Der IT-Pionier IBM steigt in das Geschäft mit Open-Source-Modellen ein, die auf Coding spezialisiert sind. Die optimierten Modelle sind in Benchmarks leistungsfähiger als die Open-Source-Konkurrenz, aber anspruchsvoller in der Anwendung als kommerzielle Angebote wie Copilot.
IBM Research hat unter dem Namen Granite Code eine neue Familie großer Sprachmodelle veröffentlicht, die Unternehmen bei einer Vielzahl von Aufgaben in der Softwareentwicklung unterstützen sollen.
3 bis 34 Milliarden Parameter
Die Modelle gibt es in zwei Varianten (Base und Instruct) und jeweils in vier verschiedenen Größen mit 3, 8, 20 und 34 Milliarden Parametern. Sie unterscheiden sich auch in der Kontextlänge, die zwischen 2.048 Tokens bei 3 Milliarden, 4.096 Tokens bei 8 Milliarden und 8.192 Tokens ab 20 Milliarden Parametern liegt. Das relativ kleine Kontextfenster schränkt die Nutzbarkeit etwas ein, da es wenig Platz bietet, um zusätzliche Informationen wie spezifische Dokumentation oder die eigene Codebasis in einem Prompt unterzubringen.
Das Training der Basismodelle wurde in zwei Phasen durchgeführt. Phase 1 umfasste das Training mit drei bis vier Billionen Token aus 116 Programmiersprachen, um ein umfassendes Verständnis aufzubauen. In Phase 2 wurden die Modelle mit einer sorgfältig zusammengestellten Mischung aus 500 Milliarden Token aus hochwertigen Code- und natürlichen Sprachdaten weiter trainiert, um die Fähigkeit zum logischen Schlussfolgern zu verbessern.
Die Instruktionsmodelle wurden durch Verfeinerung der Basismodelle mit einer Kombination aus gefilterten Code-Commits, natürlichsprachlichen Instruktionsdatensätzen und synthetisch generierten Code-Datensätzen entwickelt.
