
Ein neues Projekt hat sich zum Ziel gesetzt, alle Sprachen Europas in einem Modell zu vereinen. Jetzt erhält EuroLingua die dafür notwendige Rechenleistung auf einem Supercomputer in Barcelona.
Das Fraunhofer IAIS (Institut für Intelligente Analyse- und Informationssysteme) und AI Sweden haben Rechenzeit auf dem neuen Supercomputer MareNostrum 5 am Barcelona Supercomputing Center erhalten.
Die Zuteilung durch das European High Performance Computing Joint Undertaking (EuroHPC JU) ist eine der größten, die je für die Entwicklung großer europäischer Sprachmodelle auf der EuroHPC-Infrastruktur vergeben wurde.
Modelle mit bis zu 180 Milliarden Parametern
Ab Ende Mai 2024 werden die Partner im Rahmen des einjährigen Projekts "EuroLingua-GPT" mit der Berechnung der ersten multilingualen Modelle beginnen. Mit einer Zuteilung von 8,8 Millionen GPU-Stunden auf Nvidias H100-Chips können die Partner kleine Modelle im Bereich von 7 bis 34 Milliarden Parametern und große Modelle mit bis zu 180 Milliarden Parametern von Grund auf trainieren. Die ersten Modelle sollen dann in den folgenden Monaten als Open Source veröffentlicht werden.
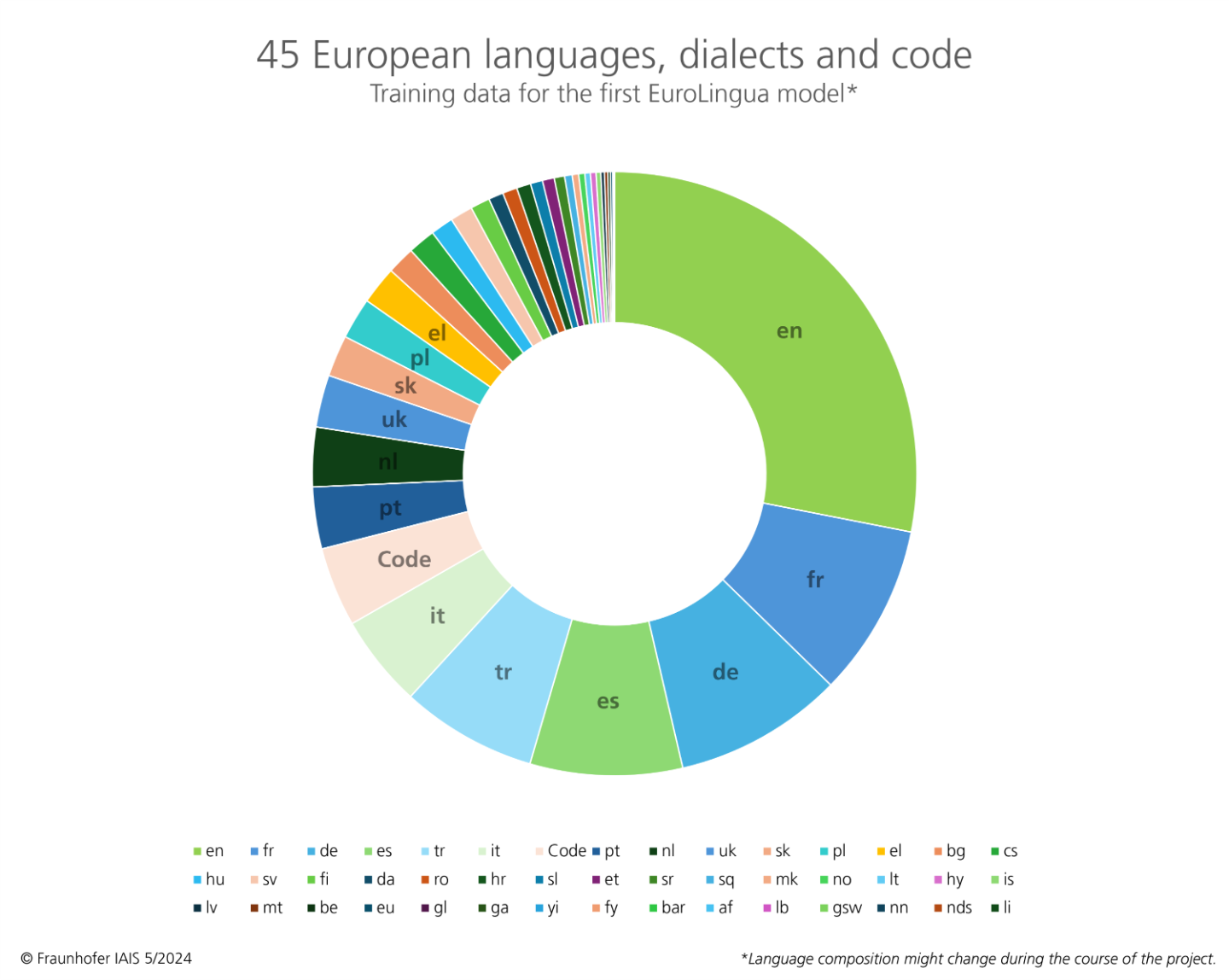
Die EuroLingua-Modelle basieren auf einem Trainingsdatensatz aus 45 europäischen Sprachen, Dialekte und Code, darunter die 24 offiziellen europäischen Sprachen. Damit liegt ein bedeutender Schwerpunkt auf europäischen Sprachen und Werten, da multilinguale KI-Sprachmodelle noch selten sind.
Die gewonnenen Rechenkapazitäten sind ein Meilenstein für Deutschland und Europa. Die damit trainierten Modelle werden den Einsatz von generativer KI in Unternehmen massiv beschleunigen und sowohl der Wirtschaft als auch der Wissenschaft einen Schub geben - GenAI 'made in Europe' wird konkret.
Joachim Köhler, Leiter der Abteilung NetMedia am Fraunhofer IAIS
Das Fraunhofer IAIS und AI Sweden bündeln für dieses Projekt ihre Expertise. Das genannte Fraunhofer-Institut leitet das vom Bundeswirtschaftsministerium geförderte Vorhaben OpenGPT-X, das ebenfalls große europäische multilinguale Open-Source-Modelle entwickelt. Die NLU-Gruppe (Natural Language Understanding) bei AI Sweden hat das GPT-SW3 LLM für die skandinavischen Sprachen entwickelt.
Große Generalisten und kleine Experten
EuroLingua-GPT ist eines von drei großen laufenden EU-Projekten zu Sprachmodellen, an denen das Fraunhofer IAIS und AI Sweden neben TrustLLM und Deploy AI beteiligt sind.
Die auf der EuroHPC-Infrastruktur entwickelten Modelle sollen als generalistische Basismodelle die Forschung und Wissenschaft fördern und durch gemeinsame Transferprojekte später auch für den produktiven Einsatz in Unternehmen oder öffentlichen Verwaltungen spezialisiert werden.
Neben Schweden wird auch im Nachbarland Finnland an Open-Source-Sprachmodellen für Europa gearbeitet, beispielsweise in Form von Poro von Silo AI, wobei man hier noch weit von einem leistungsfähigen, multilingualen Modell entfernt ist.

Das französische Mistral konnte mit Mixtral bereits größere Fortschritte vorzeigen, dieses schneidet in Europa-Benchmarks aber nur auf Französisch, Italienisch, Deutsch und Spanisch besser ab als andere offene Modelle.




