GTC 2022: Omniverse, Hopper GPU, bessere KI - Nvidia zeigt alles

Nvidias CEO Jenson Huang zeigt die erste Hopper-GPU, neue KI-Modelle und einen Omniverse-Computer.
Auch die diesjährige GTC beginnt mit einer ausführlichen Präsentation von Nvidias CEO Jensen Huang. Dieses Mal gibt Huang seinen Rück- und Ausblick auf Hard- und Software für Künstliche Intelligenz und das Omniverse vor einem schwarzen, digitalen Hintergrund - die Küche scheint ausgedient zu haben. Ich habe die wichtigsten Neuigkeiten der GTC 2022 für euch zusammengefasst.
Hopper-GPU für KI-Entwicklung ist im Anflug
Eine der wichtigsten Ankündigungen ist die Vorstellung der neuen Hopper-GPU H100. Die für KI-Berechnungen gebaute GPU ist der direkte Nachfolger von Nvidias A100 und setzt auf TSMCs 4N-Prozess und HBM3-Speicher. Die H100-GPU umfasst 80 Milliarden Transistoren, liefert 4,9 Terabyte Bandbreite pro Sekunde und setzt auf PCI-Express Gen5.
Aktuelle KI-Modelle soll die neue GPU bis zu 30-fach schneller ausführen als das Vorgängermodell. Beim KI-Training soll die H100-GPU etwa dreimal schneller sein als die A100-GPU. Für FP32 liefert die H100-GPU 1.000 TeraFLOP Leistung, für FP16 2.000 TeraFLOP.

Dank einer neuen Transformer-Engine, in der die vierte Generation Tensor-Kerne mit spezialisierter Software dynamisch zwischen FP8- und FP16-Präzision wechseln, sollen sich speziell große Sprachmodelle deutlich schneller trainieren lassen.
GPT-3 lasse sich beispielsweise sechsfach schneller und ein Mixture-of-Experts-Modell bis zu neunfach schneller trainieren. Die GPU unterstützt außerdem DGX Instructions, eine Methode, mit der sich dynamische Programmieraufgaben etwa für das Traveling-Salesman-Problem um den Faktor sieben beschleunigen lassen sollen.
Hopper-GPUs kommen für einzelne Karten und Superpods
Die H100-GPUs werden wie die A100 als einzelne Karte, in HGX/DGX-Systemen, in Pods und in Superpods verbaut. Die H100 CNX liefert eine H100-GPU mit schneller Datenverbindung für Server, das HGX/DGX-H100-System besteht aus acht H100-GPUs mit 640 Gigabyte HBM3-Speicher mit 24 Petabyte pro Sekunde Speicherbandbreite. Laut Huang lassen sich bis zu 32 HGX/DGX-H100-Systeme als DGX-Pods mit NVLink-Switch zusammenschalten.
Ein solches DGX-Pod liefere dank 256 H100-GPUs ein ExaFLOP KI-Rechenleistung und 20,5 Terabyte HDM3-Speicher mit einer Speicherbandbreite von 768 Terabyte pro Sekunde. Das gesamte Internet - als Beispiel - habe einen aktuellen Durchsatz von knapp 100 Terabyte pro Sekunde, so der Nvidia-CEO.
Größere Systeme mit hunderten DGX-H100-Systemen sind ebenfalls möglich. Ein erstes sogenanntes Superpod kündigte Huang unter den Namen "Nvidia Eos" an. Der Supercomputer umfasse 576 DGX-H100-Systeme mit insgesamt 4.608 H100-GPUs und soll in wenigen Monaten fertig sein. Dann soll Eos der weltweit schnellste KI-Supercomputer sein.
Nvidia CPU macht Fortschritte, KI-Framework bekommt Nachschub
Die letztes Jahr angekündigte Grace-CPU, die speziell für Datenzentren entwickelt wird, sei auf einem guten Weg, so Huang. Grace soll im nächsten Jahr verfügbar sein und dank einer direkten Chip-zu-Chip-Verbindung Übertragungsraten zwischen CPU und GPU von 900 Gigabyte pro Sekunde ermöglichen.
Nvidia zeigte außerdem einen Grace-Superchip, der zwei Grace-CPUs verbindet. Der Superchip kommt mit 144 CPU-Kernen und einem Terabyte pro Sekunde Speicherbandbreite. Nvidia erwartet, dass die CPU andere Produkte im Markt für Datenzentren in Performance und Energieeffizienz weit hinter sich lässt.
Abseits der Hardware für KI-Berechnungen gab es auf der GTC-Keynote zahlreiche Ankündigungen für verbesserte KI-Frameworks und neue Modelle. So ist Nvidias Sprach-Framework Riva 2.0 nun verfügbar und das Video- und Konferenzframework Maxine erhält Verbesserungen für bestehende Module und neue Features, die die Audioqualität verbessern sollen.
