Metas Llama 4 ist effizient, enttäuscht aber bei langen Kontexten

Update –
- Zweites Update von LMArena
- Updates von LMArena.ai und Artificial Analysis ergänzt
Update vom 12. April 2025:
Das "Standard"-Maverick-Modell von Llama 4 rangiert in der LMarena derzeit unter ferner liefen auf Platz 32. Allerdings muss man den Benchmark an dieser Stelle relativieren. Selbst recht veraltete Modelle wie Qwen 2.5 liegen hier vor Modellen wie den eigentlich populären Anthropic-Modellen Sonnet 3.7 und 3.5. Zudem liegen die Punktzahlen eng beieinander.
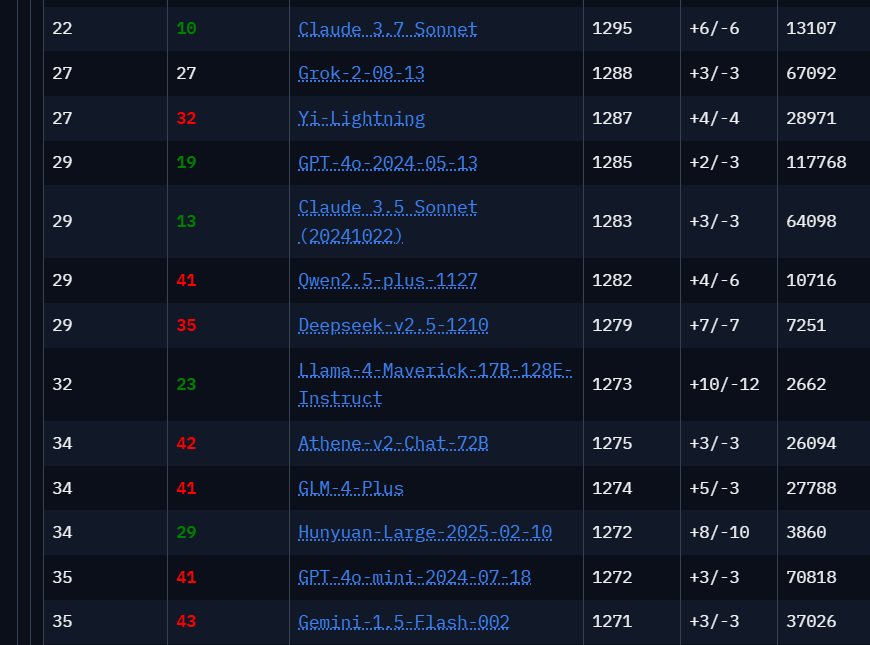
LMarena ist daher eher ein Beispiel dafür, wie beliebig Benchmarks sind, wenn sie nicht im Kontext einer klar definierten Aufgabe erhoben werden, und wie leicht sie manipuliert werden können, siehe das experimentelle Maverick-Modell von Meta weiter unten. Der beste Benchmark ist, wie gut ein Modell seine eigenen Aufgaben lösen kann und mit welchem Preis-Leistungs-Verhältnis.
Update vom 9. April 2025:
Die Plattform LMArena nimmt Stellung zum "experimentellen" KI-Modell von Meta und veröffentlicht über 2.000 direkte Vergleichstests zur Überprüfung. Wie LMArena mitteilt, werden dabei Nutzerprompts, Modellantworten und Nutzerpräferenzen offengelegt. Die Plattform räumt ein, dass Stil und Ton der Antworten ein wichtiger Faktor bei der Bewertung waren (siehe Bericht unten). Hier sieht man, dass Llama 4 häufig ausführlichere Antworten gibt, die stärker formatiert sind und mehr Emoticons haben. Im Klartext: Meta hat für den Benchmark optimiert.
LMArena kündigt an, die Standardversion von Llama-4-Maverick in die Tests einzubeziehen und die Ergebnisse in Kürze zu veröffentlichen. Die Plattform kritisiert, dass die Interpretation der eigenen Richtlinien durch Meta nicht den Erwartungen entspreche. Der Konzern hätte deutlicher kommunizieren müssen, dass es sich bei dem eingereichten Modell um eine speziell auf Nutzerpräferenzen optimierte Version handelt.
