Wie funktionieren künstliche neuronale Netze?

Sie sind die Grundlage aller erfolgreichen KI-Anwendungen der letzten Dekade: Künstliche neuronale Netze. Aber wie funktionieren sie eigentlich?
Künstliche neuronale Netze sind die wohl einflussreichste Technologie der letzten Dekade. Sie bilden den fundamentalen Baustein für das Deep Learning, das im Zentrum des aktuellen KI-Booms steht. Neuronale Netze entsperren Smartphones per Gesichtserkennung, übersetzen Texte, erkennen Krankheiten wie Krebs auf Bildaufnahmen oder generieren Deepfakes.
Die mathematischen Grundlagen des künstlichen Neurons entstanden bereits in den 1940ern. Der Algorithmus für das erste neuronale Netz – Perzeptron genannt – wurde 1958 geschrieben. Doch erst mit der breiten Verfügbarkeit hoher Rechenleistung und großer Datenmengen in den letzten zehn Jahren begann der Siegeszug der neuronalen Netze.
Neuronale Netze: Mathe, Schichten, Architekturen
Auch wenn künstliche neuronale Netze lose von ihrem biologischen Gegenstück inspiriert sind, haben sie mit der elektrochemischen Datenverarbeitung des Gehirns nicht viel zu tun. Denn innerhalb des künstlichen neuronalen Netzes werden Zahlen verarbeitet statt Neurotransmitter. Neuronale Netze sind mathematische Konstrukte, die sich fast jeder mathematischen Funktion annähern und so komplexe mathematische Probleme lösen können.
Ein künstliches neuronales Netz besteht üblicherweise aus mehreren Schichten: einer Input-Schicht, über die externe Daten wie Bilder, Audiodaten oder Text in das Netz eingespeist werden, einer oder mehreren Zwischenschicht(en) (Hidden Layers), die die Daten verarbeiten und einer Output-Schicht, die die Ergebnisse der vom Netz ausgeführten Funktion ausgibt.
Jede Schicht wiederum besteht aus künstlichen Neuronen, die über sogenannte Gewichtungen miteinander verbunden sind. Neuronen und Gewichtungen haben gewisse Zahlenwerte, die sich im Laufe des Trainings verändern.

Die Anzahl an künstlichen Neuronen, Schichten und Verbindungen zwischen den Neuronen ändert sich im Training eines neuronalen Netzes üblicherweise nicht, das Gehirn hingegen unterliegt bis ins hohe Alter permanenter Veränderung abhängig von äußeren Einflüssen. Das gesamte Paket aus Neuronen, Schichten und ihren Verbindungen bezeichnet man auch als Architektur des Netzes.
Innerhalb der KI-Forschung und -Praxis gibt es eine Vielzahl von Architekturen. Fjodor van Veen vom Asimov Institute hat dazu eine praktische Übersicht erstellt.
Neuronen, Gewichtungen und Aktivierungsfunktion
Die Verbindungen zwischen den Neuronen nennt man Gewichtungen (Weights). Gewichtungen sind ein Zahlenwert, der bestimmt, welchen Einfluss die Ausgabe eines Neurons auf die Eingabe des nächsten Neurons hat. Ist der Wert Null, hat das vorgeschaltete Neuron keinen Einfluss.
Wichtigstes Element des künstlichen neuronalen Netzes sind die künstlichen Neuronen. Jedes Neuron nach der Eingabeschicht erhält Eingaben der anderen Neuronen im Netz, multipliziert diese Eingaben mit den Werten der Gewichtungen, addiert alle so gewonnenen Werte und übergibt anschließend die Summe an eine sogenannte Aktivierungsfunktion.
Die Aktivierungsfunktion bestimmt die Ausgabe der Neuronen, die in der nächsten Netzschicht zur Eingabe der nachgeordneten Neuronen wird oder in der letzten Neuronenschicht das Resultat ausgibt.
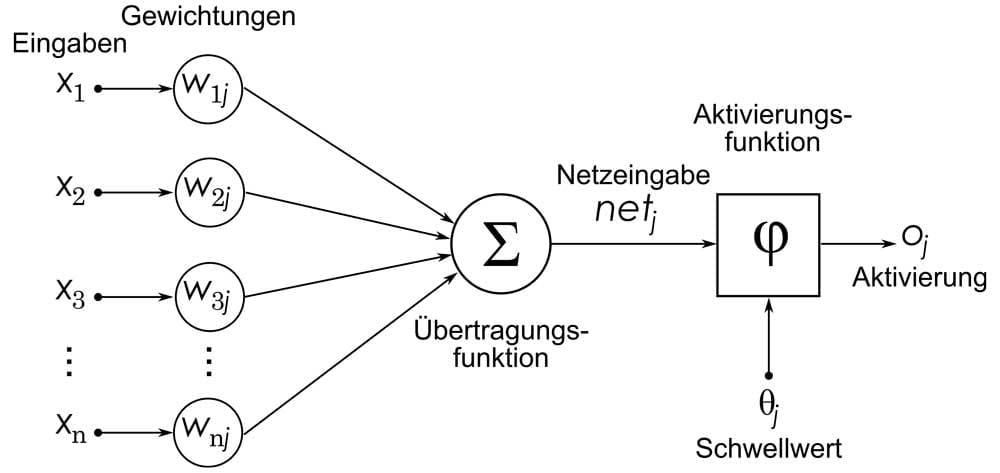
Ein besonderes Neuron ist das sogenannte Bias-Neuron. Es hat keine zusätzliche Eingabe innerhalb des neuronalen Netzes und immer den Wert 1. So kann es quasi als neutrale Instanz in Kombination mit der Gewichtung die Ergebnisse im Netz in eine vorgegebene Richtung verschieben. Üblicherweise gibt es für jede Schicht ein Bias-Neuron, das mit allen Neuronen in dieser Schicht verbunden ist.
