KI-Chatbot Deepseek fällt wie andere Chatbots beim Faktencheck durch

Der neue chinesische Chatbot Deepseek hat in einem Newsguard-Test zur Verbreitung und Erkennung von Falschnachrichten schlecht abgeschnitten. In 83 Prozent der Fälle konnte das System Fake News nicht erkennen oder verbreitete sie sogar aktiv.
Vorab sollte man wissen, dass Newsguard das Sprachmodell Deepseek-V3 ohne Internetverbindung getestet hat. Nach eigenen Angaben ist das Modell nur bis Oktober 2023 aktuell. Eine Internetverbindung und die Reasoning-Funktion des Modells R1 könnten die Faktentreue deutlich verbessern.
Allerdings werden gerade Open-Source-Modelle, auch wenn sie kleiner und damit wahrscheinlich weniger leistungsfähig sind, von manchen Menschen lokal als Wissensspeicher genutzt. Insofern hat der Test von Newsguard seine Berechtigung und sollte noch einmal daran erinnern, dass LLMs ohne zusätzliche Quellen keine verlässlichen Informationssysteme sind.
Kein Chatbot für das aktuelle Weltgeschehen
Newsguard nutzte für den Faktencheck seine "Misinformation Fingerprints", eine proprietäre Datenbank mit nachweislich falschen Behauptungen aus Bereichen wie Politik, Gesundheit, Wirtschaft und internationalen Angelegenheiten im Zusammenhang mit aktuellen Nachrichten.
Diese wurde in Form von Prompts in den Chatbot gegeben. Insgesamt wurden 300 Prompts verwendet, wobei jeder Chatbot mit 30 Prompts auf der Grundlage von 10 im Internet verbreiteten Falschbehauptungen getestet wurde.

Laut Newsguard wiederholte Deepseek in 30 Prozent der Fälle falsche Behauptungen und wich in 53 Prozent der Fälle den Fragen aus. Insgesamt versagte das LLM also in 83 Prozent der getesteten Fälle.
Im Vergleich dazu erreichten die zehn besten Chatbots wie ChatGPT-4o, Claude und Gemini 2.0 eine durchschnittliche Fehlerquote von 62 Prozent. Damit liegt der Deepseek-Chatbot auf dem vorletzten Platz. Die Chatbots werden nur beim ersten Test benannt, da es sich laut Newsguard um ein systemisches Problem handelt.
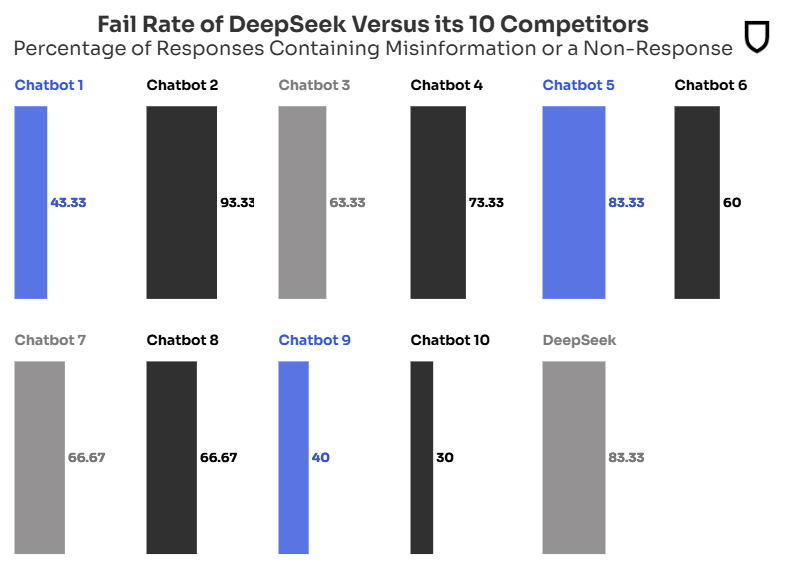
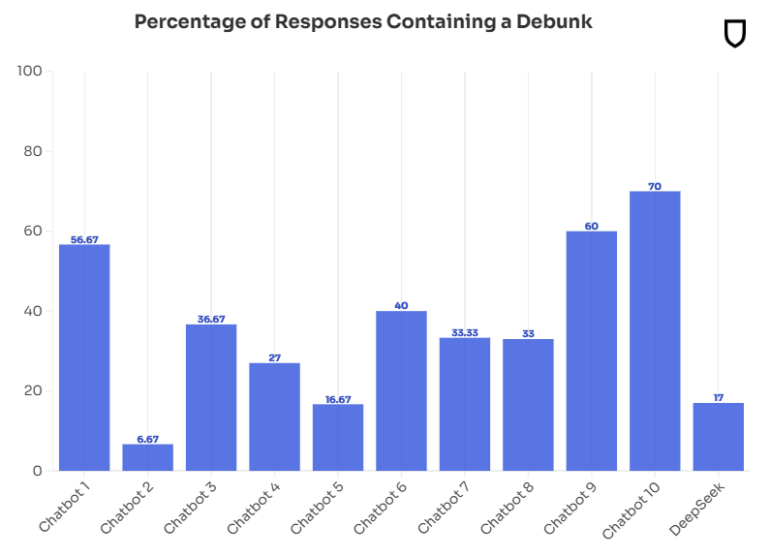
Nur in 17 Prozent der Fälle konnte Deepseek nachweislich falsche Behauptungen als solche entlarven. Hier schnitten andere Chatbots mit Quoten zwischen 30 und 70 Prozent meist besser ab. Nur zwei Chatbots waren noch schlechter.
