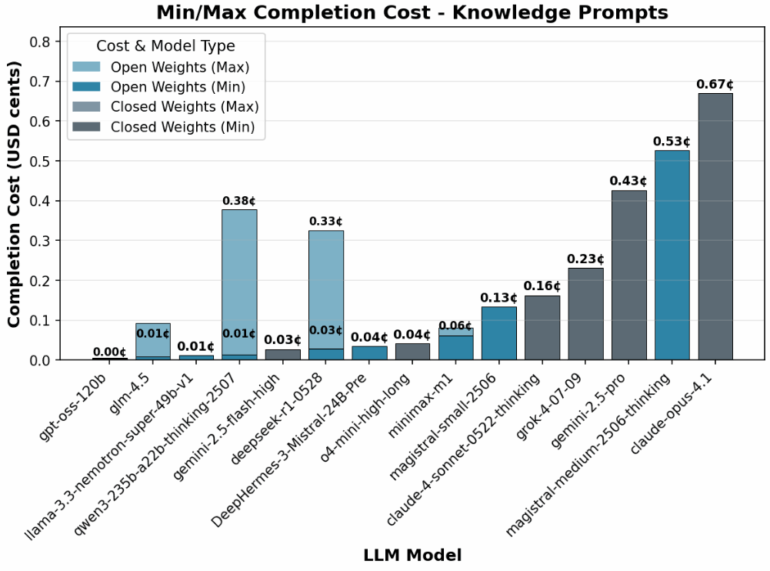
Sogenannte "Reasoning-Modelle" generieren deutlich mehr Wörter (Token), bevor sie antworten. Offene KI-Modelle benötigen dabei mitunter drei- bis viermal mehr Token als geschlossene Modelle wie Grok-4 oder OpenAI, zeigt eine Analyse von Nous Research. Besonders bei einfachen Wissensfragen produzieren offene Modelle unnötige Gedankenschritte, was trotz niedrigerer Tokenpreise zu höheren Gesamtkosten führen kann.
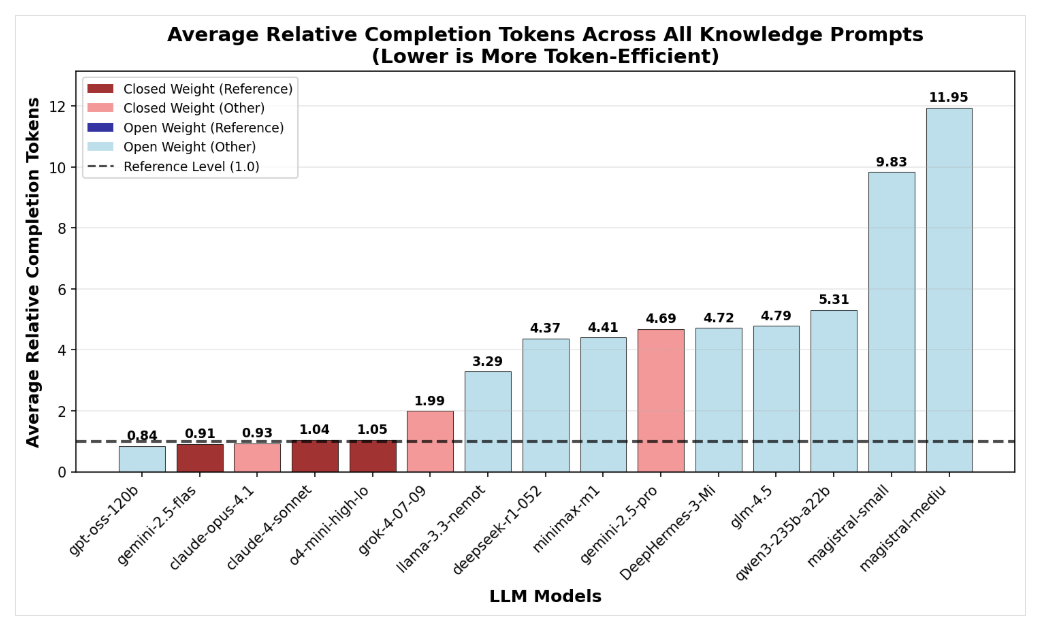
OpenAIs gpt-oss-120b zeige jedoch, dass auch Open-Source-Modelle mit sehr kurzen Denkpfaden effizient arbeiten können, insbesondere bei Mathematikaufgaben. Mistrals Magistral-Modelle hingegen fallen durch hohen Tokenverbrauch auf. Die Token-Effizienz hängt stark vom Aufgabentyp ab.