KI-generierte Forschungsideen sind laut Studie innovativer, aber schwieriger umzusetzen

Eine großangelegte Studie mit mehr als 100 Forschenden im Bereich der Computerlinguistik zeigt, dass KI-generierte Forschungsideen von Expert:innen als signifikant neuartiger eingeschätzt werden als Ideen von menschlichen Expert:innen. KI-Ideen können jedoch Schwächen in der Umsetzbarkeit aufweisen.
Können große Sprachmodelle neuartige Forschungsideen generieren, die mit denen menschlicher Expert:innen vergleichbar sind? Dieser Frage ging ein Forscherteam der Stanford University in einer sorgfältig kontrollierten Vergleichsstudie mit mehr als 100 Forschenden aus dem Bereich der Verarbeitung natürlicher Sprache nach.
KI-Ideen häufig zu vage oder mit unrealistischen Annahmen
Nahezu 300 Bewertungen unter allen Versuchsbedingungen ergaben, dass KI-generierte Ideen als neuartiger eingestuft wurden als Ideen menschlichen Ursprungs. Dieses Ergebnis erwies sich auch nach mehreren Hypothesenkorrekturen und verschiedenen statistischen Tests als robust.
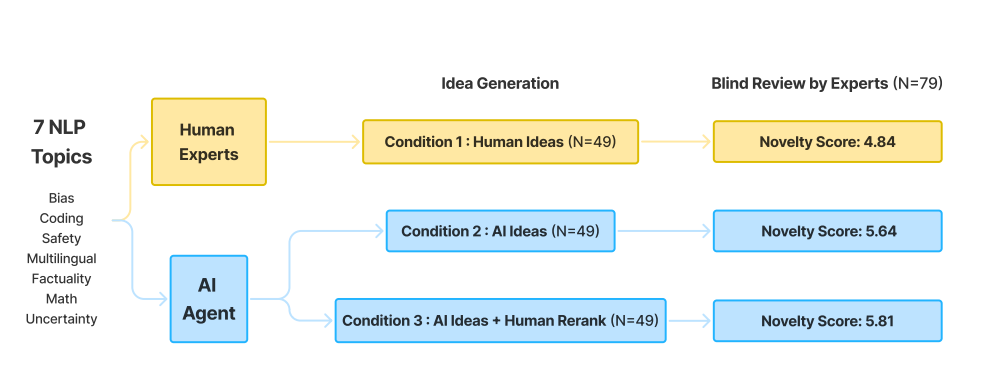
Es gab allerdings Anzeichen, dass diese Gewinne möglicherweise leicht auf Kosten der Umsetzbarkeit gingen. Allerdings reichte die Studiengröße nicht aus, um diese Effekte eindeutig zu identifizieren.
Obwohl sich LLM-Ideen leichter skalieren lassen als menschliche, mangelte es den Modellen bei zunehmender Generierung an Vielfalt. Außerdem konnten sie (zumindest derzeit) nicht als zuverlässige Bewerter dienen.
Zu den häufigsten Schwachstellen der KI-Ideen gehörten:
1. Zu vage Angaben zu Implementierungsdetails
2. Falsche Verwendung von Datensätzen
3. Fehlende oder unangemessene Vergleichsmaßstäbe (Baselines)
4. Unrealistische Annahmen
5. Zu ressourcenintensiv
6. Unzureichend motiviert
7. Bestehende Best Practices nicht ausreichend berücksichtigt
Im Gegensatz dazu waren die Ideen von Menschen im Allgemeinen stärker in der bestehenden Forschung und praktischen Überlegungen verankert, aber möglicherweise weniger innovativ.
Menschliche Ideen konzentrierten sich eher auf gängige Probleme oder Datensätze und priorisierten manchmal Machbarkeit und Effektivität gegenüber Neuheit und Spannung.
Die Studie umfasste die Generierung von Ideen durch menschliche Expert:innen und ein KI-System mit dem Abruf externer Quellen durch RAG und basierend auf GPT-3.5, GPT-4 und Llama-2-70B - vergleichsweise alte Modelle, die von GPT-4o oder o1 und Llama 3 mittlerweile überholt wurden.
Um Störfaktoren zu reduzieren, standardisierten die Forschenden den Stil der Ideen von Menschen und KI und glichen die Themenverteilung an. So konnten die menschlichen Bewerter:innen die Ideen möglichst unvoreingenommen beurteilen.
KI und Menschen sollen Ideen ausprobieren
Die Forscher haben verschiedene Ansätze vorgeschlagen, um ihre Erkenntnisse zu vertiefen und offene Fragen zu klären. Zunächst möchten sie herausfinden, ob die Ideen der Expert:innen in dieser Studie wirklich deren beste Ideen waren. Dazu vergleichen sie die KI-Ideen mit angenommenen Arbeiten einer Top-Konferenz.
Außerdem wollen sie prüfen, ob die reine Bewertung von Ideen nicht zu subjektiv ist. Deshalb lassen sie als Nächstes einige der KI- und Mensch-Ideen zu kompletten Projekten ausarbeiten.
Spannend wäre ihrer Meinung nach auch eine Automatisierung der Ideenausführung. Dazu haben die Forschenden bereits einen Code generierenden KI-Agenten entwickelt - allerdings mit Schwächen bei der Implementierung.
Es gibt bereits konkrete Beispiele, in denen generative KI einen Beitrag zur Forschung leistet oder die Entwicklung beschleunigt, wie im KI-Beschleuniger der in Pixel-Smartphones verbauten Google-Chips. Auch in der Medizin ist der Einsatz von KI teils erfolgreich.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.