Microsoft will Wissensdatenbanken effizienter in Sprachmodelle integrieren
Microsoft Research hat mit KBLaM eine neue Methode entwickelt, die es ermöglicht, externe Wissensdatenbanken effizienter in Sprachmodelle zu integrieren. Der Ansatz skaliert linear statt quadratisch und kommt ohne separate Retrieval-Module aus.
Die Methode mit dem unhandlichen Namen Knowledge Base-Augmented Language Models (KBLaM) könnte tatsächlich einen Durchbruch beim Einbinden von externem Wissen in Sprachmodelle darstellen. Laut den Forschenden integriert KBLaM strukturierte Wissensdatenbanken nach dem "Plug-and-Play"-Prinzip in vortrainierte Sprachmodelle, ohne dass diese modifiziert werden müssen.
Weniger Speicherbedarf für große Wissensbasen
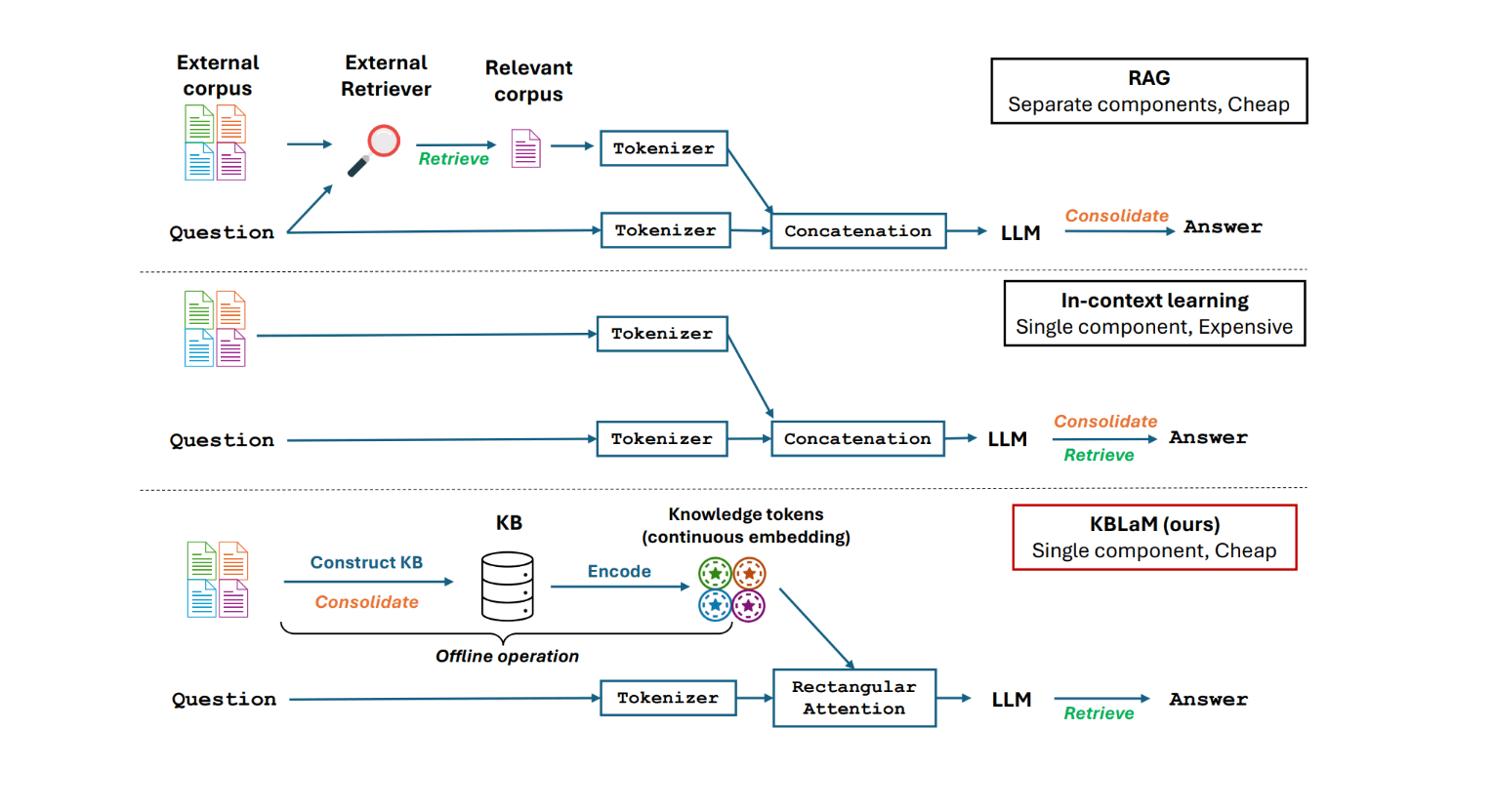
Der neue Ansatz unterscheidet sich fundamental von bisherigen Methoden wie Retrieval-Augmented Generation (RAG) oder In-Context Learning. Statt separate Retrieval-Module zu verwenden oder das gesamte Modell neu zu trainieren, wandelt KBLaM Wissen in Vektorpaare um und bettet diese mittels einer speziellen rechteckigen Attention-Struktur in die Modellarchitektur ein. Im letzten Schritt erfolgt das dynamische Abrufen relevanter Wissenselemente während der Inferenz.