Llama 4 verbessert Ranking bei Artificial Analysis
Derweil hat Artificial Analysis seine Bewertungen für die Llama-4-Modelle nach oben korrigiert. Nach einer Überprüfung der Antwortformate stieg der "Intelligence Index" für Scout von 36 auf 43 und für Maverick von 49 auf 50 Punkte. Laut Artificial Analysis werden nun auch Antworten im Format "The best answer is A" als gültig für Multiple-Choice-Tests akzeptiert.
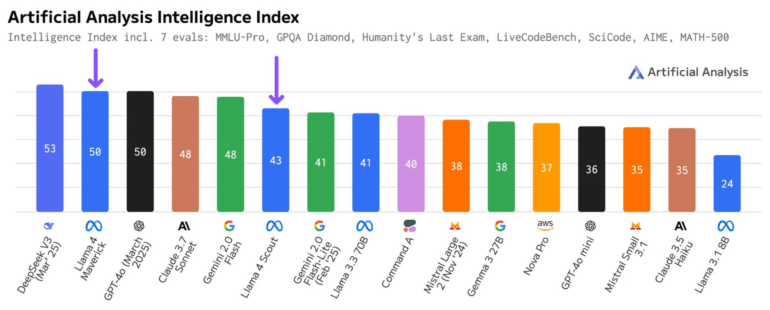
Das Maverick-Modell erreicht diese Leistung laut Artificial Analysis mit nur der Hälfte der aktiven Parameter (17 Milliarden) im Vergleich zum führenden DeepSeek V3 (37 Milliarden). Auch bei den Gesamtparametern liegt Maverick mit 402 Milliarden deutlich unter DeepSeek V3 mit 671 Milliarden Parametern - und unterstützt zusätzlich noch Bildeingaben.
Ursprünglicher Artikel vom 7. April 2025:
Metas Llama 4 ist effizient, enttäuscht aber bei langen Kontexten
Unabhängige Evaluationen zeigen, dass die neuen Llama 4 Modelle von Meta, Maverick und Scout, zwar in Standard-Benchmarks überzeugen, aber in realen Langkontext-Aufgaben hinter den Erwartungen zurückbleiben.
