KI-Assistenten verfälschen Nachrichten systematisch laut BBC-Studie

Die BBC hat in einer umfangreichen Studie nachgewiesen, dass KI-Assistenten wie ChatGPT, Microsoft Copilot, Google Gemini und Perplexity systematisch Nachrichteninhalte verfälschen.
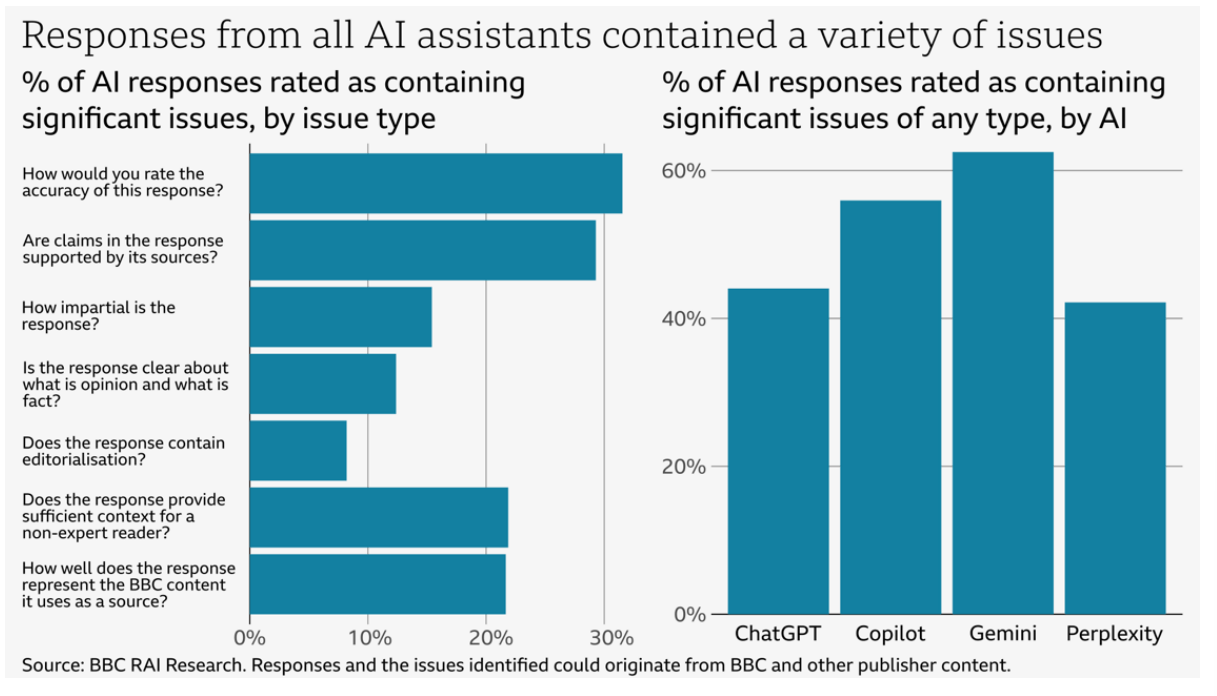
45 BBC-Journalisten analysierten im Dezember 2024 die Antworten der KI-Systeme auf 100 aktuelle Nachrichtenfragen. Die Analyse erfolgte anhand von sieben Kriterien: Genauigkeit, Quellenangabe, Unparteilichkeit, Unterscheidung zwischen Meinung und Fakten, Kommentierung, Kontext und die korrekte Darstellung von BBC-Inhalten. Die Antworten wurden auf einer Skala von "keine Probleme" bis "erhebliche Probleme" bewertet.
Chatbots machen teilweise gravierende inhaltliche Fehler bei News-Zusammenfassungen
Laut BBC enthielten 51 Prozent aller KI-Antworten signifikante Fehler. Zu den häufigsten Problemen gehörten falsche Fakten, unzureichende Quellenangaben und fehlender Kontext. 19 Prozent der Antworten, in denen BBC-Inhalte zitiert wurden, enthielten sachliche Fehler. In 13 Prozent der Fälle waren die Zitate entweder verfälscht oder in den angegebenen Quellen gar nicht vorhanden.
Die Fehler reichten von falschen Gesundheitsempfehlungen bis zu erfundenen Zitaten. So behauptete Google Gemini fälschlicherweise, der britische staatliche Gesundheitsdienst NHS (National Health Service) rate vom Vaping ab, obwohl die Gesundheitsbehörde die E-Zigarette als Methode zur Rauchentwöhnung empfiehlt - also eine völlige Umkehrung der eigentlichen Aussage.
Perplexity generierte falsche Informationen über den Tod des Wissenschaftsjournalisten Michael Mosley, einschließlich des Todesmonats, und verfälschte Aussagen seiner Familie. ChatGPT bezeichnete den bereits im Juli 2024 getöteten Hamas-Führer Ismail Haniyeh noch im Dezember als aktives Führungsmitglied.
Die KI-Assistenten zeigten auch grundlegende Schwächen im Umgang mit Quellen. Sie verwendeten veraltete Artikel, vermischten Meinungen mit Fakten, attribuierten Aussagen falsch, fügten unbegründete Meinungen in Aussagen ein und ließen häufig wichtigen Kontext weg. Microsoft Copilot zitierte etwa eine Live-Berichterstattung von 2022 als aktuelle Quelle zur schottischen Unabhängigkeitsdebatte.
