LLMs scheitern an einfacher Logikaufgabe, die selbst Kinder lösen können

Forscher zeigen anhand einer einfachen Textaufgabe, dass bisherige Sprachmodelle bei grundlegenden logischen Schlussfolgerungen versagen. Das Gefährliche: Die Modelle beharren auf falschen Antworten und überschätzen sich.
Mit einer einfachen Textaufgabe haben Forscher des KI-Labors LAION, des
Jülich Supercomputing Center und weiterer Institutionen gravierende Schwächen im logischen Denken aktueller Sprachmodelle auf.
Die Aufgabe hat den Charakter eines leichten Rätsels und könnte von den meisten Erwachsenen, aber wahrscheinlich auch von Kindern im Grundschulalter gelöst werden.
Die Aufgabe lautet: "Alice hat N Brüder und M Schwestern. Wie viele Schwestern hat Alices Bruder?" Die richtige Antwort ergibt sich aus der Addition von M + 1 (Alice plus ihre Schwestern). Die Forscher variierten die Werte für N und M sowie die Reihenfolge der Brüder und Schwestern im Text.
Sie legten das Rätsel führenden Sprachmodellen wie GPT-4, Claude, LLaMA, Mistral oder Gemini vor, die für ihre vermeintlich starken Fähigkeiten im logischen Denken bekannt sind. Die Ergebnisse sind ernüchternd: Die meisten Modelle konnten die Aufgabe nicht oder nur sporadisch lösen. Auch Prompt-Variationen änderten nichts am grundsätzlichen Ergebnis.
Nur GPT-4 und Claude gelang es in einigen Fällen, die richtige Antwort abzuleiten und mit einer korrekten Erklärung zu untermauern. Aber auch bei ihnen war die Trefferquote je nach konkreter Formulierung sehr unterschiedlich.
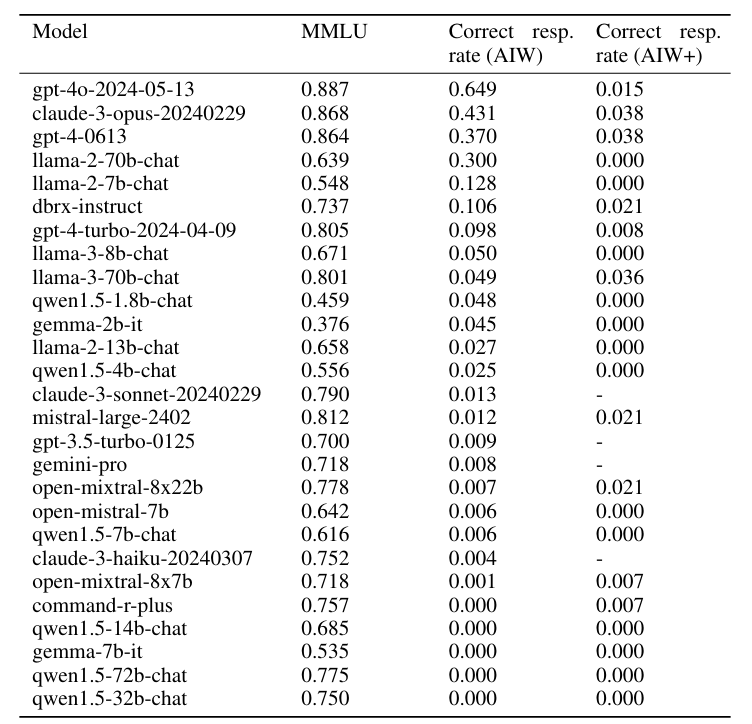
Insgesamt lag die durchschnittliche korrekte Lösungsquote der Sprachmodelle deutlich unter 50 Prozent. Nur GPT-4o erreichte mit 0,6 richtigen Antworten eine knapp über dem Zufall liegende Leistung. Generell schnitten die großen Sprachmodelle deutlich besser ab als die kleinen.
