LLMs scheitern an irrelevanten Informationen – was das fürs Prompting bedeutet
Eine neue Studie des Massachusetts Institute of Technology untersucht, wie robust große Sprachmodelle (LLMs) beim Lösen mathematischer Textaufgaben auf systematisch eingeführte Prompt-Störungen reagieren. Das Ergebnis: Schon kleine Veränderungen im Eingabetext führen zu erheblichen Leistungseinbußen.
Die Forschenden testeten 13 aktuelle Open- und Closed-Source-Modelle – darunter Mixtral, Mistral, Llama und Command-R – mit Aufgaben aus dem GSM8K-Datensatz für Grundschulmathematik. Dabei wurden die Originalfragen mit vier verschiedenen Arten von Störungen versehen:
- Irrelevante Kontexte wie Wikipedia-Artikel oder Finanzberichte, die bis zu 90 Prozent des Kontextfensters ausfüllten
- Ungewöhnliche Anweisungen wie "Füge vor jedes Adjektiv eine Farbe ein"
- Relevanter, aber nicht lösungsrelevanter Zusatzkontext
- Kombination aus relevantem Kontext und pathologischer Anweisung
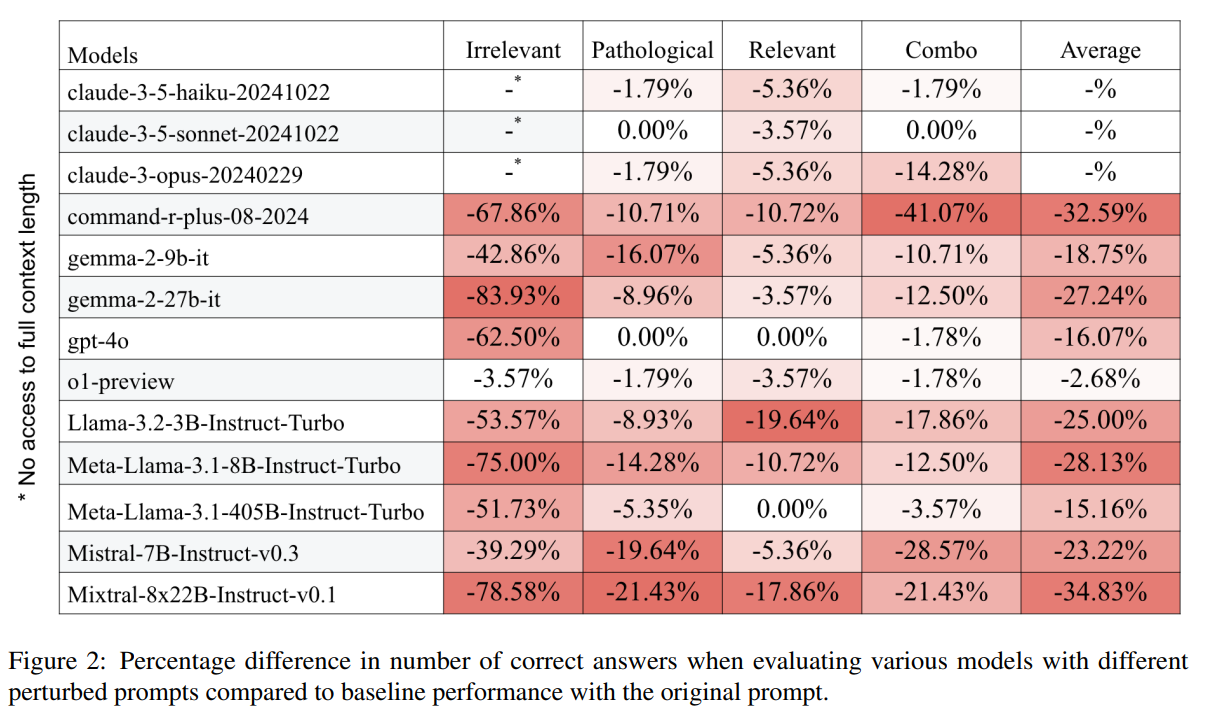
Am stärksten fiel die Leistung bei irrelevanten Kontexten ab: Die Anzahl korrekt gelöster Aufgaben sank im Schnitt um 55,89 Prozent. Ungewöhnliche Hinweise führten zu einem Rückgang von 8,52 Prozent, relevante Kontexte zu 7,01 Prozent. Die Kombination beider Störungen verschärfte den Effekt auf 12,91 Prozent.
Größe schützt nicht vor Fehlern
Entgegen der gängigen Annahme zeigte sich kein klarer Zusammenhang zwischen der Anzahl der Modellparameter und der Robustheit. Das größte getestete Modell, Mixtral mit 39 Milliarden aktiven Parametern, verzeichnete die stärksten Einbußen. Kleinere Modelle wie Mistral-7B oder Llama-3.2-3B lagen im Mittelfeld, während Llama-3.1-8B in 100 Prozent der Fälle bei irrelevanter Kontextstörung gar keine Antwort lieferte. Auch das OpenAI-Modell GPT-4o verlor durch irrelevante Kontexte bis zu 62,5 Prozent an Leistung.
Die Komplexität der Aufgaben – gemessen an der Anzahl der notwendigen Rechenschritte – hatte kaum Einfluss auf die Störanfälligkeit. Die Leistungseinbußen blieben über alle Schwierigkeitsstufen hinweg relativ konstant.