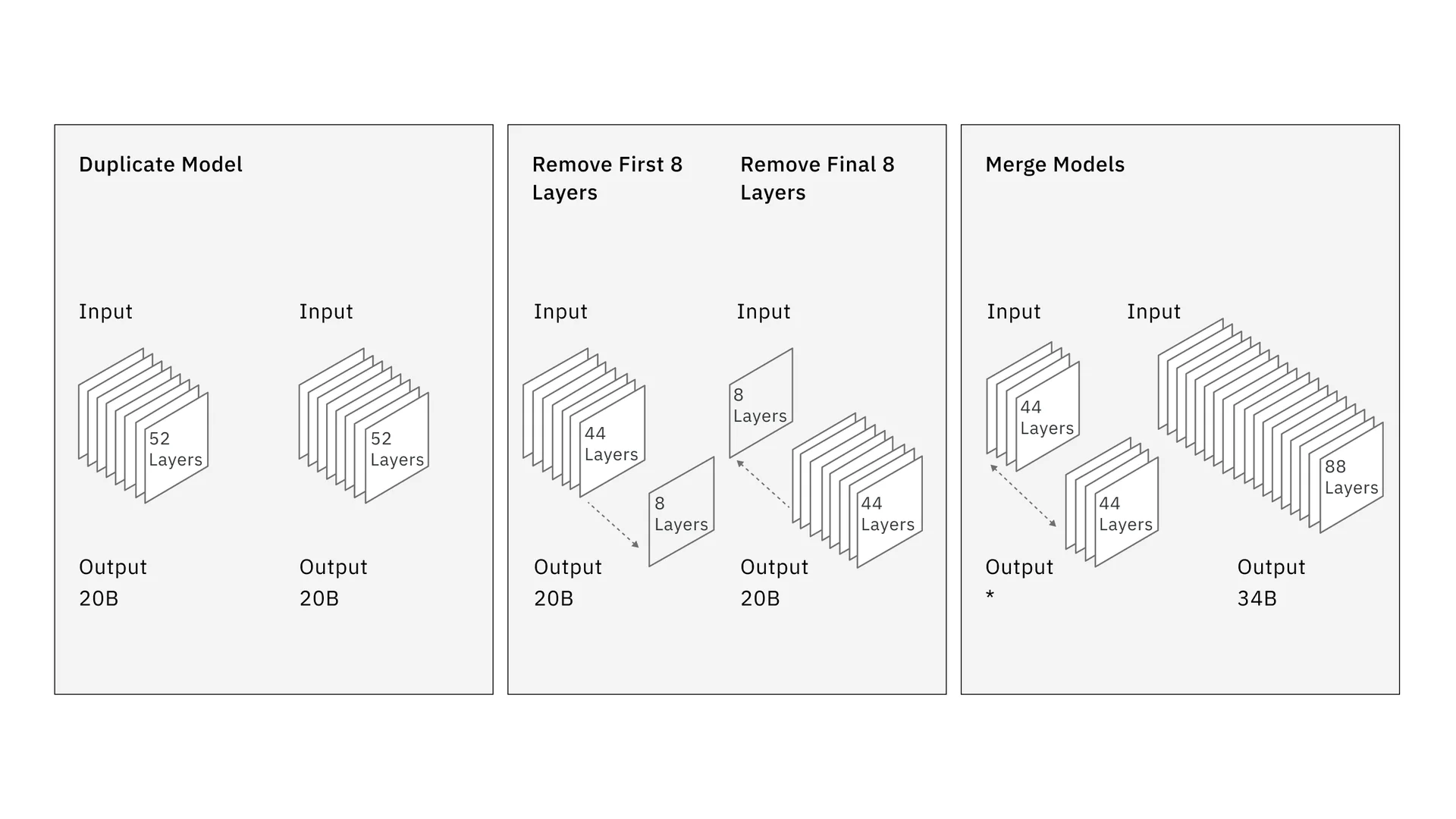
Das Besondere an der 34B-Variante ist ihre Entstehung, da die IBM-Forscher einen neuen Ansatz namens Depth Upscaling verwendeten. Zuerst duplizierten sie die 20B-Variante mit 52 Schichten, entfernten dann die ersten acht Schichten der einen und die letzten acht Schichten der anderen Variante und fügten sie schließlich wieder zu einem Modell mit 88 Schichten zusammen.
Gleiche oder bessere Leistung mit weniger Parametern
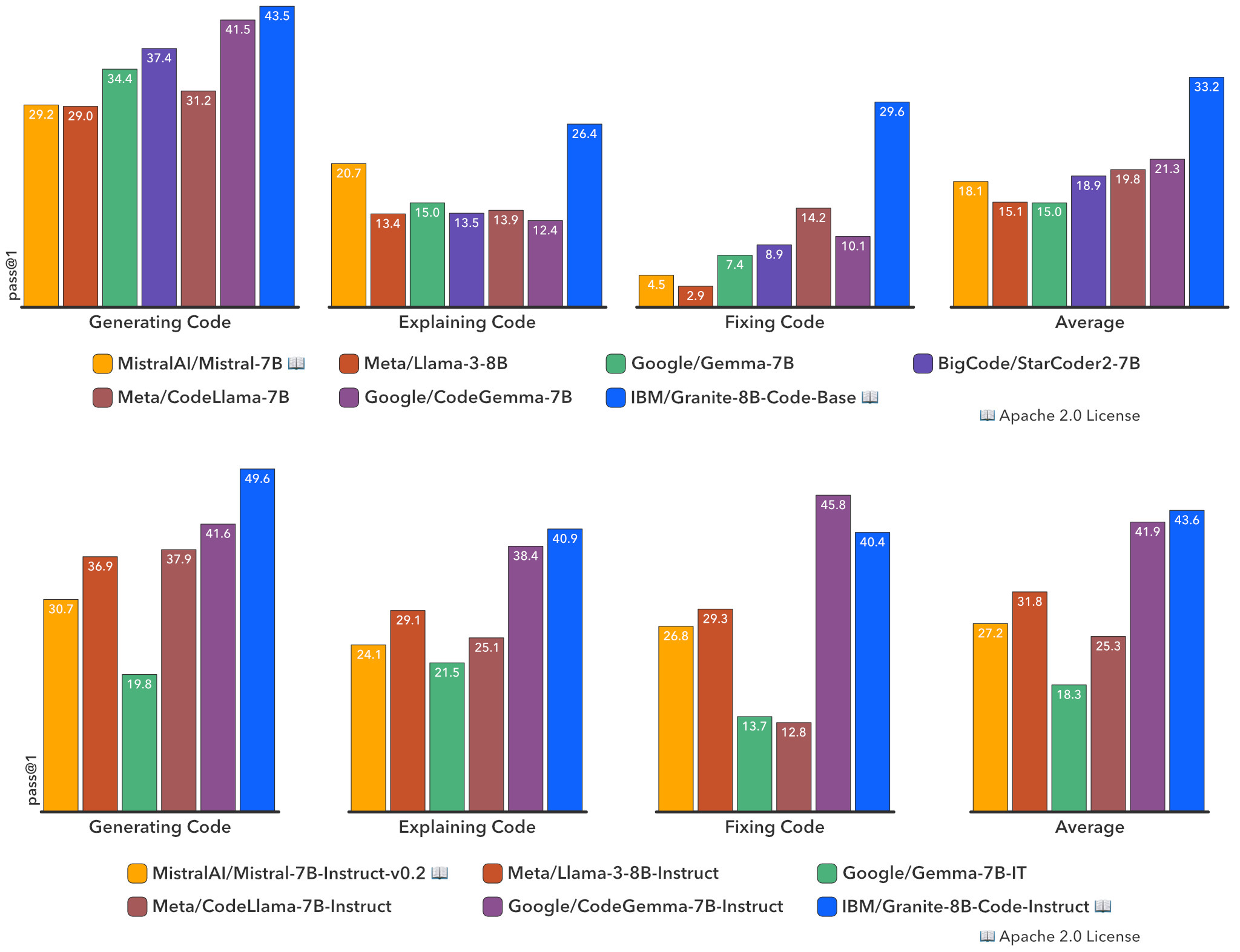
Die Wissenschaftler:innen haben Evaluierungen der Granite-Code-Modelle anhand eines umfassenden Satzes von Benchmarks durchgeführt, die Codesynthese, Fehlerbehebung, Erklärung, Bearbeitung, mathematisches Schlussfolgern und mehr abdecken.
Die Ergebnisse zeigten, dass die Granite-Code-Modelle unter den Open-Source-Modellen in allen Größen und Benchmarks eine sehr starke Leistung erbrachten und oft andere Open-Source-Code-Modelle übertrafen, die doppelt so groß sind.
Zum Beispiel schlug Granite-8B-Code-Base beim HumanEvalPack-Benchmark das leistungsstärkste CodeGemma-8B-Modell von Google im Durchschnitt um fast 12 Punkte (33,2 % gegenüber 21,3 %), obwohl es mit deutlich weniger Token trainiert wurde.

Die Granite Code-Modelle sind als vertrauenswürdige, unternehmenstaugliche Code-LLMs konzipiert. Alle Modelle wurden laut IBM mit lizenzkonformen Daten trainiert. Die gesamte Datenerfassungs-, Filterungs- und Vorverarbeitungspipeline wird vom Hersteller im Paper transparent beschrieben. Der Großteil der Trainingsdaten stammt aus einem bereinigten GitHub-Datensatz, StarCoderData sowie anderen öffentlich zugänglichen Codespeichern.