Im aggregierten "Intelligence Index" von Artificial Analysis erreichen die Modelle Werte von 49 (Maverick) und 36 (Scout). Maverick übertrifft damit Claude 3.7 Sonnet, bleibt aber hinter Deepseeks aktuellem V3 0324 zurück. Scout liegt auf dem Niveau von GPT-4o-mini und übertrifft Claude 3.5 Sonnet und Mistral Small 3.1.
Beide Meta-Modelle zeigen konsistente Leistungen über verschiedene Bewertungskategorien hinweg, ohne offensichtliche Schwächen im allgemeinen Reasoning, Coding oder Mathematik.
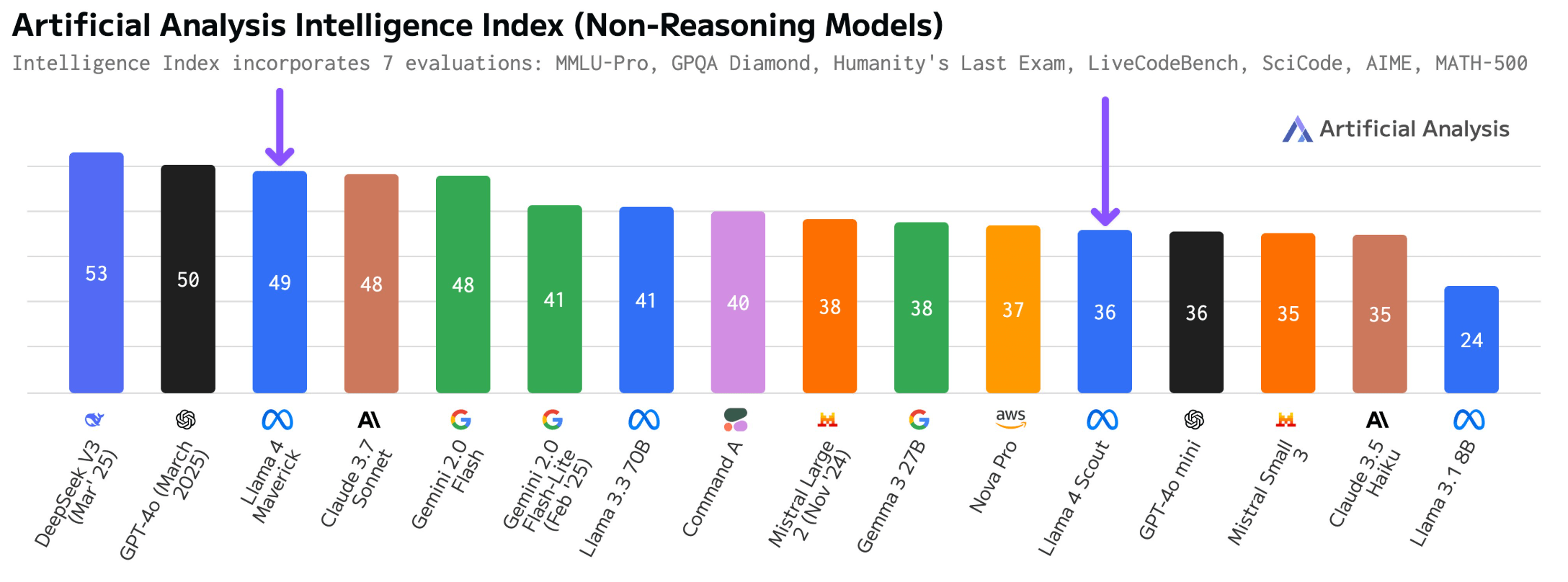
Die Effizienz des Maverick-Modells ist gut. Im Vergleich zum Deepseek-V3-Modell hat Maverick nur etwa die Hälfte der aktiven Parameter (17 Milliarden gegenüber 37 Milliarden) und etwa 60 Prozent der Gesamtparameter (402 Milliarden gegenüber 671 Milliarden). Zudem unterstützt Maverick als multimodales Modell auch Bildeingaben, während Deepseek V3 ein reines Sprachmodell ist.
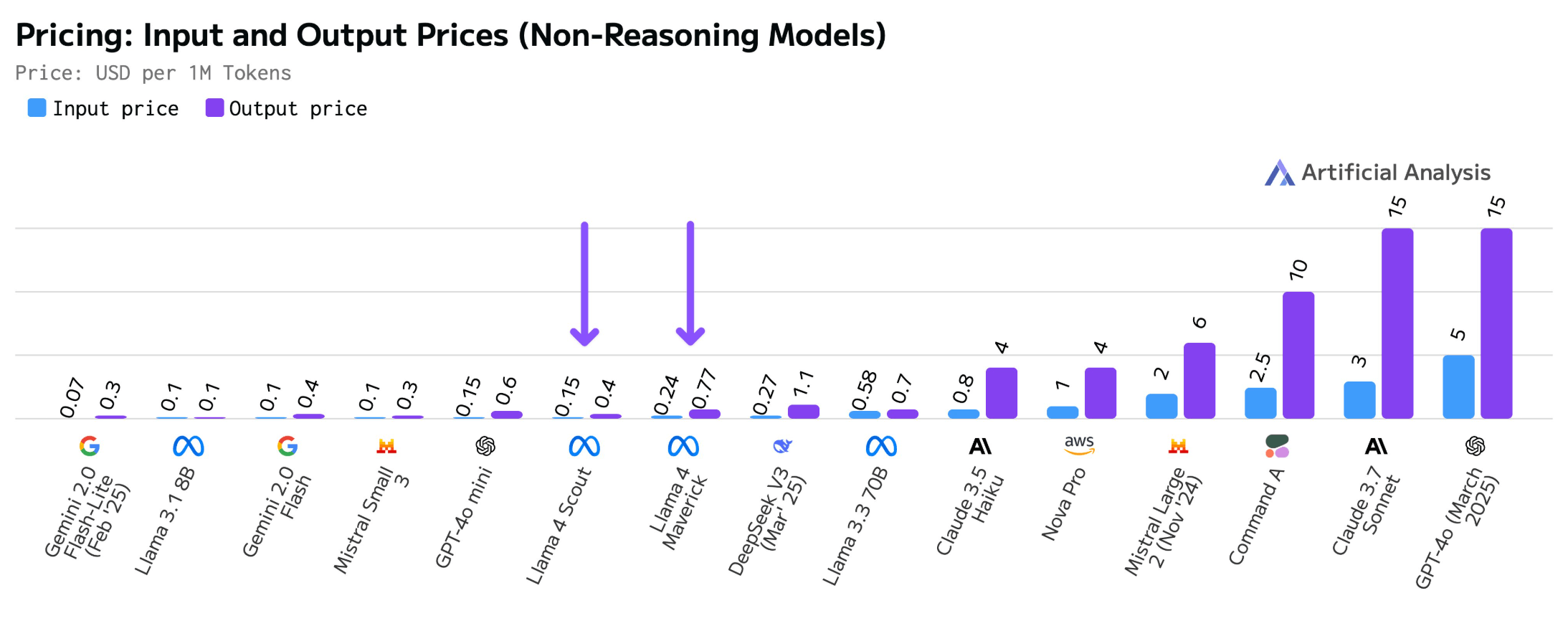
Preislich positioniert Meta seine Modelle attraktiv. Laut Artificial Analysis, das sechs Modell-Hoster auswertet, liegen die Medianpreise bei 0,24/0,77 US-Dollar pro Million Input/Output Tokens für Maverick und 0,15/0,4 US-Dollar für Scout. Damit sind sie billiger als das schon preiswerte Deepseek-V3 und bis zu zehnmal günstiger als GPT-4o von OpenAI.
