Künstliche Intelligenz schreibt Wiki-Biographien ignorierter Forscher

Bei Künstlicher Intelligenz wird häufig das Risiko von in Daten versteckter Vorurteile diskutiert. Ein neuer Ansatz zeigt, dass die Technologie Diskriminierung auch sichtbar machen und beseitigen kann.
Das Künstliche-Intelligenz-Startup Primer arbeitet an der auf Sprachverarbeitung spezialisierten KI "Quicksilver": Sie kann Texte lesen, Informationen aus ihnen extrahieren und eigenständig neue Texte generieren.
Primer trainierte die KI mit 30.000 englischsprachigen Wikipedia-Artikeln über Wissenschaftlerinnen und Wissenschaftler. Zusätzlichen Kontext lieferten Millionen Sätze aus redaktionellen Artikeln.
Im nächsten Schritt glich die KI mehr als 500 Millionen Nachrichten und wissenschaftliche Publikationen samt Zitationen mit englischsprachigen Wiki-Artikeln ab.
Dabei identifizierte sie rund 40.000 Wissenschaftler ohne Wikipedia-Eintrag, die nach Zitationen und Berichten gleichauf lagen mit Wissenschaftlern, die in der Wikipedia stehen. Außerdem erkannte sie in den vorhandenen Artikeln fehlende Inhalte.
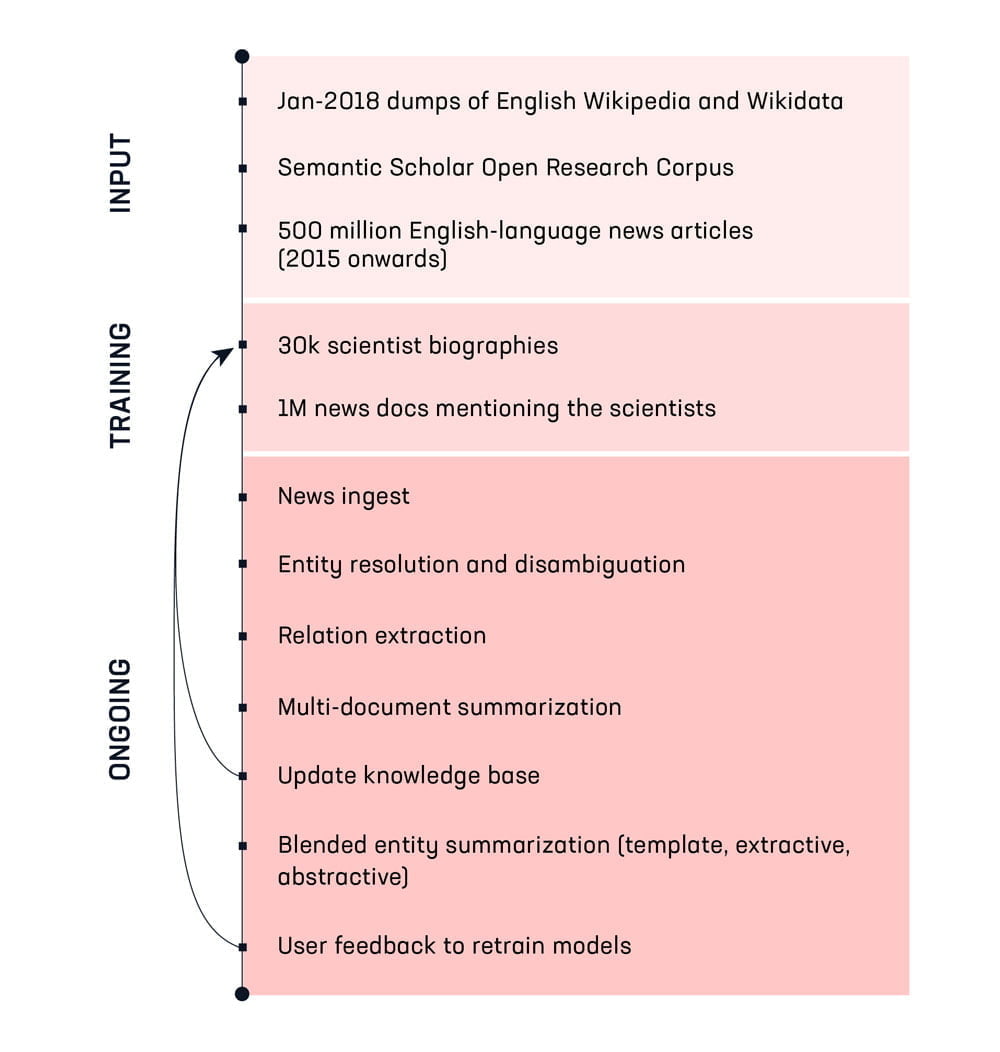
Insgesamt schrieb und ergänzte Quicksilver laut Primer rund 70.000 Biographien. Die Texte sind einfach formuliert und dienen als Grundlage für menschliche Ergänzungen. Ein Beispiel:
Adrian J. Luckman is a glaciologist at Swansea University.[12]
Luckman is a scientist with Swansea University located in Wales, UK.[4]Dr. Luckman has been working on the MIDAS project, a UK-based Antarctic research project, investigating the effects of a warming climate on the Larsen C ice shelf in Antarctica.[5]“The rift tip appears also to have turned significantly towards the ice front, indicating that the time of calving is probably very close,” Luckman and O’Leary wrote in a blog post for the Melt on Ice Shelf Dynamics and Stability project.[6]
Weitere 99 Beispiele sind hier einsehbar.
Einen möglichen Haken hat die Quicksilver-KI: Sie geht zumindest anteilig davon aus, dass die wissenschaftliche Relevanz einer Forscherin oder eines Forschers in Zusammenhang mit Medienberichten steht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.