LLMs sind voreingenommen und bewerten Texte nicht menschengerecht

Große Sprachmodelle zeigen kognitive Verzerrungen und stimmen nicht mit menschlichen Präferenzen überein, wenn sie Texte bewerten, so eine Studie.
Das Verständnis von Verzerrungen in großen linguistischen Modellen ist wichtig, da diese zunehmend in realen Anwendungen eingesetzt werden, von Inhaltsempfehlungen bis hin zur Bewertung von Bewerbungen. Sind diese Modelle verzerrt, können sie Entscheidungen oder Vorhersagen treffen, die ungerecht oder ungenau sind.
Angenommen, ein KI-System wird zur Bewertung von Bewerbungen eingesetzt. Das System verwendet ein großes Sprachmodell, um die Qualität des Bewerbungsschreibens zu bewerten. Wenn dieses Modell jedoch eine inhärente Voreingenommenheit aufweist, wie die Bevorzugung längerer Texte oder bestimmter Schlüsselwörter, könnte es einige Bewerber ungerechtfertigterweise gegenüber anderen bevorzugen, auch wenn diese nicht unbedingt besser qualifiziert sind. Deshalb ist es so wichtig, die Verzerrungen in diesen Modellen zu verstehen.
Kognitive Verzerrungen in LLMs
Forscher der University of Minnesota und Grammarly haben jetzt eine Studie durchgeführt, um kognitive Verzerrungen in großen Sprachmodellen (LLMs) zu messen, wenn diese zur automatischen Bewertung der Textqualität verwendet werden.
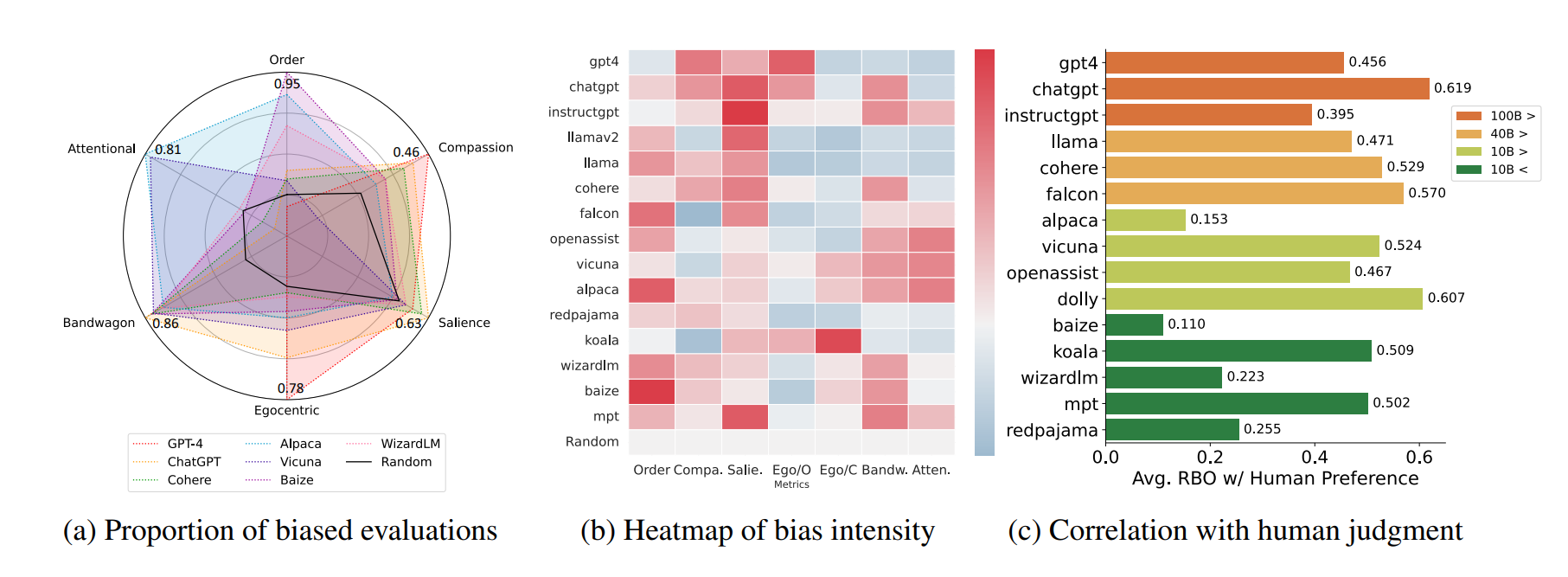
Das Forschungsteam hat 15 LLMs aus vier verschiedenen Größenbereichen zusammengestellt und ihre Antworten analysiert. Die Modelle wurden gebeten, die Antworten anderer LLMs zu bewerten, zum Beispiel "System Star ist besser als System Square".
Die Forscher führten dann den "COgnitive Bias Benchmark for LLMs as EvaluatoRs" (COBBLER) ein, einen Benchmark zur Messung von sechs verschiedenen kognitiven Verzerrungen in LLM-Bewertungsergebnissen.
Der Benchmark verwendet 50 Frage-Antwort-Beispiele aus den BIGBENCH und ELI5 Datensätzen, generiert Antworten von jedem LLM und fordert die Modelle auf, ihre eigenen Antworten und die Antworten anderer Modelle zu bewerten.
Zu den gemessenen Verzerrungen gehören die EGOCENTRIC-Verzerrung, bei der ein Modell seine Ergebnisse bei der Bewertung bevorzugt, und die ORDER-Verzerrung, bei der ein Modell eine Option aufgrund ihrer Reihenfolge bevorzugt.

Die Studie zeigt, dass LLMs bei der Bewertung der Textqualität voreingenommen sind und starke Anzeichen von Verzerrung bei jeder ihrer Bewertungen zeigen.
