Moralischer Turing-Test: GPT-4o liefert laut Studie ethischen Rat auf Expertenniveau

Eine aktuelle Studie zeigt, dass GPT-4o in der Lage ist, moralische Erklärungen und Ratschläge zu geben, die von Menschen als qualitativ besser eingeschätzt werden als die eines anerkannten Ethikexperten.
Forscher der University of North Carolina at Chapel Hill und des Allen Institute for Artificial Intelligence haben untersucht, ob große Sprachmodelle (LLMs) als "moralische Experten" angesehen werden können. In zwei Studien verglichen sie die moralischen Erklärungen und Ratschläge des KI-Modells GPT mit denen von Menschen.
In der ersten Studie wurden 501 US-Amerikaner gebeten, moralische Erklärungen von GPT-3.5-turbo und anderen Teilnehmern zu bewerten. Die Ergebnisse zeigten, dass die Erklärungen von GPT als moralisch korrekter, vertrauenswürdiger und durchdachter als die der menschlichen Teilnehmer eingestuft wurden.
Überdies stimmten die Beurteiler der Maschine häufiger zu als den Einschätzungen anderer Menschen. Die Unterschiede sind zwar gering, aber die eigentliche Schlussfolgerung ist, dass die Maschine das menschliche Niveau erreichen oder sogar übertreffen kann.
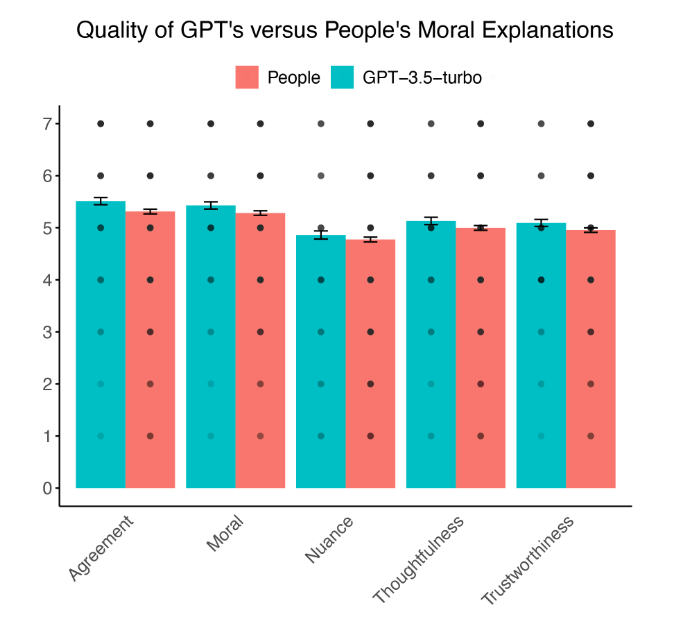
GPT-4o übertrifft menschlichen Experten
In einer zweiten Studie verglichen die Forscher die Ratschläge von GPT-4o, dem neuesten GPT-Modell, mit den Ratschlägen des renommierten Ethikexperten Kwame Anthony Appiah von der Kolumne "The Ethicist" der New York Times. 900 Teilnehmer bewerteten die Qualität der Ratschläge zu 50 ethischen Dilemmata.
GPT-4o schnitt in fast allen Kriterien besser ab als der menschliche Experte. Die KI-generierten Ratschläge wurden als moralisch korrekter, vertrauenswürdiger, durchdachter und richtiger bewertet. Nur bei der wahrgenommenen Nuanciertheit gab es keinen signifikanten Unterschied.
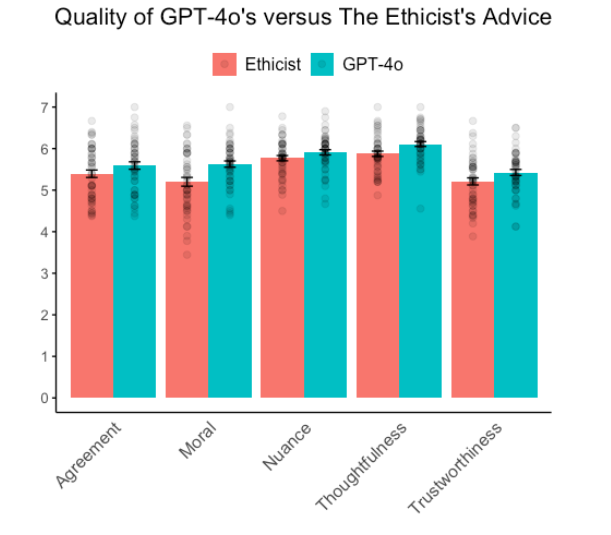
Aus Sicht der Forschenden zeigen die Ergebnisse, dass KI den "Comparative Moral Turing Test" (cMTT) bestehen kann. Interessanterweise konnten die Teilnehmenden in beiden Studien KI-generierte Inhalte häufig als solche identifizieren, was darauf hindeutet, dass die Maschine noch immer durch den klassischen Turing-Test fällt. Allerdings gibt es hierzu auch andere Resultate.
Eine Textanalyse ergab, dass GPT-4o in seinen Ratschlägen mehr moralische und positive Sprache verwendete als der menschliche Experte. Dies könne teilweise die höhere Bewertung der KI-Ratschläge erklären, war aber nicht der einzige Faktor.
Die Autoren weisen darauf hin, dass die Studie auf US-amerikanische Teilnehmer beschränkt war und weitere Forschung nötig ist, um kulturelle Unterschiede in der Wahrnehmung von KI-generierter moralischer Argumentation zu untersuchen. Zudem wussten die Teilnehmer nicht, dass einige Ratschläge von einer KI stammten, was die Bewertungen beeinflusst haben könnte.
Insgesamt zeigt die Studie, dass moderne KI-Systeme in der Lage sind, moralische Erklärungen und Ratschläge auf einem Niveau zu geben, das mit menschlichen Experten vergleichbar oder sogar besser ist. Das habe insbesondere Bedeutung für die Integration von KI in Bereiche, die komplexe ethische Entscheidungen erfordern, wie Therapie, Rechtsberatung und persönliche Betreuung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.