KI-Modelle lassen sich von Fail-Videos in die Irre führen

YouTube-Fail-Videos entlarven eine Schwäche führender KI-Systeme. Die Modelle fallen auf unerwartete Wendungen herein und können nicht umdenken. Selbst GPT-4o versagt bei simplen Überraschungen.
Die Wissenschaftler:innen der University of British Columbia, dem kanadischen Vector Institute for AI und der singapurischen Nanyang Technological University haben führende KI-Modelle mit mehr als 1.600 YouTube-Fail-Videos aus dem Oops!-Dataset getestet.
Der Benchmark BlackSwanSuite zeigt: Die Systeme fallen regelmäßig auf die gleichen "Tricks" herein, die auch Menschen überraschen, nur dass die KI anschließend nicht umdenken kann.
Ein typisches Beispiel: Ein Mann schwingt ein Kissen in Richtung Weihnachtsbaum. Die KI vermutet, er wolle eine andere Person treffen. Tatsächlich fliegen aber Christbaumkugeln durch die Luft und treffen eine Frau. Selbst nachdem die KI das komplette Video gesehen hat, beharrt sie auf ihrer ursprünglichen falschen Vermutung.
Die Videos stammen aus verschiedenen "Fail"-Kategorien, zum größten Teil sind es Verkehrsunfälle (24 Prozent), Kinder-Missgeschicke (24 Prozent) oder Pool-Pannen (16 Prozent). Gemeinsam haben sie alle eine unerwartete Wendung, die in der Regel selbst Menschen nicht vorhersehen können.
Jedes Video wird für den Benchmark in drei Teile zerlegt: das Set-up, das überraschende Ereignis und die Folgen. Die KI muss dann verschiedene Aufgaben lösen.
Tests mit drei verschiedenen Aufgaben
Bei "Forecaster" sieht die KI nur den Anfang und soll vorhersagen, was passiert. "Detective" zeigt Anfang und Ende, die KI muss die überraschende Wendung dazwischen erklären. "Reporter" zeigt alles und testet, ob die KI ihre ursprünglichen Vermutungen korrigieren kann.