Kritik an Metas LMArena-Ergebnissen
Die Veröffentlichung von Llama 4 hat auch Kritik hervorgerufen. Einige Tester berichten, dass sich Llama 4 in der LMArena - einem Benchmark, den Meta stark für sein Marketing nutzt - drastisch anders verhält als auf anderen Plattformen. Dies gilt selbst dann, wenn der von Meta empfohlene Systemprompt verwendet wird.
Meta selbst gab bei der Veröffentlichung an, für diesen Benchmark eine "experimentelle Chat-Version" seines Maverick-Modells verwendet zu haben. Der Verdacht liegt also nahe, dass Meta diese Version des Modells so manipuliert hat, dass es von Menschen tendenziell besser bewertet wird - etwa durch besonders ausführliche, gut strukturierte Antworten mit übersichtlicher Formatierung.
In der Tat: Mit aktivierter "Style Control" von LMArena - einer Methode, die zwischen inhaltlicher Substanz und stilistischer Präsentation unterscheidet - fällt Llama 4 in den Rankings von Platz 2 auf Platz 5 zurück. Die Style-Control-Methode versucht, den Einfluss von Faktoren wie Antwortlänge und Formatierung auf die Bewertung zu berücksichtigen, um die inhaltliche Qualität besser isolieren zu können.
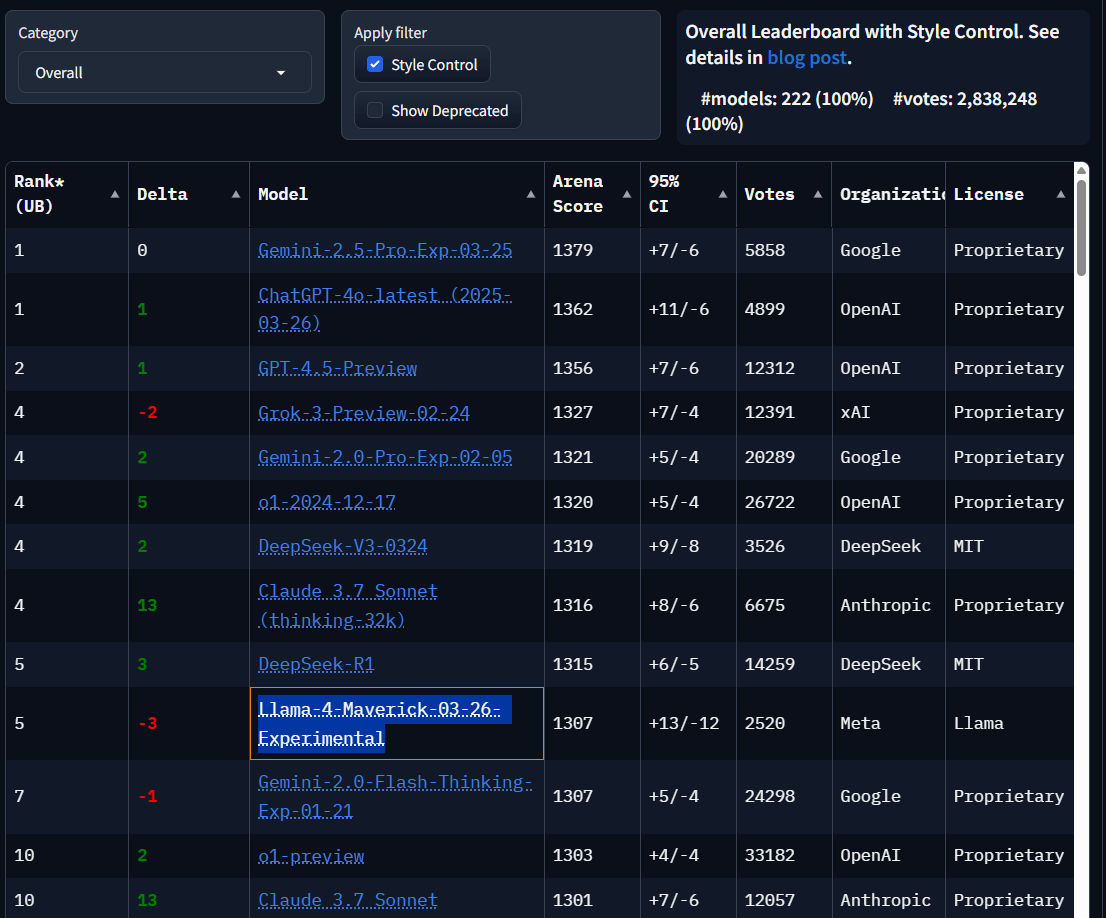
Fairerweise muss man dazu sagen, dass auch die anderen Hersteller von KI-Modellen ihre Benchmarks auf diese Weise frisieren dürften.
Schwache Leistung bei komplexen Langkontext-Aufgaben