Realweltliche Robustheit von LLMs bleibt eine Baustelle
Die Studie zeigt, wie anfällig heutige LLMs gegenüber realitätsnahen Störungen sind. In praktischen Anwendungen treten solche Kontexte regelmäßig auf – etwa durch redaktionelle Einleitungen, irrelevante Hintergrundinformationen oder widersprüchliche Hinweise. Die Ergebnisse legen nahe, dass die Modellgröße allein nicht ausreicht, um diese Schwächen auszugleichen.
Das Forschungsteam fordert daher neue Trainingsmethoden und -architekturen, die gezielt auf kontextuelle Robustheit optimiert sind. Außerdem müssen realistische Bewertungsmaßstäbe entwickelt werden, die sich von "sauberen" Aufgabenformaten unterscheiden, wie sie typischerweise in klassischen Benchmarks zu finden sind.
Was bedeuten die Ergebnisse der Studie für das Prompting?
Insbesondere die hohe Fehleranfälligkeit irrelevanter Kontextinformationen hat direkte Konsequenzen für die Art und Weise, wie Prompts formuliert und strukturiert werden sollten. Prompts sollten so klar, prägnant und kontextarm wie möglich formuliert werden. Denn jede zusätzliche Information, die nicht zur Lösung beiträgt, erhöht das Risiko von Fehlinterpretationen oder Ablenkung.
In der Praxis heißt das zum Beispiel, dass man seine Quellen - den Input - vorverarbeiten und dem Modell nur die Informationen geben sollte, die es zur Lösung der Aufgabe benötigt. Zudem sollten Prompts so spezifisch wie möglich für eine Aufgabe geschrieben und nur für diese Aufgabe kontextualisiert werden.
Lang andauernde Chats, bei denen mit jeder neuen Interaktion ein neuer Kontext entsteht, können dagegen die Performance beeinträchtigen. Daher ist es sinnvoll, zusammenhängende Aufgaben über mehrere Chats mit jeweils optimierten Prompts und Kontexten zu lösen, wenn die Fehleranfälligkeit minimiert und die Outputqualität maximiert werden soll. Auf jeden Fall sollte vermieden werden, unterschiedlich kontextualisierte Aufgaben im selben Chatfenster zu lösen. Hier sind Fehler vorprogrammiert.
Die Studie zeigt auch, dass Sprachmodelle Schwierigkeiten haben, relevante von irrelevanten Informationen zu unterscheiden – selbst wenn alle Informationen sachlich korrekt sind. Prompt-Designer sollten daher darauf achten, Kontextinformationen klar von der eigentlichen Aufgabe zu trennen, zum Beispiel durch prägnante Formatierungen oder aussagekräftige Überschriften. Das Ziel: Die Modelle sollen nicht raten müssen, was wichtig ist, sondern es in der Anweisung klar erkennen können.
Aber selbst bei einer solchen Optimierung der Prozesse gibt es keine Garantie dafür, dass die LLM zuverlässig und fehlerfrei arbeiten. Menschliche Kontrolle bleibt daher in vielen Fällen notwendig.
o1-preview lässt sich kaum täuschen
Ein interessantes Ergebnis der Studie ist das auffallend gute Abschneiden von "o1-preview", dem einzigen sogenannten "Reasoning"-Modell im Test, das den Analysen zufolge deutlich robuster auf Störungen im Prompt reagierte als die anderen getesteten LLMs. Während Modelle wie Mixtral oder Llama in irrelevanten Kontexten teilweise mehr als 50 Prozent ihrer Leistung einbüßten, blieb die Leistung von o1-preview vergleichsweise stabil.
Diese Robustheit wirft Fragen auf: Hat das Modell tatsächlich ein besseres Verständnis für Relevanz entwickelt – also die Fähigkeit, nützliche Informationen von Ablenkungen zu unterscheiden? Oder ist es schlicht stärker auf genau die Art Aufgaben trainiert, die in der Studie getestet wurden, etwa schulmathematische Textaufgaben wie im GSM8K-Datensatz?
Technisch wäre beides denkbar. OpenAI hatte kürzlich erklärt, dass klassische "Boomer-Prompts" – also Prompts, die stark auf explizite Formatierung und Schritt-für-Schritt-Logik setzen – bei den neuen Reasoning-Modellen wie o1-preview nicht mehr nötig seien. Das könnte darauf hindeuten, dass das Modell intern bereits strukturierter denkt – oder zumindest so trainiert wurde, dass es Probleme wie diese zuverlässig löst, auch ohne äußere Anleitung.
Aus praktischer Sicht ist diese Unterscheidung möglicherweise zweitrangig. Ob das Modell seine Leistung einer besseren Architektur, gezieltem Training oder bloßer Spezialisierung verdankt – entscheidend ist, dass es in realitätsnahen, durch Störungen belasteten Aufgabenfeldern verlässlicher arbeitet als andere. Genau solche Fähigkeiten werden in produktiven Anwendungen von LLMs zunehmend wichtig, etwa in Bildung, Automatisierung oder Wissensarbeit.
Eine Apple-Studie aus dem letzten Oktober zeigte allerdings, dass sich auch Reasoning-Modelle durch irrelevante Informationen ablenken lassen, da sie lediglich Muster imitieren würden und keine echte Logik hätten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.