Kein Fünkchen Verständnis: Apple-Forscher bezweifeln Logik-Fähigkeiten von OpenAI o1

Eine neue Studie von Apple-Forschern, darunter KI-Experte Samy Bengio, stellt die logischen Fähigkeiten aktueller Large Language Models grundlegend infrage - selbst bei OpenAIs neuem "Reasoning-Modell" o1.
Eine umfangreiche Studie eines Forscherteams um Mehrdad Farajtabar und Samy Bengio von Apple wirft Zweifel an den tatsächlichen Reasoning-Fähigkeiten großer Sprachmodelle (LLMs) auf. Die auf arXiv veröffentlichten Ergebnisse deuten darauf hin, dass selbst führende Modelle wie GPT-4o und o1 von OpenAI keine echte Logik anwenden, sondern lediglich Muster imitieren.
Die Forscher untersuchten sowohl Open-Source-Modelle wie Llama, Phi, Gemma und Mistral als auch proprietäre Modelle, einschließlich der neuesten OpenAI-Reihen. Dazu entwickelten sie ein neues Evaluierungstool namens GSM-Symbolic, das auf dem bekannten GSM8K-Datensatz für mathematisches Schlussfolgern basiert, diesen aber um symbolische Vorlagen erweitert.
Leistungseinbrüche bei irrelevanten Zusatzinformationen
Die Ergebnisse zeigen, dass die aktuellen Genauigkeitswerte auf GSM8K nicht zuverlässig sind. Die Forscher beobachteten große Leistungsschwankungen: Das Llama-8B-Modell erzielte etwa Werte zwischen 70 Prozent und 80 Prozent, während Phi-3 zwischen 75 Prozent und 90 Prozent schwankte. Für die meisten Modelle lag die durchschnittliche Leistung auf GSM-Symbolic niedriger als auf dem ursprünglichen GSM8K, so Farajtabar.
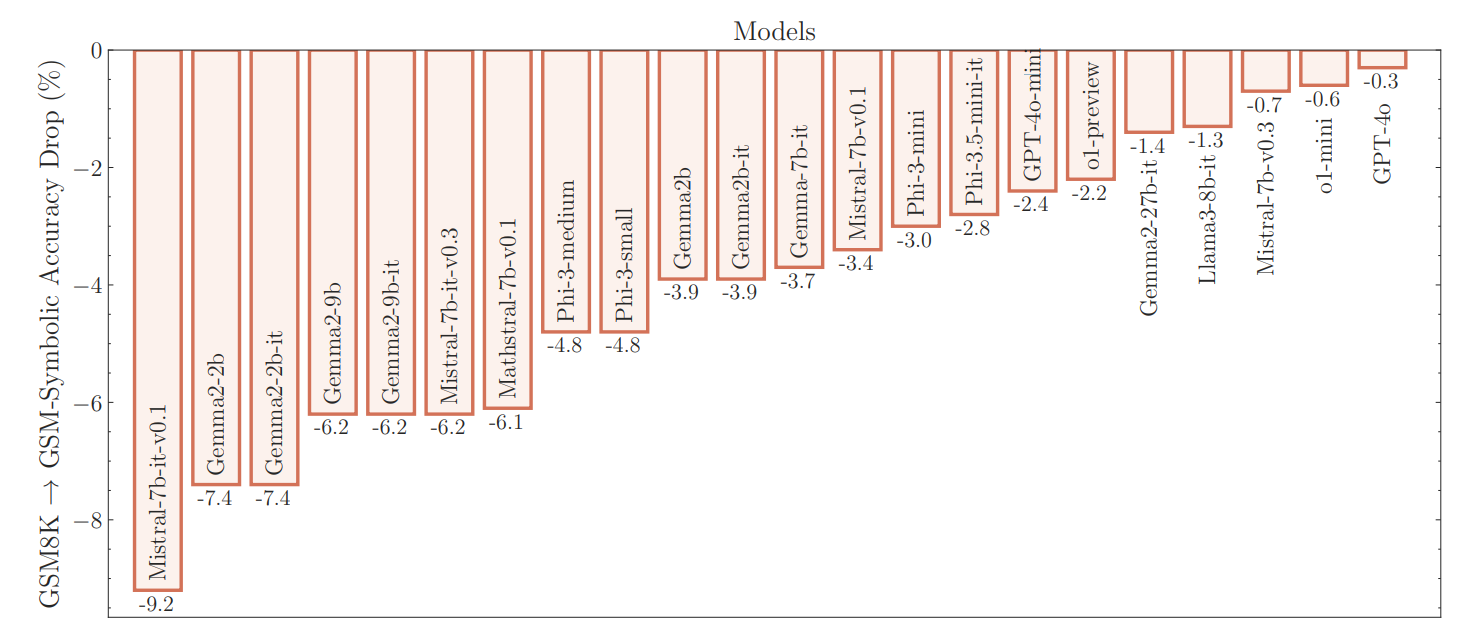
Besonders aufschlussreich war das Experiment mit dem Datensatz GSM-NoOp. Hier fügten die Forscher einer Textaufgabe eine einzelne Aussage hinzu, die relevant erscheint, aber nicht zur Gesamtargumentation beiträgt.
Das Ergebnis war ein massiver Leistungseinbruch bei allen Modellen, einschließlich der o1-Modelle von OpenAI. "Würde sich die Punktzahl eines Grundschülers in einem Mathetest um etwa 10 Prozent ändern, wenn wir nur die Namen ändern würden?", fragt Farajtabar rhetorisch.