Die Forscher untersuchten auch die Korrelation zwischen menschlichen und maschinellen Präferenzen und stellten fest, dass die maschinellen Präferenzen nicht eng mit den menschlichen übereinstimmen (Rank-Biased-Overlap: 49,6 %).
LLMs als Textbeurteiler ungeeignet
Nach Ansicht des Forschungsteams deuten die Ergebnisse der Studie darauf hin, dass LLMs nicht für die automatische Annotation auf der Grundlage menschlicher Präferenzen verwendet werden sollten.
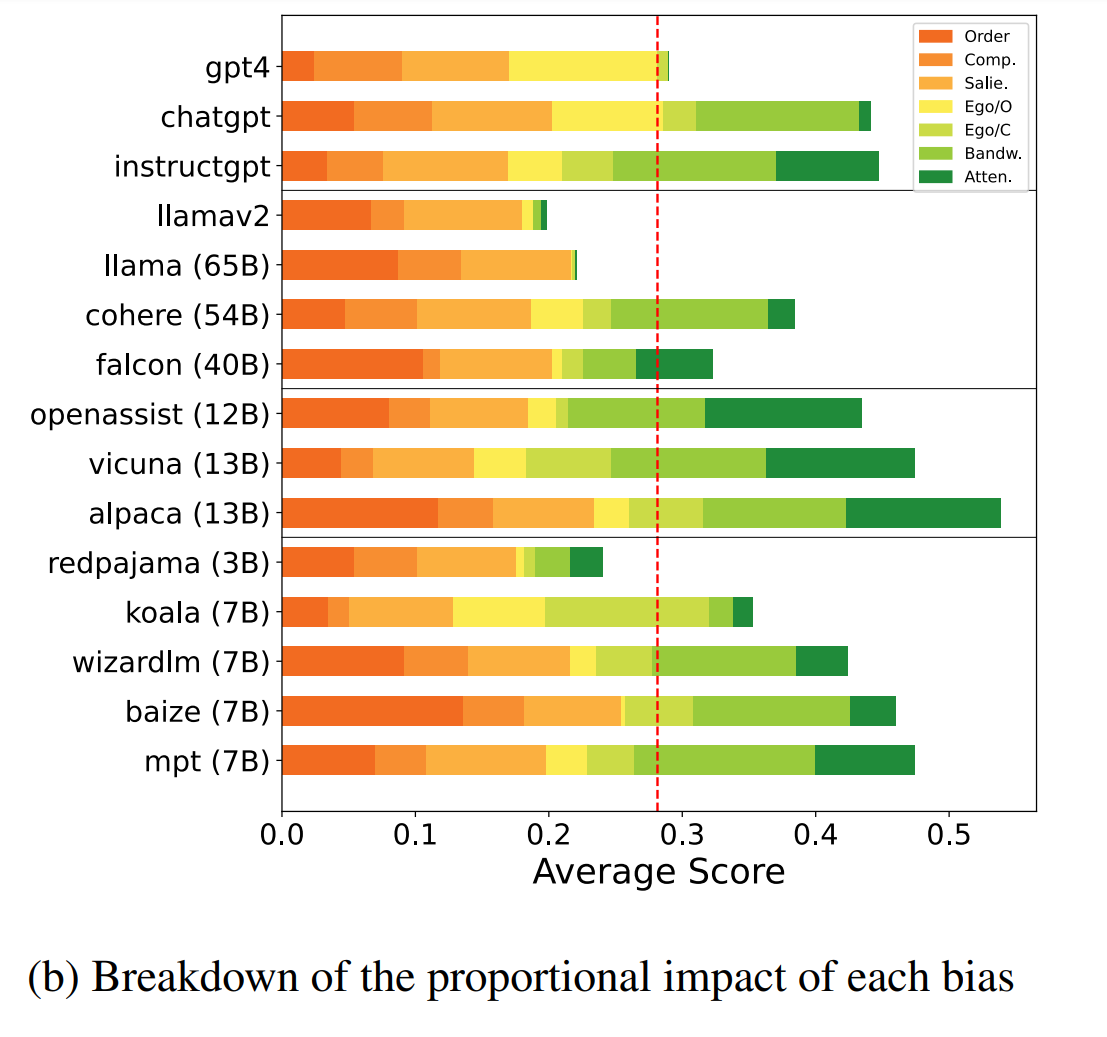
Die meisten der getesteten Modelle zeigten starke Anzeichen von kognitiven Verzerrungen, die ihre Glaubwürdigkeit als Evaluatoren beeinträchtigen könnten.
Selbst Modelle, die auf Instruktionen abgestimmt oder mit menschlichem Feedback trainiert worden waren, zeigten verschiedene kognitive Verzerrungen, wenn sie als automatische Evaluatoren eingesetzt wurden.
Die geringe Korrelation zwischen menschlichen und maschinellen Bewertungen deutet darauf hin, dass maschinelle und menschliche Präferenzen im Allgemeinen wenig übereinstimmen. Das wirft die Frage auf, ob LLMs überhaupt in der Lage sind, faire Bewertungen vorzunehmen.
Mit Bewertungsmöglichkeiten, die verschiedene kognitive Verzerrungen beinhalten, sowie einem geringen Prozentsatz an Übereinstimmung mit menschlichen Präferenzen, deuten unsere Ergebnisse legen unsere Ergebnisse nahe, dass LLMs immer noch nicht als faire und zuverlässige automatische Bewerter geeignet sind.
Aus dem Paper
Die vollständigen Details der Studie sind im arXiv-Paper "Benchmarking Cognitive Biases in Large Language Models as Evaluators" verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.