Die Forschenden testeten sowohl geschlossene Modelle wie GPT-4o und Gemini 1.5 Pro als auch Open-Source-Systeme wie LLaVA-Video, VILA, VideoChat2 und VideoLLaMA 2.
Die Testergebnisse zeigen dramatische Schwächen. Bei der Detective-Aufgabe erreichte GPT-4o nur 65 Prozent richtige Antworten. Menschen schafften 90 Prozent.
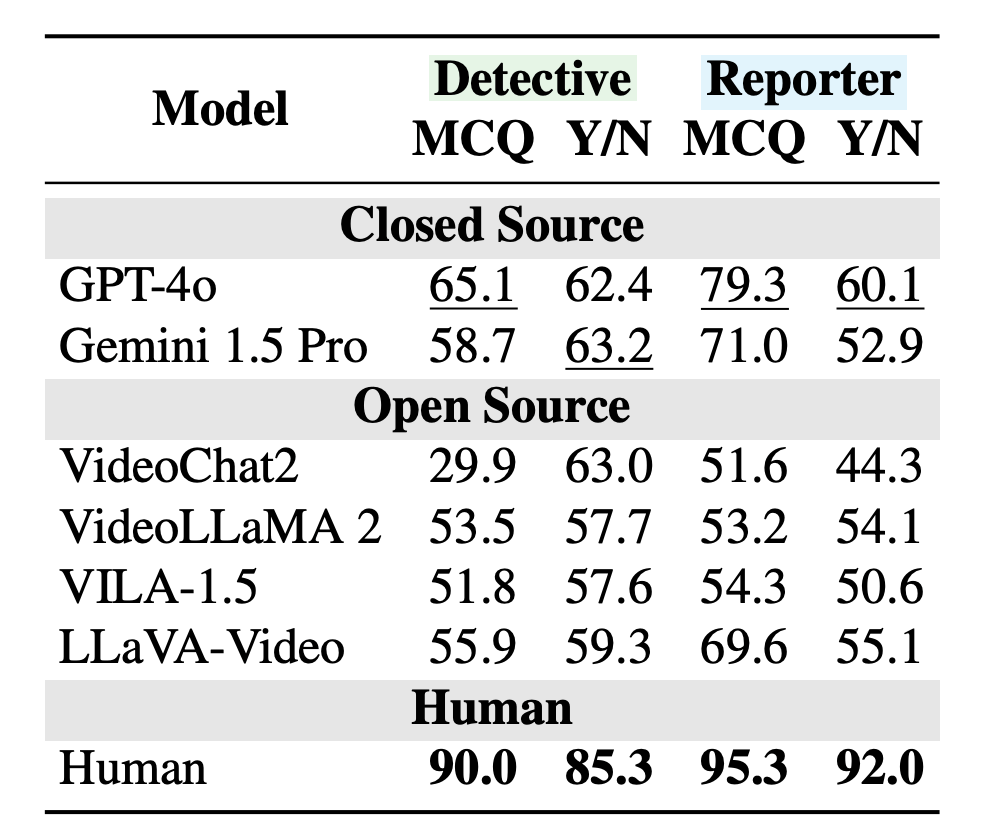
Noch schlechter wurde es beim "Umdenken": Wenn die KI ihre ursprünglichen Vermutungen anhand des kompletten Videos überprüfen sollte, lag GPT-4o mit 60 Prozent ganze 32 Prozentpunkte hinter Menschen (92 Prozent). Die Modelle halten stur an ihren ersten Eindrücken fest, auch wenn das Video das Gegenteil beweist.
Andere Modelle wie Gemini 1.5 Pro und LLaVA-Video zeigten ähnliche Probleme. Besonders bei den trickreichen Videos, die selbst Menschen erst beim zweiten Hinsehen verstehen, fiel die KI-Leistung der Untersuchung zufolge drastisch ab.
Müllwagen lassen keine Bäume fallen
Das Problem liegt in der Art, wie KI-Modelle trainiert werden. Sie lernen Muster aus Millionen von Videos und erwarten, dass sich diese Muster wiederholen. Ein Müllwagen hebt normalerweise Müll auf, aber dass er dabei einen Baum fallen lässt, passt nicht ins gelernte Schema.

Die Forschenden testeten, wo genau das Problem liegt. Sie ersetzten die KI-Wahrnehmung durch menschlich geschriebene Beschreibungen der Video-Inhalte. Dadurch verbesserte sich die Leistung von LLaVA-Video um 6,4 Prozent. Mit zusätzlichen Verständnishilfen kamen weitere 3,6 Prozent dazu, insgesamt 10 Prozent Verbesserung.
Das Paradoxe ist, dass diese Verbesserung die Schwäche der KI beweist. Wenn die Systeme erst dann richtig funktionieren, wenn Menschen ihnen die Wahrnehmungsarbeit abnehmen, dann scheitern sie bereits beim Sehen und Verstehen, noch bevor das eigentliche Denken beginnt.
Menschen dagegen seien Meister im Umdenken. Sie können ihre Vermutungen schnell anpassen, wenn neue Informationen auftauchen. Diese Flexibilität fehle aktuellen KI-Modellen.
Reale Welt voller Unversehbarkeiten
Die Fail-Video-Schwäche könnte ernste Konsequenzen für selbstfahrende Autos und andere autonome Systeme haben. In der realen Welt passieren schließlich ständig unerwartete Dinge: Kinder rennen auf die Straße, Gegenstände fallen von Lastwagen, andere Fahrer:innen verhalten sich unvorhersagbar.
Die Forschenden stellen ihren Benchmark auf Github und Hugging Face öffentlich zur Verfügung. Sie hoffen, dass andere Entwickler:innen damit ihre KI-Systeme testen und verbessern. Solange die Modelle sich von simplen Fail-Videos in die Irre führen lassen, seien sie für die echte Welt nicht bereit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.