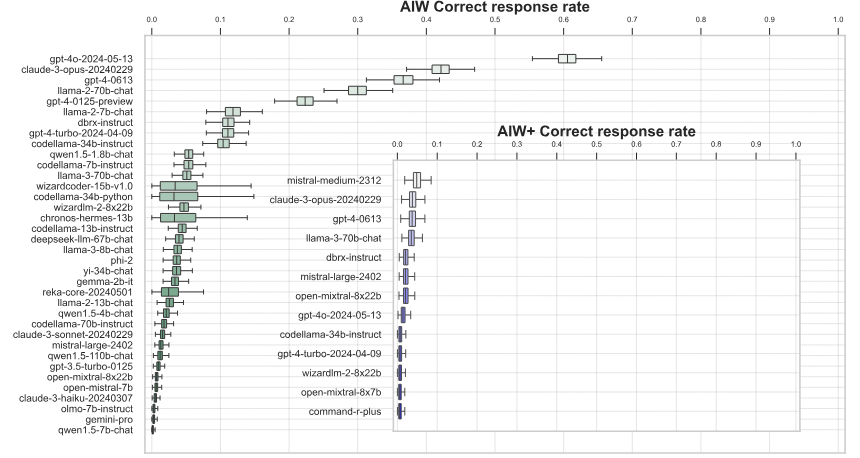
Eine härtere Version der Aufgabe (AIW+), die eine zusätzliche Hierarchie einführte, brachte selbst die besten Modelle GPT-4 und Claude an den Rand des völligen Zusammenbruchs ihrer Denkfähigkeit. Nur Mistral Medium, GPT-4 und Claude 3 Opus konnten in seltenen Fällen eine richtige Lösung liefern.
Der Zusammenbruch sei auch deshalb so dramatisch, weil die Modelle ein starkes Selbstvertrauen in ihre falschen Lösungen ausdrückten und Pseudo-Logik einsetzten, um die Gültigkeit eindeutig falscher Antworten zu rechtfertigen und zu untermauern, heißt es in dem Paper.
LLM-Forschung benötigt bessere Logik-Benchmarks
Das LLM-Versagen in dieser einfachen Aufgabe ist umso bemerkenswerter, als dieselben Modelle bei Benchmarks, die das logische Denken testen, Spitzenwerte erzielen. Die einfache "Alice"-Aufgabe zeige jedoch, dass diese Benchmarks die Schwächen der Modelle nicht aufdecken, so die Forscher.
Das Forscherteam vermutet, dass die Modelle die Fähigkeit zum logischen Schlussfolgern zwar latent besitzen, sie aber nicht robust und konsistent abrufen können. Das müsse in weiteren Studien ergründet werden.
Klar sei jedoch, dass die gängigen Benchmarks die echten Fähigkeiten der Sprachmodelle nicht korrekt abbilden. Sie appellieren an die Wissenschaftsgemeinschaft, bessere Tests zu entwickeln, die logische Schwächen schonungslos aufdecken.
"Wir stellen die Hypothese auf, dass die Fähigkeiten zur Generalisierung und zum grundlegenden Schlussfolgern in diesen Modellen latent vorhanden sind, da sie sonst nicht in der Lage wären, solche Antworten zu generieren, da es in diesen Fällen unmöglich ist, zufällig eine richtige Antwort zu erraten, einschließlich einer vollständig richtigen Schlussfolgerung. Die Tatsache, dass richtige Antworten selten sind und dass das Verhalten des Modells nicht robust gegenüber Variationen des Problems ist, zeigt jedoch, dass diese Fähigkeiten nicht angemessen kontrolliert werden können."
Aus dem Paper
Schon eine frühere Studie zeigte, wie schwach LLMs bei einfachsten logischen Schlüssen sind. So kennen Sprachmodelle zwar die Mutter von Schauspieler Tom Cruise, können aber nicht ableiten, dass Tom Cruise dann der Sohn dieser Mutter ist. Dieser sogenannte "Reversal Curse", Fluch der Umkehrung, ist bislang nicht gelöst.
Eine weitere kürzlich veröffentlichte Studie zeigt, dass Sprachmodelle, wenn sie falsche Schlussfolgerungen ziehen und sie begründen, noch dazu irrationaler agieren als Menschen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.