KI-System "StreamDiT" generiert Livestream-Videos aus Textbeschreibungen

Ein neues KI-System namens StreamDiT kann Videos live aus Textbeschreibungen erstellen. Die Technologie könnte für Gaming und interaktive Medien relevant werden.
Wissenschaftler:innen von Meta und der University of California, Berkeley, haben in einem Paper ein System vorgestellt, das Videos in Echtzeit mit 16 Bildern pro Sekunde auf einer einzelnen High-End-GPU generiert. Das 4-Milliarden-Parameter-Modell produziert Videos mit 512p-Auflösung.
Der Hauptunterschied zu bisherigen Methoden liegt im Ansatz: Anstatt komplette Video-Clips zu erstellen und dann auszugeben, produziert StreamDiT Videos wie einen Live-Stream.
Video: Kodaira et al.
Die Wissenschaftler:innen demonstrierten verschiedene Einsatzmöglichkeiten: Das System kann minutenlange Videos in Echtzeit erstellen, auf interaktive Eingaben reagieren und sogar bestehende Videos in Echtzeit bearbeiten. In einem Beispiel verwandelten sie ein Schwein in einer Videosequenz in eine Katze, während der Hintergrund unverändert blieb.

Das System nutzt eine angepasste Architektur, die für Geschwindigkeit optimiert wurde. StreamDiT verwendet einen beweglichen Puffer, der mehrere Video-Frames gleichzeitig verarbeitet. Während das System an einem Frame arbeitet, bereitet es bereits die nächsten vor und gibt kontinuierlich fertige Bilder aus.