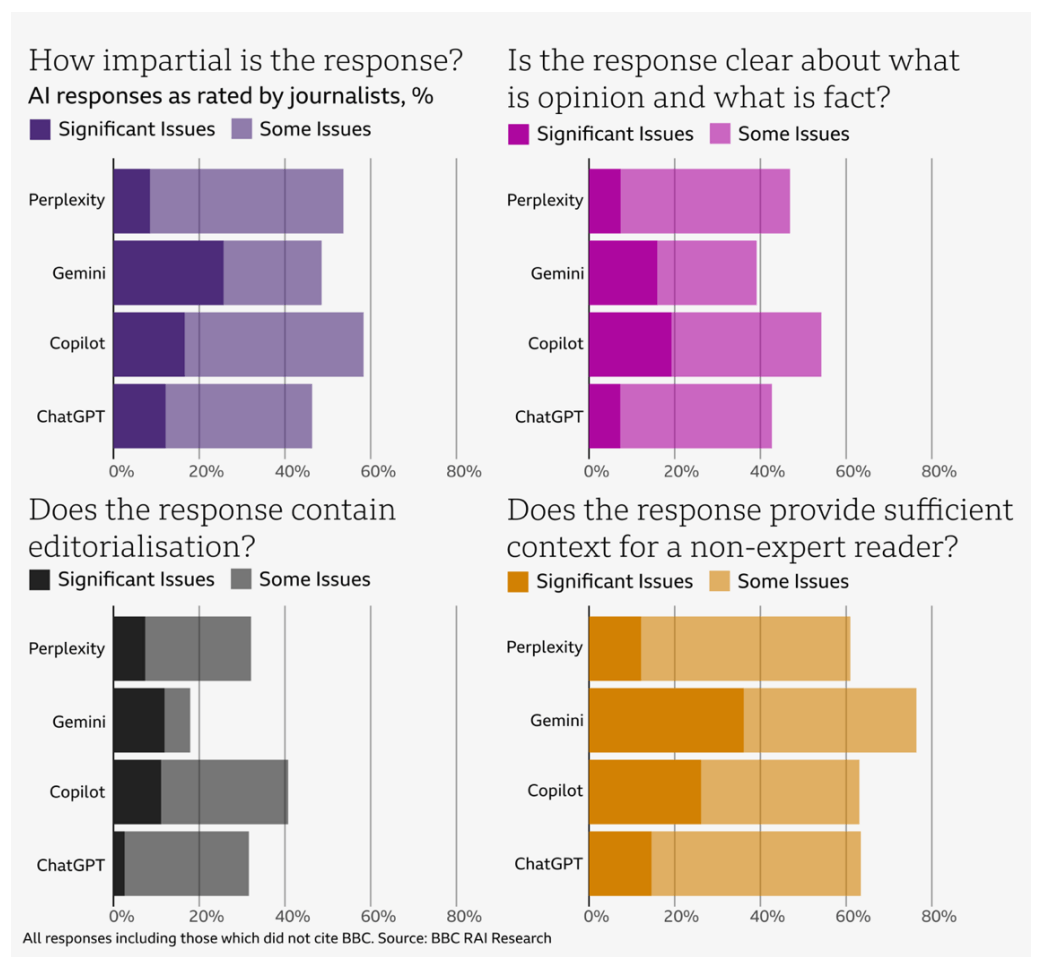
Die BBC fordert angesichts der Ergebnisse eine stärkere Regulierung von KI-Systemen und mehr Kontrolle darüber, wie deren Inhalte genutzt werden. Besonders problematisch sei es, wenn die KI-Assistenten bekannte Medienmarken wie die BBC als Quelle angeben und die Nutzer so dazu verleitet werden, den Antworten zu vertrauen - auch wenn diese falsch sind. Das Medienunternehmen plant, die Studie bald zu wiederholen.
Wahres Ausmaß unbekannt
Die Bewertungskriterien der BBC-Journalisten waren streng. So wurden auch kleinere Ungenauigkeiten als "signifikante Probleme" eingestuft, wenn sie potenziell irreführend sein könnten. Darüber hinaus sollten in Folgestudien unabhängige Prüfer und Vergleichsgruppen eingesetzt werden. Ein Vergleich der tatsächlichen Fehlerrate zwischen Mensch und Maschine wäre ebenfalls relevant.
Die BBC betont selbst, dass ihre Untersuchung nur an der Oberfläche des Problems kratzen kann. "Das Ausmaß der Fehler und die Verzerrung vertrauenswürdiger Inhalte ist unbekannt", heißt es in dem Bericht. KI-Assistenten könnten Antworten auf ein breites Spektrum von Fragen geben, und Nutzer könnten unterschiedliche Antworten auf die gleiche oder eine ähnliche Frage erhalten. Selbst KI-Unternehmen würden wahrscheinlich nicht das wahre Ausmaß von KI-Fehlern erfassen.
Dennoch zeigt die Studie systematische Schwächen von KI-Systemen bei der Verarbeitung von Nachrichteninhalten - und diese Erkenntnisse sind nicht neu. Auch frühere Untersuchungen, etwa im politischen Bereich, haben diese Schwächen aufgezeigt. In einem besonders krassen Fall machte Microsofts Chatbot Bing einen Gerichtsreporter zum Täter, weil er nicht zwischen Berichterstatter und Täter unterscheiden konnte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.