
Fairy von Meta ist ein schnelles Video-zu-Video-Synthesemodell, das zeigt, wie KI auch in der Videobearbeitung mehr kreativen Spielraum schaffen kann.
Das GenAI-Team von Meta hat mit Fairy ein neues Modell für die Video-zu-Video-Synthese vorgestellt, das schneller als bestehende Modelle ist und eine höhere zeitliche Kohärenz aufweist.
Das Forschungsteam stellt Fairy in verschiedenen Anwendungen wie dem Austausch von Zeichen/Objekten, der Stilisierung und der Generierung langer Videos vor. Für die Bearbeitung des Ausgangsvideos genügen einfache Textbefehle, wie man sie von Bildsystemen kennt, zum Beispiel "im Stil von van Gogh". Der Textbefehl "Verwandle in einen Yeti" verwandelt einen Astronauten im Video in einen Yeti.
Video: Meta, Wu et al.
Die visuelle Kohärenz stellt eine besondere Herausforderung dar, da es unzählige Möglichkeiten gibt, ein bestimmtes Bild auf der Basis desselben Prompts zu verändern. Fairy verwendet dazu eine bildübergreifende Aufmerksamkeit, die implizit die entsprechenden Regionen verfolgt und globale Merkmale überträgt, um die Diskrepanz zwischen den Einzelbildern zu verringern.
Das Modell kann Videos mit 512x384 Pixeln und 120 Einzelbildern (4 Sekunden bei 30 Bildern pro Sekunde) in nur 14 Sekunden erzeugen und ist damit mindestens 44 Mal schneller als frühere Modelle. Wie die Emu-Videomodelle von Meta basiert auch Fairy auf einem Diffusionsmodell für die Bildverarbeitung, das für die Videobearbeitung erweitert wurde.
Fairy verarbeitet alle Frames des Quellvideos ohne zeitliches Downsampling oder Frame-Interpolation und ändert die Größe der Längsseite des Ausgabevideos auf 512 unter Beibehaltung des Seitenverhältnisses. In Tests mit sechs A100-GPUs konnte Fairy ein 27 Sekunden langes Video in 71,89 Sekunden rendern bei hoher visueller Konsistenz.
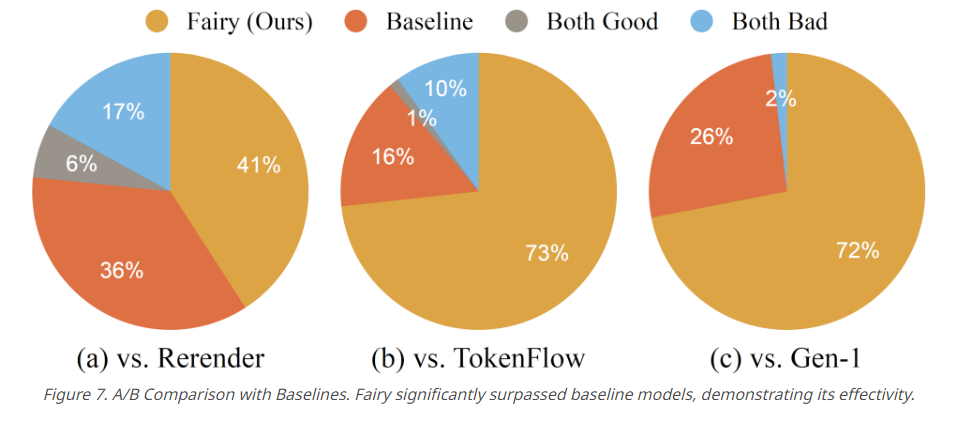
Die Leistungsfähigkeit von Fairy wurde in einer umfangreichen Benutzerstudie mit 1000 generierten Samples getestet. Sowohl die menschliche Beurteilung als auch die quantitativen Metriken bestätigten, dass Fairy eine bessere Qualität als die drei Modelle Rerender, TokenFlow und Gen-1 aufweist.
Fairy hat noch Probleme mit dynamischen Effekten
Das Modell hat derzeit noch Probleme mit Umwelteffekten wie Regen, Feuer oder Blitz, die sich entweder nicht konsistent in das Gesamtbild einfügen oder einfach visuelle Fehler erzeugen.


Nach Ansicht der Forscher ist das wiederum auf den Fokus auf zeitliche Konsistenz zurückzuführen, der dazu führt, dass dynamische visuelle Effekte wie Blitze oder Flammen eher statisch oder stagnierend als dynamisch und fließend dargestellt werden.
Dennoch betrachtet das Forschungsteam seine eigene Arbeit als einen bedeutenden Fortschritt im Bereich der KI-Videobearbeitung mit einem transformativen Ansatz für zeitliche Konsistenz und hochwertige Videosynthese.