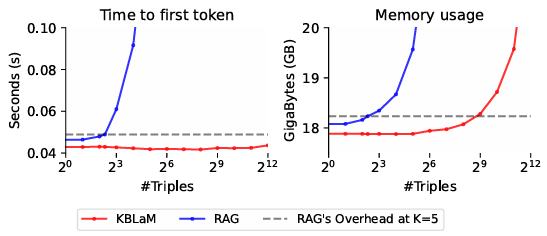
Die quadratische Skalierung bei RAG entsteht laut Microsoft Research durch den Self-Attention-Mechanismus: Jeder Token muss mit jedem anderen Token interagieren. Wenn also beispielsweise 1.000 Tokens aus der Wissensbasis in den Kontext eingefügt werden, muss das Modell – in der Theorie – eine Million (1.000 x 1.000) Token-Paare verarbeiten. Bei 10.000 Tokens steigt diese Zahl bereits auf 100 Millionen Interaktionen.
KBLaM umgeht dieses Problem durch seine rechteckige Attention-Struktur: Die Tokens der Nutzereingabe können zwar auf alle Wissens-Tokens zugreifen, die Wissens-Tokens selbst interagieren aber weder untereinander noch mit der Nutzereingabe. Dadurch wächst der Rechenaufwand nur linear mit der Größe der Wissensbasis.
Damit wächst auch KBLaMs Speicherbedarf nur linear mit der Größe der Wissensbasis. Nach Angaben der Forschenden können so über 10.000 Wissens-Tripel (etwa 200.000 Tokens) auf einer einzelnen GPU verarbeitet werden.
Open Source und breite Modellunterstützung
Microsoft hat den Code und die Datensätze von KBLaM als Open Source auf GitHub veröffentlicht. Das System unterstützt derzeit verschiedene Modelle wie Metas Llama 3 und Microsofts Phi-3. Eine Integration in die Hugging Face Transformers Bibliothek ist laut den Forschenden für die Zukunft geplant.
Die Methode zeigt sich Microsofts Untersuchungen zufolge besonders effektiv bei der Vermeidung von Halluzinationen: Ab einer Wissensbasis von etwa 200 Einträgen verweigert das System präziser als herkömmliche Modelle Antworten auf Fragen, zu denen es keine Informationen hat. Außerdem sei es transparenter als In-Context Learning, da Wissen genau mit bestimmten Tokens verknüpft werden könne.
Noch nicht serienreif
Die Entwickler:innen betonen jedoch, dass noch weitere Forschung nötig ist, bevor KBLaM im großen Maßstab eingesetzt werden kann. Bisher wurde das System hauptsächlich mit faktischen Frage-Antwort-Paaren trainiert. Die Erweiterung auf komplexere Reasoning-Aufgaben steht noch aus.
Unabhängig von der sich nur langsam verbessernden Leistung vortrainierter Modelle bleibt eine der größten Herausforderungen für möglichst halluzinationsfreie Antworten die effiziente Versorgung der Sprachmodelle mit aktueller und spezifischer Information.
Zwar wird das Kontextfenster der Sprachmodelle immer größer, so dass immer mehr Daten auf einmal in das KI-System eingespeist werden können. Die Verarbeitung dieser großen Datenmengen im Kontextfenster ist jedoch nicht zuverlässig.
Deswegen hat sich die RAG-Architektur als effiziente Möglichkeit etabliert, dem Modell mehr und spezifischere Informationen je nach Anfrage zur Verfügung zu stellen und gleichzeitig die Zuverlässigkeit zu erhöhen. Auch Microsoft hatte in der Vergangenheit hierzu geforscht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.