Dabei haben die Frames unterschiedliche Rauschpegel: Neue Frames sind stark verrauscht, während Frames kurz vor der Ausgabe fast vollständig bereinigt sind. Laut Paper benötigt das System etwa eine halbe Sekunde, um zwei Video-Frames zu erstellen, was nach der Verarbeitung acht fertige Bilder ergibt.
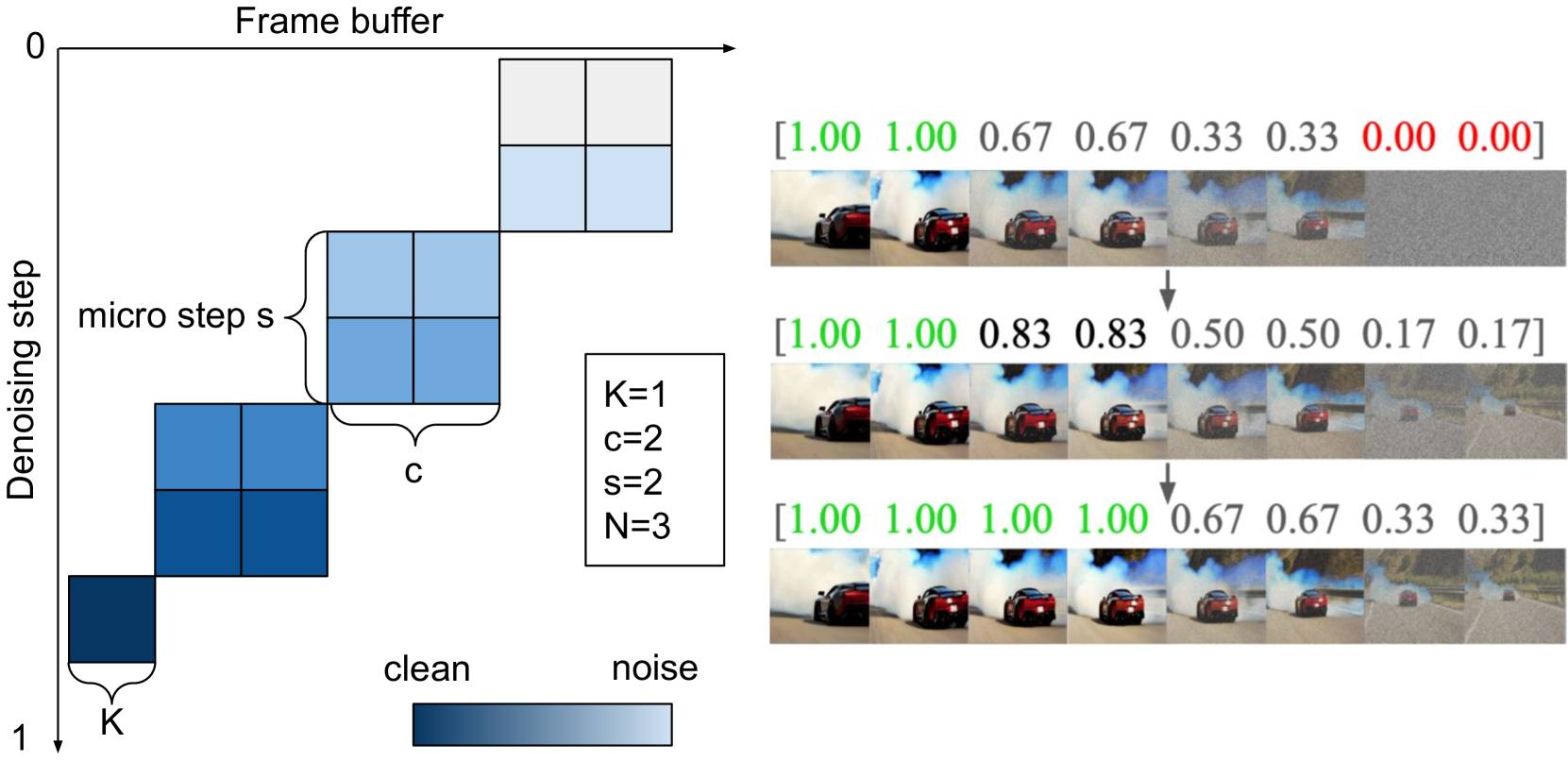
Vielseitiges Training verbessert Ergebnisse
Anstatt nur eine Art der Video-Erstellung zu lernen, wurde das Modell mit unterschiedlichen Ansätzen trainiert. Das soll verhindern, dass sich das System zu sehr auf eine bestimmte Methode festlegt und die Qualität der Videos verbessern. Das Training erfolgte in drei Stufen mit 3.000 hochwertigen Videos und einem größeren Datensatz mit 2,6 Millionen Videos.
Die Forschenden nutzten 128 Nvidia-H100-GPUs für das Training. Besonders wichtig war das gemischte Training: Das Team zeigt, dass eine Mischung verschiedener Chunk-Größen (von 1 bis 16 Bildern) die beste Qualität erzielt
Um die Echtzeit-Geschwindigkeit zu erreichen, entwickelten die Wissenschaftler:innen eine Beschleunigungstechnik. Diese reduziert die normalerweise nötigen Berechnungsschritte von 128 auf nur 8 Schritte, ohne die Bildqualität stark zu beeinträchtigen. Die Architektur wurde für Effizienz optimiert: Statt dass jedes Bildelement mit allen anderen "sprechen" muss, wurden lokale Bereiche geschaffen, die sich nur mit ihren Nachbarn austauschen.