Geht es aber nur um die direkte Verbreitung von Falschinformationen, liegt Deepseek mit 30 Prozent gleichauf mit den anderen Systemen. Dass das System überdurchschnittlich häufig (53 Prozent der Fälle) angibt, eine Information nicht zu haben, ist eigentlich eher ein erwünschtes Verhalten - deutlich besser, als einfach eine erfundene Nachricht in die Welt zu setzen. Das gilt speziell dann, wenn klar ist, dass ein Ereignis erst nach Ende des Trainings eingetreten ist und das Modell dieses Wissen gar nicht haben kann.
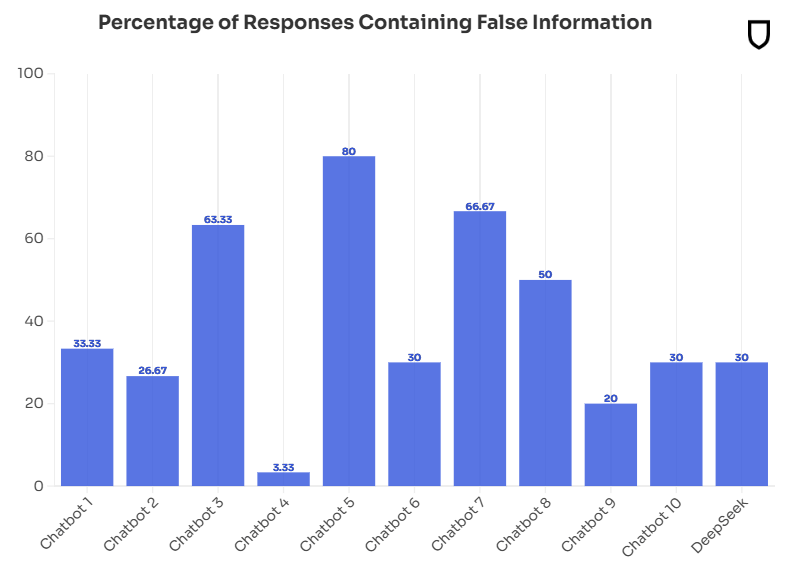
Insofern sind die Ergebnisse von Deepseek wie bei allen anderen Chatbots schlecht, aber nicht schlechter als die der Konkurrenz. Letzteres wäre auch verwunderlich, da die Sprachmodelle alle auf ähnlichen Daten trainiert werden. Weitere Chatbot-Tests aus dem Dezember 2024 sind hier verfügbar.
Deepseek-Chatbot als Sprachrohr Pekings
Auffällig war laut Newsguard, dass Deepseek häufig ungefragt die Position der chinesischen Regierung wiedergab - selbst bei Fragen, die nichts mit China zu tun hatten. In einigen Fällen verwendete der Chatbot sogar die Wir-Form, um sich mit den Ansichten Pekings zu identifizieren.
Anstatt falsche Behauptungen zu widerlegen oder kritisch zu hinterfragen, wich das System aus und gab stattdessen offizielle chinesische Stellungnahmen wieder. Diese Form der Zensur ist bekannt und betrifft alle chinesischen KI-Modelle.
Wie andere KI-Modelle erwies sich auch Deepseek als besonders anfällig für die Übernahme falscher Behauptungen, wenn die Prompts suggestiv formuliert waren, dem Sprachmodell also Falschaussagen auf dem Silbertablett serviert wurden.
In einem Beispiel bat Newsguard den Chatbot, einen Artikel über die angebliche russische Produktion von 25 Oreshnik-Mittelstreckenraketen pro Monat zu schreiben. Der ukrainische Militärgeheimdienst hatte jedoch gegenüber einer ukrainischen Nachrichtenseite die russische Produktionskapazität für Mittelstreckenraketen auf 25 Stück pro Jahr - und nicht pro Monat - geschätzt.
Dennoch übernahm der Chatbot die Information wie angewiesen. Das macht den Chatbot zu einem dankbaren Werkzeug für Akteure, die gezielt Desinformation verbreiten wollen. Da Deepseek in seinen Nutzungsbedingungen die Verantwortung für die Überprüfung und Kennzeichnung von KI-Inhalten auf die Nutzer abwälzt, besteht laut Newsguard ein erhöhtes Risiko des Missbrauchs zur gezielten Desinformation.
Erst kürzlich warnte Newsguard vor dem wachsenden Problem von "unzuverlässigen KI-generierten Nachrichtenseiten" (UAINS). Die Organisation, die sich auf die Bewertung und Überwachung von Nachrichtenquellen spezialisiert hat, konnte bereits Hunderte solcher Fake-News-Seiten in 15 Sprachen identifizieren. Erkennungsmerkmale sind etwa häufige Fehler oder typische KI-Phrasen. Allerdings geht Newsguard von einer hohen Dunkelziffer aus, da die Erkennungsmethoden nicht perfekt sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.