Besonders enttäuschend schneiden die Llama-4-Modelle bei Tests der Plattform Fiction.live ab, die speziell das Verstehen von komplexen Langtextinhalten anhand vielschichtiger Geschichten testet.
Fiction.live argumentiert, dass ihre Tests realitätsnäher sind, da sie das tatsächliche Verständnis und nicht nur die Suchfähigkeit testen. Um eine Geschichte wirklich zu verstehen, müssen KI-Modelle Veränderungen im Laufe der Zeit verfolgen, logische Vorhersagen auf der Grundlage etablierter Indizien treffen und zwischen Informationen unterscheiden, die nur den Lesern bekannt sind, und Informationen, die auch den Charakteren bekannt sind.
Bei diesen anspruchsvollen Tests enttäuscht Llama 4. Maverick zeigt keine Verbesserung gegenüber dem bereits unterdurchschnittlichen Modell Llama 3.3 70B, während Scout als "geradezu katastrophal" beschrieben wird.
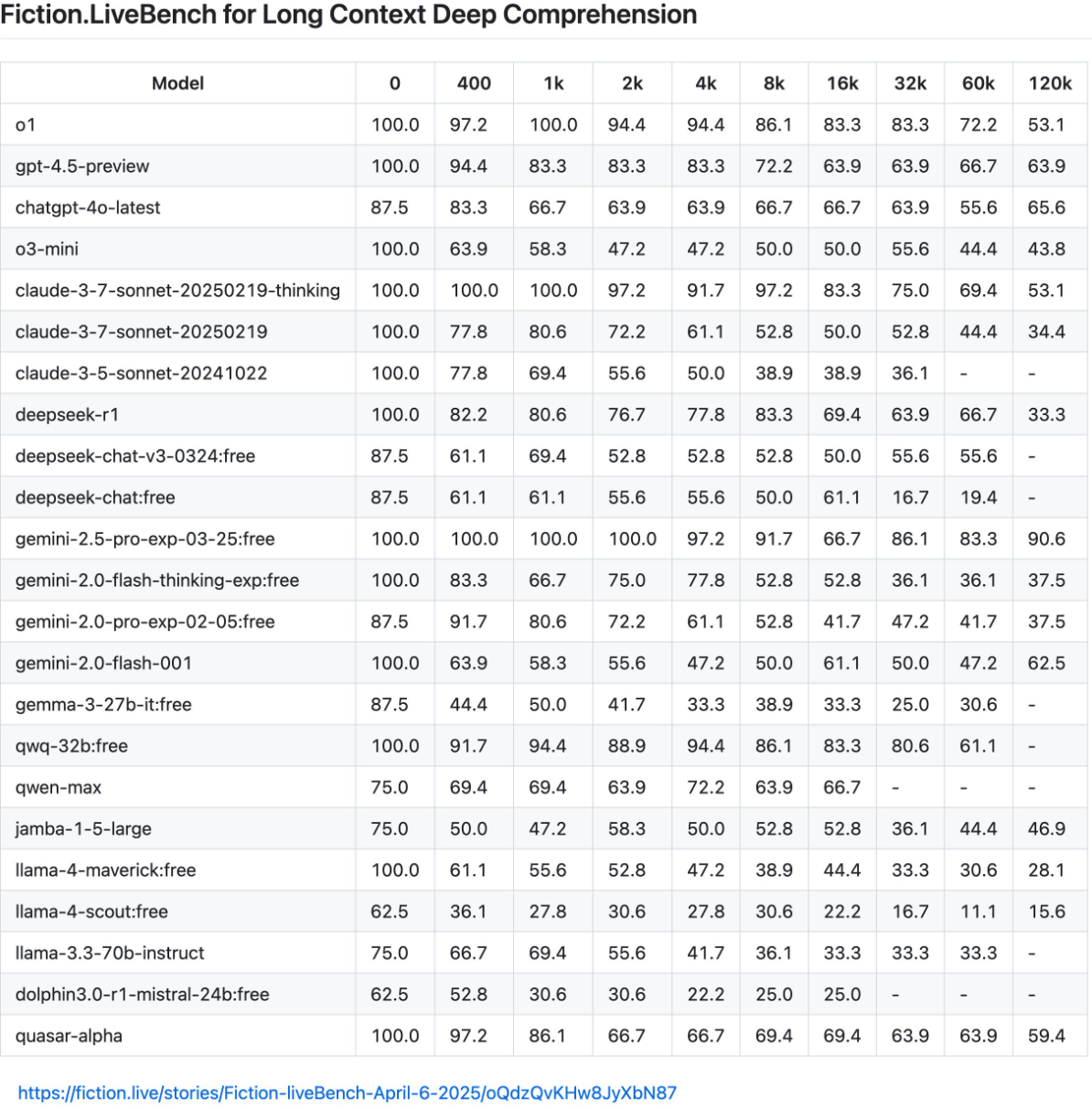
Während Gemini 2.5 Pro selbst bei 120.000 Tokens noch eine Genauigkeit von 90,6 Prozent erreicht, fallen die Llama-Modelle drastisch ab - Maverick erreicht nur noch 28,1 Prozent und Scout sogar nur noch 15,6 Prozent.
Diese Ergebnisse stellen die Aussagen von Meta zur Langkontextfähigkeit ihrer Modelle infrage, nach denen Scout bis zu zehn Millionen Tokens verarbeiten können soll - es versagt aber bereits bei 128.000 Satzbausteinen. Auch Maverick ist nicht in der Lage, Dokumente in der angekündigten Größenordnung von einer Million Token konsistent auszuwerten.
