Metas neues Übersetzungssystem kann 200 verschiedene Sprachen übersetzen. Der maschinelle Universalübersetzer soll in Zukunft auch Hürden im Metaverse abbauen.
Maschinelle Übersetzungen sind dank Durchbrüchen in der maschinellen Verarbeitung natürlicher Sprachen in den letzten Jahren deutlich besser geworden. Unternehmen wie DeepL machen mit ihren qualitativ hochwertigen Übersetzungen mittlerweile menschlichen Übersetzer:innen Konkurrenz.
Auch Tech-Riesen wie Google oder Meta entwickeln eigene KI-Systeme für die Übersetzung, die vor allem Inhalte auf den eigenen Plattformen wie YouTube, Facebook oder Instagram leichter zugänglich machen sollen.
Doch die für die KI-Übersetzung trainierten Systeme benötigen Daten - und die sind für einen Großteil der auf der Welt gesprochenen Daten rar gesät. In der Forschung wird daher zwischen sogenannten ressourcenstarken und ressourcenschwachen Sprachen unterschieden - solche, für die es bereits sehr viele Übersetzungen im Netz gibt, etwa Englisch, und solche, für die es nahezu keine Übersetzungen gibt.
Metas "No Language Left behind" sucht den Universalübersetzer
Meta-Chef Mark Zuckerberg, der möglichst viele Menschen vernetzen möchte - aktuell noch auf Facebook und Instagram, in Zukunft im Metaverse - sieht daher die Entwicklung eines "Universal Speech Translator" als wichtige Aufgabe des eigenen Unternehmens.
Tatsächlich forscht Meta seit Jahren an maschinellen Übersetzungen. 2018 gelang etwa ein großer Erfolg mit unüberwacht trainierten KI-Systemen und Rückübersetzungen. 2020 zeigte Meta mit M2M-100 ein System, das 100 Sprachen übersetzen konnte. Ein darauf aufbauendes KI-System konnte 2021 dann als erstes multilinguales KI-Modell Spitzenwerte im Übersetzungsbenchmark WMT2021 knacken.
Solche multilingual trainierten KI-Modelle gelten als die Zukunft von maschineller Übersetzung: Anders als ältere Systeme werden diese mit dutzenden oder hunderten Sprachen gleichzeitig trainiert, um dann die durch dieses Training mit ressourcenstarken Sprachen erreichte Leistung auf die Übersetzungsleistung von ressourcenschwachen Sprachen zu übertragen. Auch Google forscht an solchen multilingualen KI-Systemen.
Angetrieben von den Erfolgen der multilingualen Modelle, startete Meta im Feburar 2022 das "No Language Left behind"-Projekt, das Echtzeit-Universalübersetzungen auch für seltene Sprachen ermöglichen soll.
Zuckerberg bezeichnete diese Multisprachfähigkeit als "Supermacht, von der Menschen schon immer geträumt haben." Ein solcher Übersetzer könne Sprachbarrieren beseitigen und Milliarden von Menschen Zugriff auf Informationen in ihrer bevorzugten Sprache gewähren, so Metas KI-Forschende.

Meta knackt die 200-Sprachen-Grenze
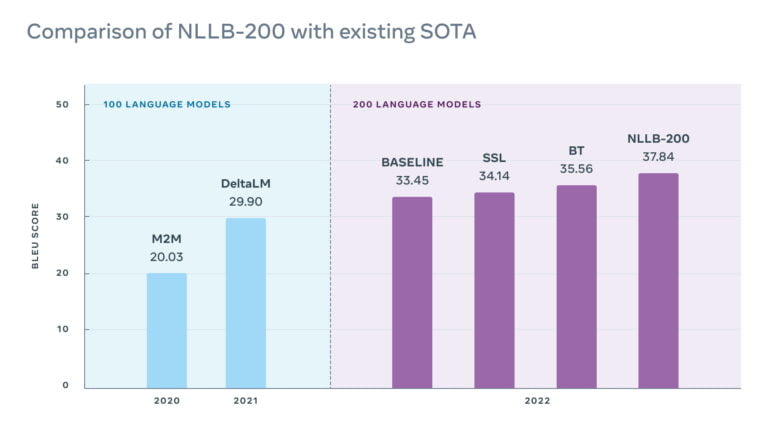
Nun stellt Meta NLLB-200 vor, ein multilinguales KI-Modell, das 200 Sprachen in hoher Qualität übersetzen können soll. Um die Übersetzungsqualität sicherzustellen, hat das Team zudem einen 200-sprachigen Evaluierungsdatensatz (FLORES-200) erstellt und damit NLLB-200 getestet.
Im Vergleich mit anderen multilingualen Modellen übertreffe NLLB-200 den aktuellen Stand der Technik um durchschnittlich 44 Prozent. In einigen afrikanischen und indischen Sprachen übertreffe Metas System ältere Systeme sogar um 70 Prozent.
Gängige Übersetzer unterstützten etwa weniger als 25 afrikanische Sprachen, viele davon in mangelhafter Qualität. Metas neues KI-Modell unterstützt dagegen 55 afrikanische Sprachen und soll qualitativ hochwertige Ergebnisses liefern.
Möglich ist das durch Fortschritte bei der Sammlung der Trainingsressourcen, einem größeren KI-Modell und der besseren Evaluierung und Optimierung des Modells mit FLORES-200. Dank einer neuen Version des LASER-Toolkits für den Zero-Shot-Transfer in der Computerlinguistik, die auf einem Transformer-Modell basiert, konnte Meta die Sprachabdeckung von LASER3 skalieren, große Mengen von Satzpaaren auch für ressourcenarme Sprachen generieren und mit dem LID-200-Modell sowie einem Datensatz für toxische Sprache besser filtern.
Sowohl für das Sammeln der Trainingsdaten als auch die Bewertung von Übersetzungsqualität kooperiert Meta zudem mit menschlichen Expert:innen, gerade in den ressourcenschwachen Sprachen.
Das NLLB-200-Modell selbst setzt auf eine Mixture-of-Experts-Architektur, in der bestimmte Bereiche des neuronalen Netzes bestimmte Sprachen verarbeiten. Das habe eine Überanpassung des Systems bei so vielen Sprachdaten verhindert, so Meta. Die Künstliche Intelligenz sei zudem zuerst aus ressourcenstarken und anschließend ressourcenarmen Sprachpaaren trainiert worden.
NLLB-200 ist 54 Milliarden Parameter groß und wurde auf Metas neuem KI-Supercomputer Research SuperCluster (RSC) trainiert.
Metas NLLB-200 ist Open-Source
Die für NLLB-200 entwickelten Techniken und Erkenntnisse sollen nun für die Optimierung und Erweiterung von Übersetzungen auf Facebook und Instagram verwendet werden. Dort gäbe es bereits mehr als 25 Milliarden Übersetzungen täglich. Durch die Verfügbarkeit von fehlerfreien Übersetzungen in mehr Sprachen könnten auch gefährliche Inhalte und Fehlinformationen leichter erkannt, die Wahlintegrität geschützt und die Verbreitung von sexuellem Missbrauch im Internet und Menschenhandel eingedämmt werden, schreibt das Unternehmen.
Zusätzlich soll die KI-Übersetzung auch für Wikipedia-Redakteur:innen zur Verfügung stehen. Meta stellt zudem die fertig trainierten NLLB-200-Modelle, den Evaluierungsdatensatz FLORES-200, den Modell-Trainingscode und den Code zum Nachbilden des Trainingsdatensatzes unter einer Open-Source-Lizenz zur Verfügung.