Farajtabar betont, dass das eigentliche Problem in der dramatischen Zunahme der Varianz und dem Leistungsabfall liegt, wenn die Schwierigkeit der Aufgabe nur geringfügig erhöht wird. Um die Variation bei steigender Schwierigkeit zu bewältigen, würde man wahrscheinlich "exponentiell mehr Daten" benötigen.
Selbst OpenAIs neuestes o1-Modell, das auf vielen Benchmarks Spitzenwerte erzielt, zeigt laut der Studie die gleichen grundlegenden Schwächen. Zwar performt es insgesamt besser als Open-Source-Modelle, doch auch hier brechen die Ergebnisse bei Zusatzinformationen deutlich ein.
Skalierung löst das Problem wohl nicht
Die Forscher bezweifeln daher, dass eine Skalierung von Daten, Modellen oder Rechenleistung dieses Problem grundsätzlich lösen kann. Obwohl die OpenAI o1-Serie besser abschneidet, leide sie immer noch unter Leistungsschwankungen und macht "dumme Fehler", so die Forscher. Dieses Ergebnis wird durch eine andere, kürzlich veröffentlichte Studie bestätigt.
"Insgesamt fanden wir keine Anzeichen für formales logisches Denken in Sprachmodellen", fasst Farajtabar zusammen. "Ihr Verhalten lässt sich besser durch ausgeklügelte Mustererkennung erklären." Die Skalierung von Daten, Parametern und Rechenleistung würde zu besseren Mustererkennungsprogrammen führen, aber "nicht unbedingt zu besseren Argumentationsprogrammen".

Die Studie stellt zudem die Aussagekraft bisheriger Leistungsmessungen für LLMs infrage. Die teilweise stark verbesserten Ergebnisse im populären Mathematik-Benchmark GSM8K (GPT-3 erreichte vor rund drei Jahre 35 Prozent, aktuelle Modelle bis zu 95 Prozent) könnten darauf zurückzuführen sein, dass Testbeispiele in die Trainingsdaten eingeflossen sind, so die Forscher.
Auch diese These wird durch eine kürzlich veröffentlichte Studie gestützt, die zeigt, dass insbesondere kleinere KI-Modelle bei der Generalisierung mathematischer Aufgaben schlechter abschneiden - möglicherweise, weil sie während des Trainings weniger Daten gesehen haben.
Neue Ansätze für KI mit echter Logik
Die Apple-Forscher betonen, dass das Verständnis der wahren Reasoning-Fähigkeiten von LLMs entscheidend für ihren Einsatz in realen Szenarien ist, in denen Genauigkeit und Konsistenz nicht verhandelbar sind - speziell in den Bereichen KI-Sicherheit, Alignment, Bildung, Gesundheitswesen und Entscheidungsfindungssysteme.
"Wir glauben, dass weitere Forschung unerlässlich ist, um KI-Systeme zu entwickeln, die zu formalem Reasoning fähig sind und über Mustererkennung hinausgehen", so das Fazit der Studie. Dies sei eine entscheidende Herausforderung auf dem Weg zu Systemen mit menschenähnlichen kognitiven Fähigkeiten oder allgemeiner Intelligenz.
Der KI-Forscher François Chollet bezeichnet die Apple-Studie als "weiteren Beweis auf einem großen Stapel". Dass LLMs keine Logik beherrschen, sei Anfang 2023 noch eine "ketzerische Ansicht" gewesen - nun werde sie zur "selbstverständlichen konventionellen Weisheit", so Chollet.
Uneinigkeit in der KI-Forschung
Interessant an der Studie ist, dass hier zwei führende KI-Forschungseinrichtungen, Apple und OpenAI, gegensätzliche Positionen einnehmen.
OpenAI geht davon aus, dass es sich bei o1 um das erste Reasoning-Modell handelt (Stufe 2), das wiederum die Grundlage für logisch agierende Agenten legt (Stufe 3), die für OpenAI der nächste Wachstumshorizont sein sollen.
Den Argumenten der Apple-Forscher steht etwa ein neuer OpenAI-Benchmark gegenüber, der zeigt, dass o1 in der Lage ist, maschinelle Lernaufgaben zu lösen. Dabei will OpenAI Testbeispiele in den Trainingsdaten explizit ausgeschlossen haben. Eine andere Studie kommt zu dem Schluss, dass KI-Modelle zumindest eine Art probabilistisches Schlussfolgern durchführen.
Ein Grund für diese Unterschiede könnte sein, dass Begriffe wie Intelligenz, Denken und Logik unscharf sind, unterschiedlich definiert werden oder in Variationen und Abstufungen auftreten können. Letztlich wird die akademische Diskussion in den Hintergrund treten, wenn zukünftige KI-Modelle in der Lage sind, die ihnen gestellten Aufgaben zuverlässig zu lösen - auch auf ungewöhnlichen Wegen wie OpenAIs o1.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.