
Forschende haben die Rationalität von sieben großen KI-Sprachmodellen mit kognitiven Tests aus der Psychologie untersucht.
Können KI-Sprachmodelle rational denken? Eine Studie von Forschenden der University College London hat dies anhand von kognitiven Tests aus der Psychologie untersucht. Getestet wurden sieben große Sprachmodelle, darunter GPT-3.5 und GPT-4 von OpenAI, LaMDA von Google, Claude 2 von Anthropic und drei Versionen von Meta's Llama 2.
Die verwendeten Tests wurden ursprünglich entwickelt, um kognitive Verzerrungen und Heuristiken im menschlichen Denken aufzuzeigen. Menschen beantworten die Aufgaben oft falsch, weil sie mentale Abkürzungen nehmen, anstatt streng logisch zu denken.
Die Forscher wollten wissen: Zeigen die KI-Modelle ähnlich irrationales Denken wie Menschen? Oder denken sie auf eine eigene Art unlogisch?
"Die Fähigkeiten dieser Modelle sind äußerst überraschend, besonders für Menschen, die seit Jahrzehnten mit Computern arbeiten," so Professor Mirco Musolesi, Autor der Studie. "Das Interessante ist, dass wir das emergente Verhalten von Large Language Models und warum und wie sie Antworten richtig oder falsch bekommen, nicht wirklich verstehen."
GPT-4 liegt häufiger richtig und macht menschenähnlichere Fehler
Die Antworten der Sprachmodelle wurden in zwei Dimensionen bewertet: richtig oder falsch und menschenähnlich oder nicht menschenähnlich. Eine menschenähnlich falsche Antwort ist eine Antwort, die den gleichen kognitiven Fehler macht wie Menschen. Eine nicht-menschlich falsche Antwort ist auf eine andere Weise unlogisch.
Das Ergebnis: KI-Modelle "denken" oft irrational - aber anders als Menschen. Die meisten falschen Antworten waren nicht menschenähnlich, sondern auf ihre Weise unlogisch. Manchmal war die Erklärung richtig, aber die Schlussfolgerung falsch. Oft gab es mathematische Rechenfehler oder Verstöße gegen Logik und Wahrscheinlichkeitsregeln. Außerdem war ihre Leistung inkonsistent: Dasselbe Modell gab oft völlig unterschiedliche Antworten auf dieselbe Aufgabe. Mal richtig, mal falsch, mal logisch, mal unlogisch.
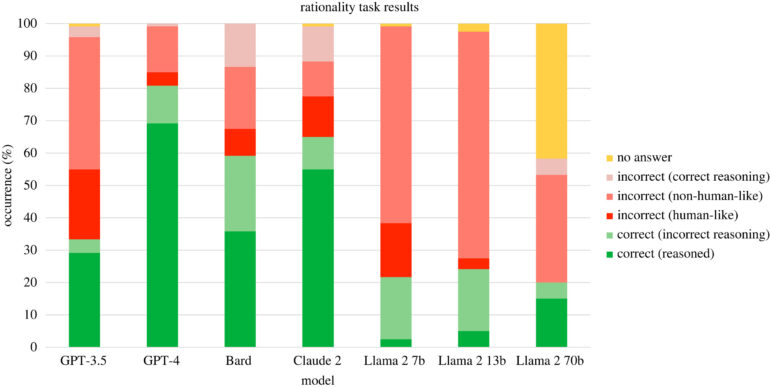
Insgesamt schnitt GPT-4 von OpenAI am besten ab. Es gab in 69,2% der Fälle richtige Antworten mit richtigen Erklärungen. Gefolgt von Claude 2 mit 55%. Am schlechtesten schnitt Llama 2 von Meta mit 7 Milliarden Parametern ab - es lag in 77,5 % der Fälle falsch.
Laut der Studie war das Modell GPT-4 von OpenAI am menschenähnlichsten in seinen Antworten auf die kognitiven Aufgaben. GPT-4 gab in 73,3% der Fälle menschenähnliche Antworten (sowohl richtige als auch falsche).

Autoren rufen zu Vorsicht im Einsatz von Sprachmodellen in kritischen Bereichen auf
Die Autoren betonen, dass die meisten falschen Antworten der Sprachmodelle nicht auf menschenähnliche kognitive Verzerrungen zurückzuführen sind, sondern auf andere Fehler wie inkonsistente Logik oder falsche Berechnungen. Sie vermuten, dass die menschenähnlichen Verzerrungen in großen Sprachmodellen wie GPT-4 eher auf die Trainingsdaten als auf eine menschenähnliche Denkfähigkeit zurückzuführen sind.
Die inkonsistenten und teilweise irrationalen Ergebnisse werfen Fragen auf, wenn solche Systeme in kritischen Bereichen wie der Medizin eingesetzt werden sollen. Die Studie liefert eine Methodik, um die Rationalität von KI-Sprachmodellen zu bewerten und zu vergleichen. Dies könnte ein Ansatzpunkt sein, um die Sicherheit dieser Systeme in Bezug auf logisches Denken zu verbessern.
"Wir haben jetzt Methoden, um diese Modelle zu verfeinern, aber dann stellt sich eine Frage: Wenn wir versuchen, diese Probleme zu lösen, indem wir die Modelle trainieren, übertragen wir dann unsere eigenen Fehler? Das Faszinierende ist, dass diese LLMs uns dazu bringen, darüber nachzudenken, wie wir denken, was unsere eigenen Vorurteile sind und ob wir völlig rationale Maschinen wollen", sagt Musolesi. "Wollen wir etwas, das Fehler macht wie wir, oder wollen wir, dass sie perfekt sind?"