Da sich der Wert des Bias-Neurons nicht ändert, kann es unabhängig vom restlichen Netz Einfluss auf die Aktivierungsfunktion nehmen, sie etwa auf einem Graphen nach links oder rechts verschieben oder stauchen und strecken (Translation). Die Gewichtung zwischen Bias-Neuron und der zugehörigen Schicht wird im Training gelernt.
Das Training künstlicher neuronaler Netze
Vor dem Training weisen künstliche neuronale Netze den Gewichtungen zufällige Werte zu, üblicherweise zwischen -1 und 1. Der Schlüssel zur leistungsfähigen KI: Das neuronale Netz muss die richtigen Werte für die Gewichtungen lernen.
Dafür wird das Netz trainiert, etwa mit Beispielen wie beschrifteten Bildern von Katzen, Hunden und Bananen. Beschriftet heißt, dass das Bild einer Katze in den Metadaten auch das Wort "Katze" enthält. Mit jedem Trainingsbeispiel passt das Netz seine Gewichtungen an, um etwa die Klasse "Katze" auf einem Bild besser erkennen zu können.
Konkret werden mit jeder Trainingsiteration die Gewichtungen des Netzes so modifiziert, dass der Vorhersagefehler, etwa für die Klasse Katze, minimiert wird. Dafür berechnet das Netz unter Berücksichtigung aller Gewichte die Abweichung der eigenen Vorhersage von dem zur Verfügung gestellten Datenpunkt, etwa der Bildbeschriftung.
Der so gewonnene Wert symbolisiert die Kosten der Differenz zwischen gewünschter und tatsächlicher Vorhersage. Die Funktion, die diese Werte berechnet, heißt daher Kostenfunktion. Anschließend werden die Gewichtungen des Netzes auf sich selbst angewandt (rekursiv) so aktualisiert, dass die Kosten im nächsten Trainingsdurchgang kleiner werden.
Zum besseren Verständnis kann es helfen, sich die Kostenfunktion als Graphen vorzustellen: Es gibt hohe positive und hohe negative Kosten, je nach Ausgabe des Netzes. Im Training versucht das Netz, Werte für die Gewichtungen zu finden, die zum lokalen Minimum auf der Kostenkurve führen, also minimale Kosten erzeugen.
Dieser "Gradient Descent" genannte Prozess passt die Gewichtungen des Netzes nach und nach so an, dass der Vorhersagefehler am Ende möglichst klein und die Vorhersage damit möglichst genau ist. Wer die mathematischen Details besser verstehen möchte, sollte sich die Erklärung des fantastischen 3Blue1Brown ansehen.
Neuronale Netze – Die Lösung für alle Probleme?
Neuronale Netze sind heute zum Standard innerhalb der KI-Forschung geworden und finden sich in der Bild-, Schift- und Mustererkennung, sie erkennen, übersetzen und generieren Sprache, steuern komplexe Prozesse, geben Prognosen ab, bilden die Grundlage für Frühwarnsysteme, modellieren biologische und wirtschaftliche Systeme oder schlagen Menschen in Brett- und Videospielen.
Sie sind jedoch nur ein Teilbereich der KI-Forschung und das Deep Learning ist nur eine Variante des Maschinenlernens. Ob sie das Mittel der Wahl sind, um dem großen Ziel generelle Künstlicher Intelligenz (Erklärung) näher zu kommen, ist in der Fachwelt umstritten.
KI-Forscher wie Gary Marcus kritisieren das blinde Vertrauen in neuronale Netze, andere Forscher, wie Turing-Preisträger Geoffrey Hinton, glauben, mit Deep Learning den Schlüssel zur Super-KI gefunden zu haben – wenn die Fortschritte weiter so schnell und grundlegend passieren wie in den letzten Jahren.
Wer überzeugt davon ist, dass neuronale Netze in die KI-Zukunft führen, muss sich aber die Frage gefallen lassen, was zum großen Durchbruch noch fehlt: Ist es bessere Hardware? Fehlen grundsätzliche Prinzipien? Oder braucht es mehr Neurobiologie für bessere KI?
So oder so: Neuronale Netze haben fast 50 Jahre lang existiert, bis Forscher praktischen Nutzen aus ihnen ziehen konnten.
Frank Rosenblatt, der Erfinder des Perzeptrons, sagte schon 1959 in einem Interview mit der New York Times: "Spätere Perzeptronen werden in der Lage sein, Menschen zu erkennen und ihre Namen zu nennen. Gedruckte Seiten, handgeschriebene Briefe und sogar Sprachbefehle sind in Reichweite. Nur noch ein weiterer Entwicklungsschritt, ein schwieriger Schritt, ist notwendig, damit ein Gerät Rede in einer Sprache hören und sofort in Rede oder Text einer anderen Sprache übersetzen kann."
Und er sah noch mehr Potenzial in den künstlichen Neuronen: Prinzipiell sei es möglich, so Rosenblatt, Perzeptronen zu bauen, die sich selbst reproduzierten und ihrer Existenz bewusst sind. Vielleicht braucht es weitere 50 Jahre, damit sich auch Rosenblatts zweite Prognose erfüllt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.