IBM plant, kontinuierlich Updates für diese Modelle zu veröffentlichen. Als nächstes sollen Versionen mit größeren Kontextfenstern sowie auf Python und Java spezialisierte Varianten erscheinen.
Open-Source-KI ist nur die halbe Miete
Die reine Verfügbarkeit auf Hugging Face und GitHub solcher auf Coding spezialisierten Modelle ist noch kein großer Gewinn für Programmierer:innen, zumal IBM in Konkurrenz unter anderem mit Meta und Google steht, die ebenfalls Open-Source-LLMs veröffentlicht haben. Vielmehr müssen auch die nötigen Entwicklungsumgebungen geschaffen werden, die KI-Modelle sinnvoll im Alltag einsetzen zu können.
Hier hat unter anderem GitHub mit Copilot eine Lösung parat, wobei sich große Unternehmen wohler damit fühlen könnten, wenn sie Open-Source-Modelle in ihren eigenen Rechenzentren verarbeiten könnten, anstatt ihren Code per API über externe Server laufen zu lassen.
Der Granite Code von IBM ist zwar frei verfügbar und bietet dank Open Source einen höheren Datenschutz. Diesen Vorteil können aber nur grosse Unternehmen nutzen, die einerseits über genügend Rechenkapazität und andererseits über das nötige Know-how verfügen, um die Technologie in ihre Arbeitsabläufe zu integrieren. Genau an diese Zielgruppe vermarktet IBM auch seine Enterprise-Plattform Watsonx, in die Granite Code ab sofort integriert werden soll.
Die neue LLM-Familie ist zwar die erste von IBM in dieser Richtung. Mit dem CodeNet-Datensatz legte das US-Unternehmen aber schon 2021 einen wichtigen Grundstein für die Entwicklung offener Coding-Sprachmodelle.