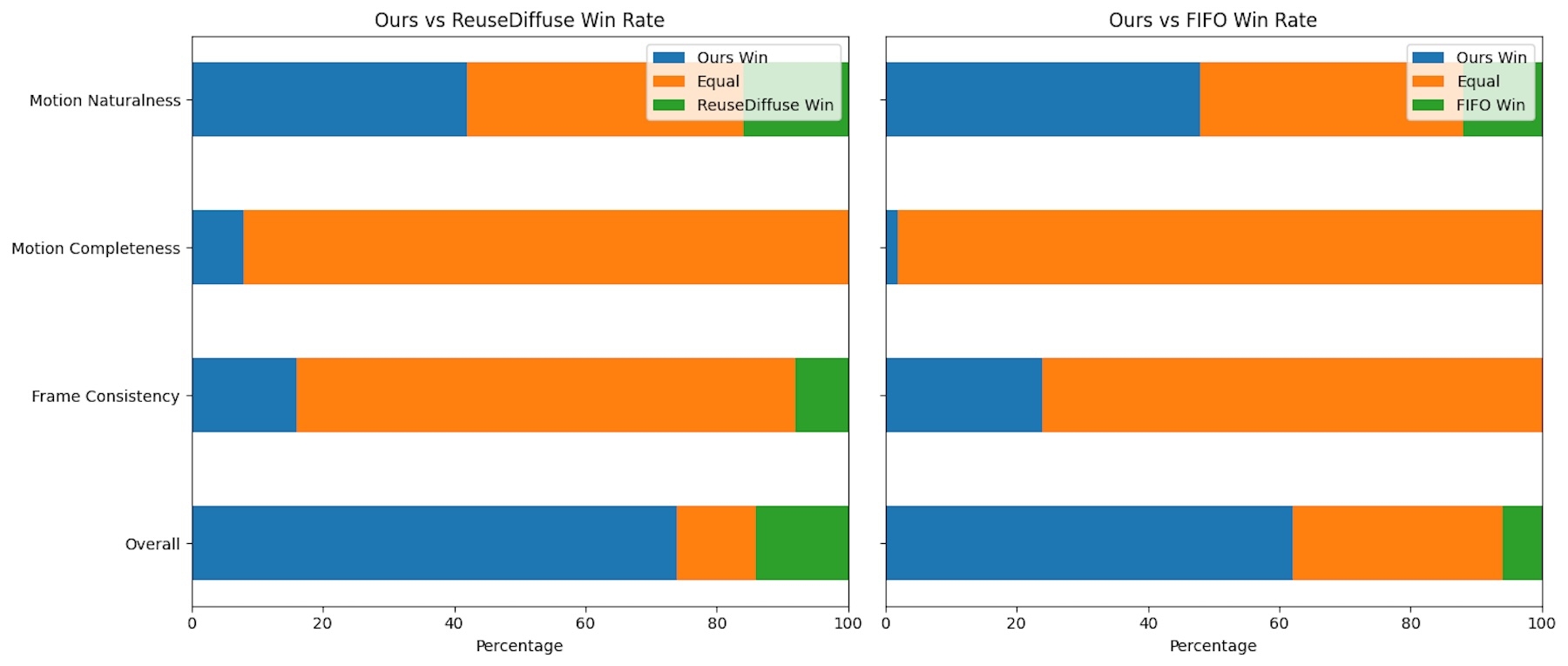
Tests zeigen bessere Ergebnisse bei bewegten Inhalten
Die Forschenden verglichen StreamDiT mit zwei anderen Methoden namens ReuseDiffuse und FIFO-Diffusion. Laut der Studie schnitt StreamDiT besonders bei Videos mit viel Bewegung deutlich besser ab. Während andere Methoden eher statische Inhalte produzierten, konnte StreamDiT dynamischere Videos erstellen.
Tests mit menschlichen Bewerter:innen bestätigten die Überlegenheit von StreamDiT in allen getesteten Bereichen: Gesamtqualität, Bildkonsistenz, Vollständigkeit der Bewegung und natürliche Bewegungen. Für die Tests generierten die Forschenden Acht-Sekunden-Videos mit 512p-Auflösung.
Erfolgreiche Tests mit größerem Modell
Die Forschenden testeten ihre Methode auch mit einem deutlich größeren Modell mit 30 Milliarden Parametern. Dieses produzierte erheblich bessere Qualität, ist aber zu langsam für Echtzeit-Anwendungen. Der Test zeigt jedoch, dass der Ansatz auch bei größeren Systemen funktioniert.
Zu den aktuellen Grenzen gehören die begrenzte "Erinnerung" des Systems an frühere Teile des Videos und mögliche sichtbare Übergänge zwischen verschiedenen Video-Abschnitten. Die Forscher sehen jedoch Lösungsansätze für diese Probleme vor.
Parallel zu StreamDiT treiben auch andere Unternehmen die Echtzeit-Interaktion mit KI-Videos voran: Odyssey hat kürzlich ein autoregressives Weltmodell entwickelt, das Videos frameweise an Nutzereingaben anpasst und so begehbare Erlebnisse schafft.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.