Microsoft stellt neue Phi 3.5 Open-Source-KI-Modelle vor

Microsoft hat drei neue Open-Source-KI-Modelle der Phi-3.5-Serie vorgestellt. Die Modelle zeichnen sich durch hohe Reasoning-Fähigkeiten und Mehrsprachigkeit aus, haben aber auch Schwächen bei Faktenwissen und Sicherheit.
Microsoft hat drei neue Open-Source-KI-Modelle der Phi-3.5-Serie veröffentlicht: mini-instruct, MoE-instruct und vision-instruct. Die Modelle sind laut Microsoft für den kommerziellen und wissenschaftlichen Einsatz in mehreren Sprachen konzipiert.
Die Grundidee der Phi-Reihe ist es, hocheffiziente KI-Modelle auf der Basis von qualitativ hochwertigen Daten zu trainieren. Für das Vision-Modell hat das Unternehmen nach eigenen Angaben "neu erstellte synthetische, 'lehrbuchähnliche' Daten für den Unterricht in Mathematik, Codierung, gesundem Menschenverstand und allgemeinem Wissen über die Welt" verwendet, zusätzlich zu anderen hochwertigen und gefilterten Daten.
Die neuen Phi-Modelle eignen sich nach Angaben von Microsoft besonders für Anwendungen mit begrenztem Arbeitsspeicher und Rechenleistung, zeitkritische Szenarien sowie starkes logisches Schlussfolgern - im Rahmen der Möglichkeiten eines LLMs.
Das Phi-3.5-mini-instruct-Modell ist die kleinste Variante mit 3,8 Milliarden Parametern. Es wurde für Szenarien mit begrenzter Rechenleistung und geringem Arbeitsspeicher optimiert. Trotz seiner geringen Größe erreicht es in Benchmarks insbesondere für Mehrsprachigkeit gute Ergebnisse.
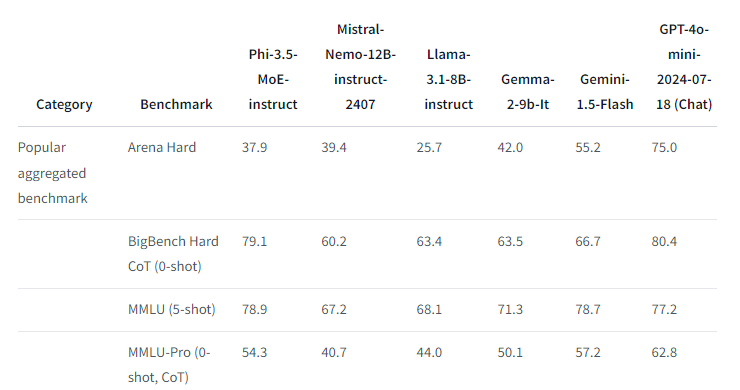
Das Phi-3.5-MoE-instruct-Modell hat laut Microsoft 16 Experten mit jeweils 3,8 Milliarden Parametern, was insgesamt 60,8 Milliarden Parameter ergibt. Allerdings sind davon nur 6,6 Milliarden Parameter aktiv, wenn zwei Experten verwendet werden.
In Benchmarks erreicht es mit dieser geringen Zahl aktiver Parameter ein ähnliches Niveau beim Sprachverständnis und in Mathematik wie viel größere Modelle. In Reasoning-Aufgaben übertrifft es sogar einige größere Modelle und liegt nur hinter GPT-4o-mini. Auch bei multilingualen Aufgaben ist es trotz der geringen aktiven Parameterzahl wettbewerbsfähig.
