Neue KI-Sicherheitstechnik von Anthropic ist vollständig geknackt

Update –
- Jailbreak Update 2
Update vom 15. Februar 2025:
Nach fünf Tagen, über 300.000 Nachrichten und schätzungsweise 3.700 kollektiven Stunden wurde das KI-System von Anthropic in der Jailbreaking-Challenge geknackt, wie Anthropic-Forscher Jan Leike auf X mitteilte. Vier Nutzer schafften es durch alle Level, einer fand einen universellen Jailbreak. Insgesamt zahlt Anthropic 55.000 Dollar an die Gewinner aus.
Leike betont, dass mit zunehmender Leistungsfähigkeit der Modelle die Robustheit gegen Jailbreaks zu einer wichtigen Sicherheitsanforderung wird, um Missbrauch im Zusammenhang mit chemischen, biologischen, radiologischen und nuklearen Risiken zu verhindern. Die Demo zeigte, dass Klassifikatoren dazu beitragen können, diese Risiken zu mindern, aber mit anderen Methoden kombiniert werden müssen.
Update vom 10. Februar 2025:
Sechs Tage nach dem Start der Challenge wurden alle Sicherheitsmechanismen geknackt.
Wie der Anthropic-Forscher Jan Leike, ehemaliges Mitglied des Alignment-Teams von OpenAI, auf X mitteilte, hat eine Person alle acht Level der Challenge geknackt. Insgesamt seien 3.700 Stunden und rund 300.000 Nachrichten von allen Beteiligten zusammengekommen. Ein universeller Jailbreak, der alle Level der Challenge löst, sei aber noch nicht gefunden worden, so Leike.
Mit zunehmender Leistungsfähigkeit wird ein stärkerer Schutz der Modelle immer wichtiger - gleichzeitig werden universelle Jailbreaks potenziell wertvoller. Es ist daher denkbar, dass sich in Zukunft ein ähnliches Sicherheitsökosystem um Sprachmodelle entwickeln wird, wie es für Betriebssysteme existiert.
After ~300,000 messages and an estimated ~3,700 collective hours, someone broke through all 8 levels.
However, a universal jailbreak has yet to be found... https://t.co/xpj2hfGC6W
— Jan Leike (@janleike) February 9, 2025
Originalartikel vom 04. Februar 2025
Das KI-Unternehmen Anthropic hat eine Methode entwickelt, die Sprachmodelle vor Manipulationsversuchen schützen soll.
Anthropic hat eine neue Sicherheitstechnik namens "Constitutional Classifiers" vorgestellt, die verhindern soll, dass KI-Modelle durch manipulierte Eingaben (Jailbreaks) zu schädlichen Antworten gezwungen werden können. Laut einem aktuellen Paper des Unternehmens richtet sich die Entwicklung vor allem gegen Universal Jailbreaks - also Eingaben, die systematisch alle Sicherheitsvorkehrungen umgehen können.
In einem ersten Test ließ Anthropic 183 Personen über zwei Monate hinweg versuchen, einen Prototyp des Systems zu überlisten. Die Teilnehmer sollten das KI-Modell Claude 3.5 dazu bringen, zehn verbotene Anfragen zu beantworten. Trotz eines Preisgeldes von 15.000 Dollar und geschätzten 3.000 Stunden Testzeit gelang es niemandem, alle Sicherheitsvorkehrungen auszuhebeln.
Prototyp zeigte hohe Fehlerquote bei harmlosen Anfragen
Der Prototyp hatte allerdings zwei gravierende Schwächen: Er lehnte zu viele harmlose Anfragen ab und verbrauchte zu viel Rechenleistung. Eine verbesserte Version konnte diese Probleme jedoch reduzieren, wie automatisierte Tests mit 10.000 Jailbreak-Versuchen zeigen.
Während das ungeschützte Claude-Modell 86 Prozent der Manipulationsversuche zuließ, blockierte die geschützte Version über 95 Prozent. Die Fehlerquote bei harmlosen Anfragen stieg dabei nur minimal um 0,38 Prozent. Der zusätzliche Rechenaufwand beträgt allerdings immer noch 23,7 Prozent.
Synthetische Trainingsdaten als Basis
Nach Angaben von Anthropic basiert das Sicherheitssystem auf vordefinierten Regeln, die erlaubte und unerlaubte Inhalte festlegen. Mithilfe dieser "Verfassung" generiert das System synthetische Trainingsbeispiele in verschiedenen Sprachen und Stilen. Diese dienen als Grundlage für das Training der Klassifikatoren, die später verdächtige Eingaben erkennen sollen.