Ein neues Framework namens Sionna soll 6G-Forschung mit KI unterstützen und das Merlin-Framework für Empfehlungsalgorithmen ist in einer neuen Version für alle frei verfügbar. Für das Trainingsframework Nemo Megatron kündigt Huang zudem AWS-Unterstützung in den nächsten Monaten an.
Omniverse und die zweite KI-Welle
Seine Keynote startete Huang mit einer Einführung in Nvidias Omniverse, das zu einer Plattform für die zweite Welle Künstlicher Intelligenz werden soll. Frameworks wie PyTorch oder TensorFlow seien die Grundlage der ersten Welle, die etwa Computer Vision oder Sprachverarbeitung umfassten. Die zweite Welle umfasse etwa die Robotik, bei der KI-Agenten planen und handeln.
Das Omniverse ermöglicht digitale Zwillinge, die etwa für kreative Kollaboration oder den digitalen Nachbau von Fabriken dienen und die laut Nvidia auch die Grundlage für das Training von Robotern und autonomen Autos sind.
Für letztere zeigte Nvidia zwei aktuelle Trainingsmethoden, bei denen mittels Neural Rendering aus aufgezeichneten Fahrten digitale Welten entstehen, die anschließend für das KI-Training autonomer Autos dienen. Die trainierten Modelle können dann etwa auf Nvidias Orin-Computer in echten Fahrzeugen ausgeführt werden. Der chinesische Elektroautohersteller BYD verbaut die Orin-Hardware in seinen Fahrzeugen.
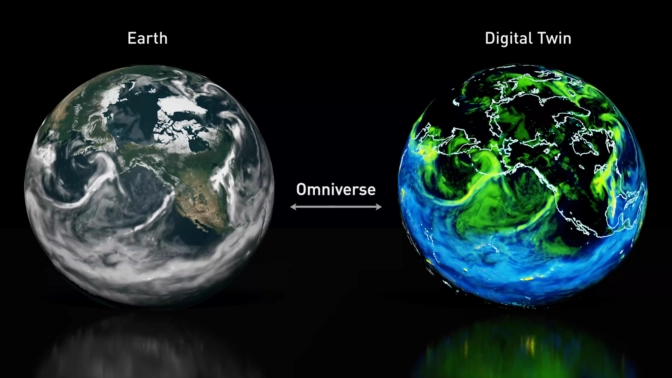
Damit nicht genug: Das Omniverse soll auch dem Klima helfen. Huang kündigte eine Plattform für digitale Zwillinge für die Wissenschaft an, die aus dem Modulus KI-Framework für Physik-Modelle und der Omniverse Earth-2-Simulation besteht.
Als Beispiel für das Potenzial zeigte Nvidia das Vorhersagemodell "FourCastNet", das mit 10 Terabyte Erddaten wie Wettervorhersagen aus 40 Jahren trainiert wurde. Das Modell emuliere und prognostiziere das Verhalten und die Risiken extremer Wetterereignisse wie Wirbelstürme mit größerer Zuverlässigkeit und bis zu 45.000 Mal schneller als klassische Ansätze.
Omniverse-Computer und Cloud-Zugang
Das Omniverse erhält außerdem neue Werkzeuge wie eine KI-unterstützte Suche für 3D-Assets, neue Entwicklerwerkzeuge und ein Avatarmodul. Ab sofort ist das Omniverse mit allen zugehörigen Werkzeugen zudem in der Cloud per Geforce Now verfügbar. Laut Nvidia wurde die Software bislang 150.000 Mal heruntergeladen. Mit dem Cloud-Zugang will die Firma die Einstiegshürde Hardware senken.
Anders als KI-Berechnungen oder andere High-Performance-Computing-Aufgaben benötigen digitale Zwillinge und das Omniverse jedoch physikalisch exakte Echtzeit-Simulationen. Datenzentren für das Omniverse bräuchten daher Skalierbarkeit, niedrige Latenzzeiten und eine präzise Zeitverarbeitung - Huang nennt das ein synchrones Rechenzentrum.
Nvidia stellt daher Nvidia OVX vor, ein Rechensystem, das für den Betrieb von groß angelegten digitalen Zwillingen entwickelt wurde. Ein OVX-Server setzt auf acht Nvidia A40-GPUs, ein OVX-Superpod auf 32 OVX-Server.
Laut Nvidia kombinieren OVX-Systeme hochleistungsfähige GPU-beschleunigte Rechen-, Grafik- und KI-Leistung mit Hochgeschwindigkeits-Speicherzugriff, Netzwerken mit geringer Latenz und präzisem Timing. Verbessert werden soll OVX in naher Zukunft durch die ebenfalls angekündigte Ethernet-Plattform Spectrum-4, die einen Switching-Durchsatz von 51,2 Terabit pro Sekunde ermöglicht.
Weitere Informationen gibt es auf Nvidias Blogbeitrag zur Hopper-Ankündigung. Die komplette Keynote könnt ihr im folgenden Video ansehen. Mit Instant NeRF stellte Nvidia außerdem eine beeindruckende neue KI-Rendertechnologie vor.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.