Mehrere Studien haben bereits gezeigt, dass der Nutzen von großen Kontextfenstern für KI-Modelle überschätzt wird, da die Systeme nicht in der Lage sind, alle ihnen zur Verfügung stehenden Informationen gleichmäßig auszuwerten.
In der Praxis ist es daher oft besser, mit eher kleinen Kontexten bis maximal 128K zu arbeiten und die Quellen für diese kleinschrittigen KI-Prozesse zu optimieren. Beispielsweise sollte ein umfangreiches PDF in Kapitel aufgeteilt werden, anstatt es auf einmal in das Modell zu laden, um eine maximale Genauigkeit zu erreichen.
Meta reagiert auf Kritik
Meta hat inzwischen auf die unterschiedlichen Testergebnisse reagiert. Ahmad Al-Dahle, der bei Meta die Entwicklung generativer KI leitet, räumt ein, dass es Berichte über schwankende Qualität bei verschiedenen Diensten gibt. Dies führt er darauf zurück, dass die Modelle kurzfristig nach ihrer Fertigstellung veröffentlicht wurden und die öffentlichen Implementierungen noch Zeit bräuchten, um optimal eingestellt zu werden.
Al-Dahle weist zudem Vorwürfe zurück, Meta habe auf Testdatensätzen trainiert: "Das stimmt einfach nicht und wir würden so etwas nie tun." Meta arbeite weiter an Fehlerbehebungen und der Einbindung von Partnern. Das Unternehmen sei überzeugt, dass die Llama 4 Modelle einen bedeutenden Fortschritt darstellen und wolle mit der Community zusammenarbeiten, um ihr Potenzial zu erschließen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.