agent zu blockieren.
Andererseits ist OpenAI beim KI-Browsing ohnehin wieder auf dem Rückzug. Offiziell, weil damit Paywalls umgangen werden können, ein ungewollter Nebeneffekt. Inoffiziell dürfte die ungeklärte Rechtelage bei der direkten Weiterverarbeitung fremder Inhalte eine größere Rolle spielen.
Dennoch macht Microsoft im Bing Chat munter weiter und bietet Webseiteninhalte leicht umformuliert im Chatfenster an. Auch die im Testbetrieb befindliche KI-Suche von Google arbeitet mit ähnlichen Methoden.

Keines der großen KI-Unternehmen hat bisher ein Konzept vorgelegt, wie das WWW-Content-Ökosystem dem Erfolg der Chatbots nicht zum Opfer fallen soll. Bisher gibt es nur Lippenbekenntnisse der Konzernchefs.
Eine Klärung der gesamten Rechtslage wird wohl vor Gericht stattfinden müssen, höchstwahrscheinlich zwischen den großen Verlagen und den Big-AI-Firmen wie Google, Microsoft und OpenAI. Die New York Times soll eine Klage gegen OpenAI vorbereiten, die für die gesamte Branche richtungsweisend sein könnte.