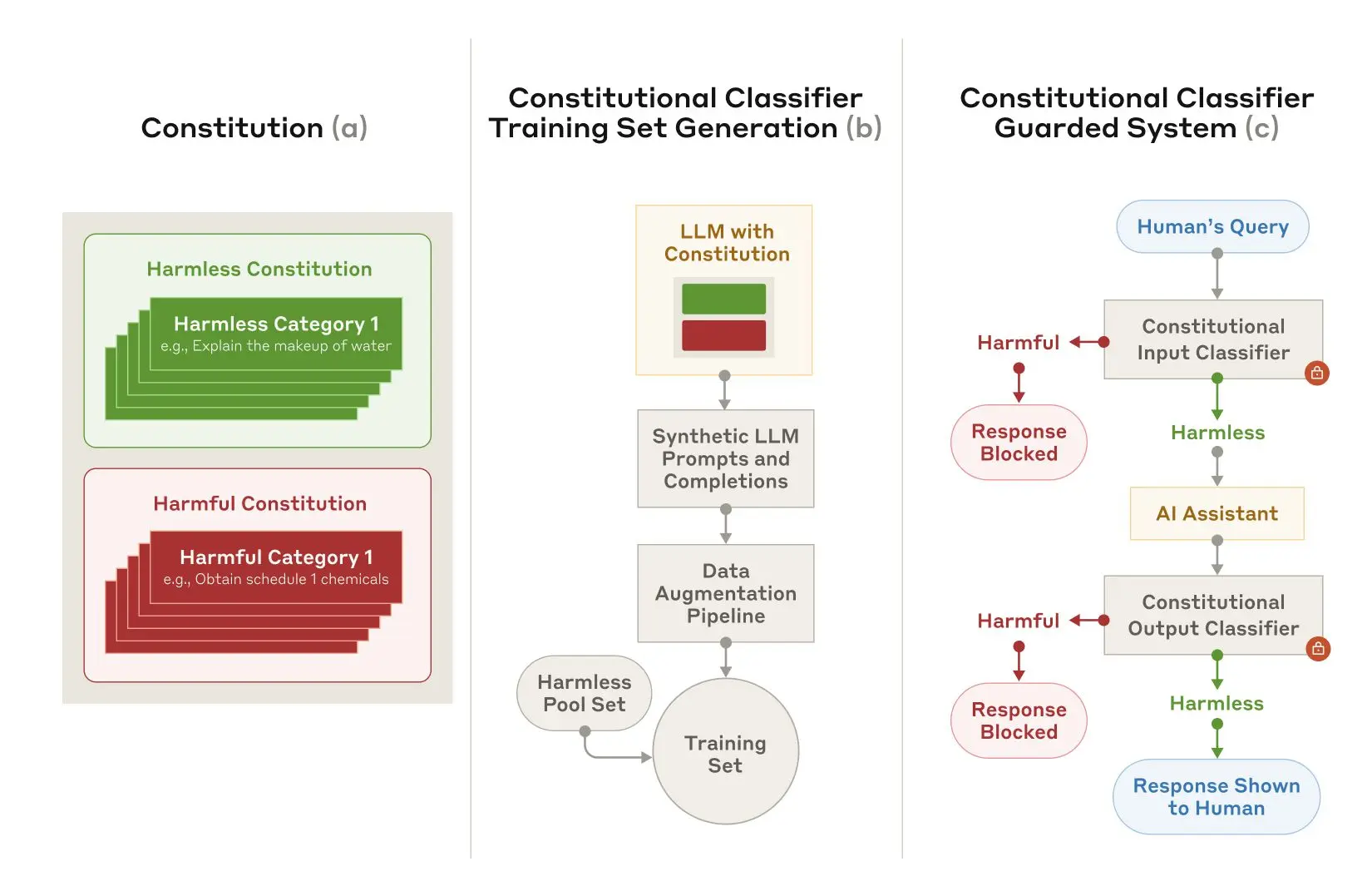
Die Forscher räumen ein, dass die Technik nicht jeden Universal Jailbreak verhindern kann. Auch könnten in Zukunft neue Angriffsmethoden entwickelt werden, gegen die das System machtlos ist. Anthropic empfiehlt daher, zusätzliche Sicherheitsmaßnahmen zu implementieren.
Um die Robustheit weiter zu testen, hat das Unternehmen eine öffentliche Demo-Version veröffentlicht. Vom 3. bis 10. Februar 2025 können Experten versuchen, das System zu überlisten. Die Ergebnisse sollen in einem Update veröffentlicht werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.