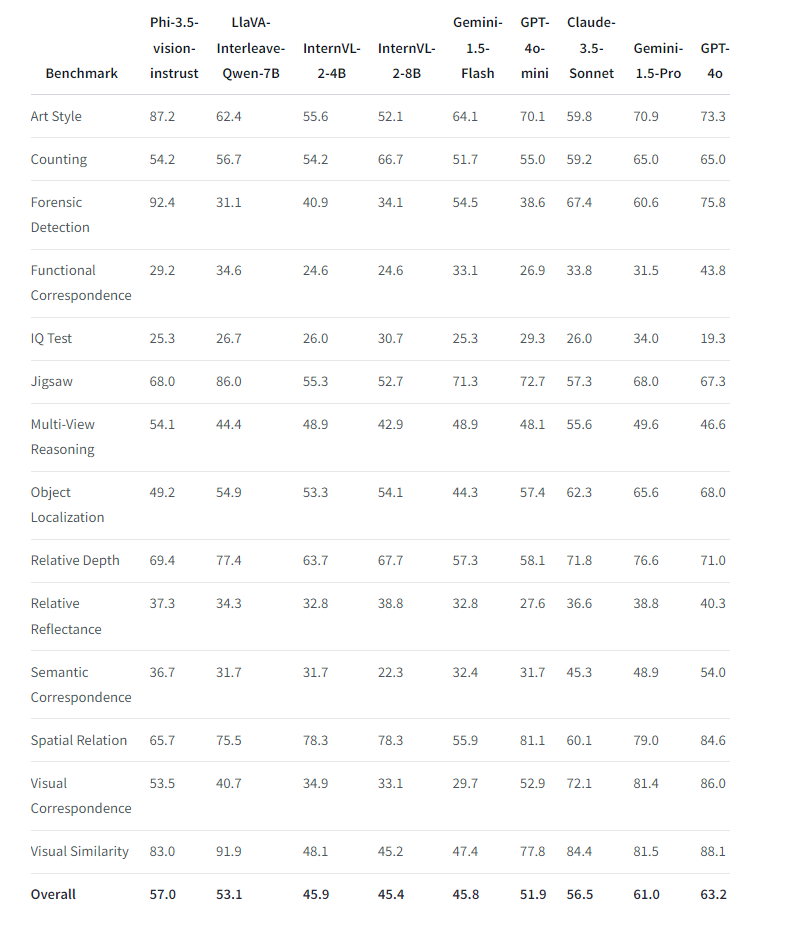
Das Phi-3.5-vision-instruct-Modell ist ein multimodales Modell mit 4,2 Milliarden Parametern, das sowohl Text als auch Bilder verarbeiten kann. Es enthält einen Bildkodierer, einen Konnektor, einen Projektor und das Phi-3-Mini-Sprachmodell. Damit eignet es sich für Anwendungen mit Bild- und Texteingabe wie allgemeines Bildverständnis, optische Zeichenerkennung, Verständnis von Diagrammen und Tabellen, Vergleich mehrerer Bilder und Zusammenfügen mehrerer Bilder oder Videoclips. In Benchmarks übertrifft es Konkurrenzmodelle gleicher Größe bei der Verarbeitung mehrerer Bilder und der Videozusammenfassung und ist mit wesentlich größeren Modellen wie GPT-4o konkurrenzfähig.
Phi-Kontextfenster wächst
Dank der Unterstützung von bis zu 128.000 Token Kontextlänge eignet sich Phi-3.5 auch für Aufgaben wie lange Dokument- und Besprechungszusammenfassungen, Fragen zu langen Dokumenten und mehrsprachiges Kontextretrieval. Hier schneidet es etwa besser ab als Googles Modelle der Gemma-2-Familie, die nur 8.000 Token unterstützen. Allerdings gilt auch für Phi-Modelle bei der Verarbeitung großer Dokumente weiter das generelle LLM-Problem der vergessenen Mitte. Das Problem gilt auch für die Bildverarbeitung.
Die geringe Größe des Modells schränkt es zudem für bestimmte Aufgaben ein. Laut Microsoft hat es nicht genug Kapazität, um zu viel Faktenwissen zu speichern, was zu mehr Ungenauigkeiten führen kann. Microsoft glaubt jedoch, dass diese Schwäche durch die Kombination von Phi-3.5 mit einer Suchmaschine wie RAG behoben werden kann.
Wie andere Sprachmodelle können auch die Phi-Modelle potenziell unfaire, unzuverlässige oder anstößige Ausgaben produzieren. Trotz eines Sicherheitstrainings gibt es immer noch Einschränkungen aufgrund der unterschiedlichen Repräsentation verschiedener Gruppen und Kontexte in den Trainingsdaten.
In den Red-Teaming-Tests lehnten die Modelle zwar unerwünschte Ausgaben auf Englisch ab, auch wenn der Prompt in einer anderen Sprache erfolgte. Sie waren jedoch anfälliger für längere Ausbrechtechniken mit mehreren Durchgängen, sowohl in Englisch als auch in anderen Sprachen.
Die Phi-3.5-Modelle sind unter der MIT-Lizenz auf der Hugging Face Plattform frei und für alle Anwendungsszenarien verfügbar. Alternativ können sie über Microsofts Azure AI Studio abgerufen werden. Allerdings benötigen sie spezielle GPU-Hardware wie NVIDIA A100, A6000 oder H100, um Flash-Attention zu unterstützen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.