Neues KI-Framework wechselt automatisch zwischen Denkarten für bessere Effizienz
Das Framework SwiReasoning soll großen Sprachmodellen dabei helfen, effizienter zu denken. Das System wechselt automatisch zwischen verschiedenen Reasoning-Modi und verbessert dabei sowohl Genauigkeit als auch Token-Verbrauch.
Ein Forschungsteam der Georgia Tech und Microsoft hat das Framework SwiReasoning entwickelt, das zwei unterschiedliche Ansätze des maschinellen "Denkens" kombiniert. Laut den Entwickler:innen stellt das Framework eine "konzeptionell einfache, aber empirisch effektive" Lösung für verbessertes LLM-Reasoning dar, die sowohl die Genauigkeit als auch die Effizienz von KI-Systemen bei komplexen Denkaufgaben steigern soll.
Video: Shi et al.
Automatische Umschaltung basierend auf Unsicherheit
Das Kernprinzip von SwiReasoning basiert auf der automatischen Umschaltung zwischen zwei Denkarten, Chain-of-Thought und latentem Reasoning. Während Chain-of-Thought-Prozesse schrittweise und explizit in natürlicher Sprache erfolgen, arbeitet das latente Reasoning im kontinuierlichen Vektorraum des Modells, ohne Textausgabe nach außen.
SwiReasoning steuert den Wechsel zwischen diesen Modi anhand der Unsicherheit des Modells, die durch die Entropie der Token-Wahrscheinlichkeiten gemessen wird. Eine niedrige Entropie steht für hohe Sicherheit, eine hohe Entropie für Unsicherheit.
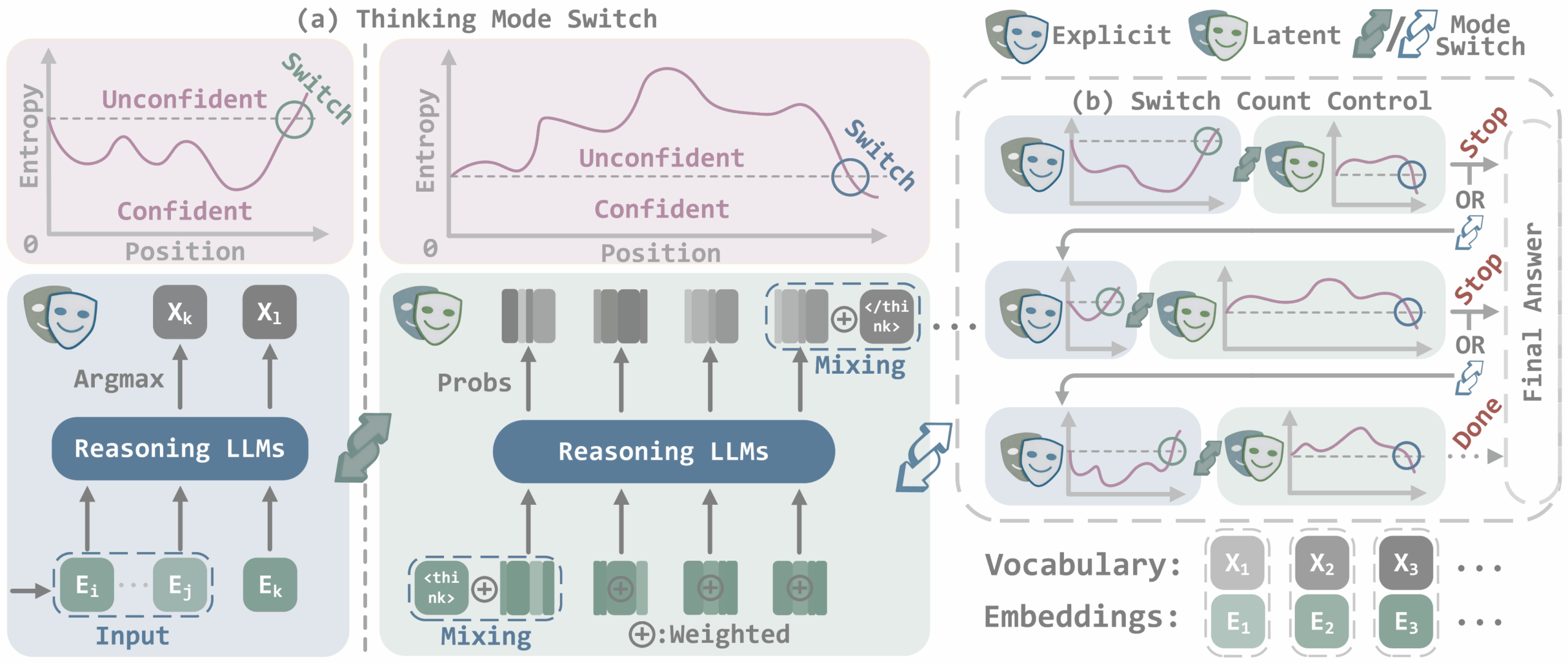
Sinkt die Unsicherheit, schaltet das System vom latenten in den expliziten Modus, um die aktuelle Gedankenkette zu konsolidieren. Steigt die Unsicherheit wieder, wechselt es zurück in den latenten Modus, um alternative Lösungswege im Vektorraum zu prüfen.
Um ständige Wechsel zu verhindern, nutzt SwiReasoning asymmetrische Verweilzeiten: Der Wechsel zum expliziten Modus kann sofort erfolgen, der Rückwechsel jedoch erst nach einer Mindestanzahl an Schritten.
Kontrolle gegen endloses Grübeln
Ein weiterer zentraler Mechanismus ist die Begrenzung der Modusumschaltungen, um sogenanntes „Overthinking“ zu vermeiden. SwiReasoning setzt hierbei eine Obergrenze für die Anzahl der Wechsel zwischen latentem und explizitem Denken.
Wird die Hälfte dieses Limits erreicht, aktiviert sich ein Mechanismus, der das Modell dazu anregt, seine Denkphase zu beenden. Bei Überschreitung der maximalen Zahl erzwingt das Framework die sofortige Generierung einer Antwort. So verhindert SwiReasoning, dass das Modell unnötig viele Tokens für ergebnisloses Nachdenken verbraucht.
Leichte Verbesserungen bei schwierigen Aufgaben
Die Entwickler:innen testeten SwiReasoning auf drei aktuellen, kleineren Modellen unter zehn Milliarden Parametern, nämlich Qwen3-8B, Qwen3-1.7B und einer destillierten Variante von Deepseek R1 mit acht Milliarden Parametern.
Die Evaluation erfolgte auf fünf Benchmarks für Mathematik und naturwissenschaftliche Aufgaben, darunter Grundschul-Mathematik, Hochschul-Wettbewerbsaufgaben und Graduierten-Level-Fragen.
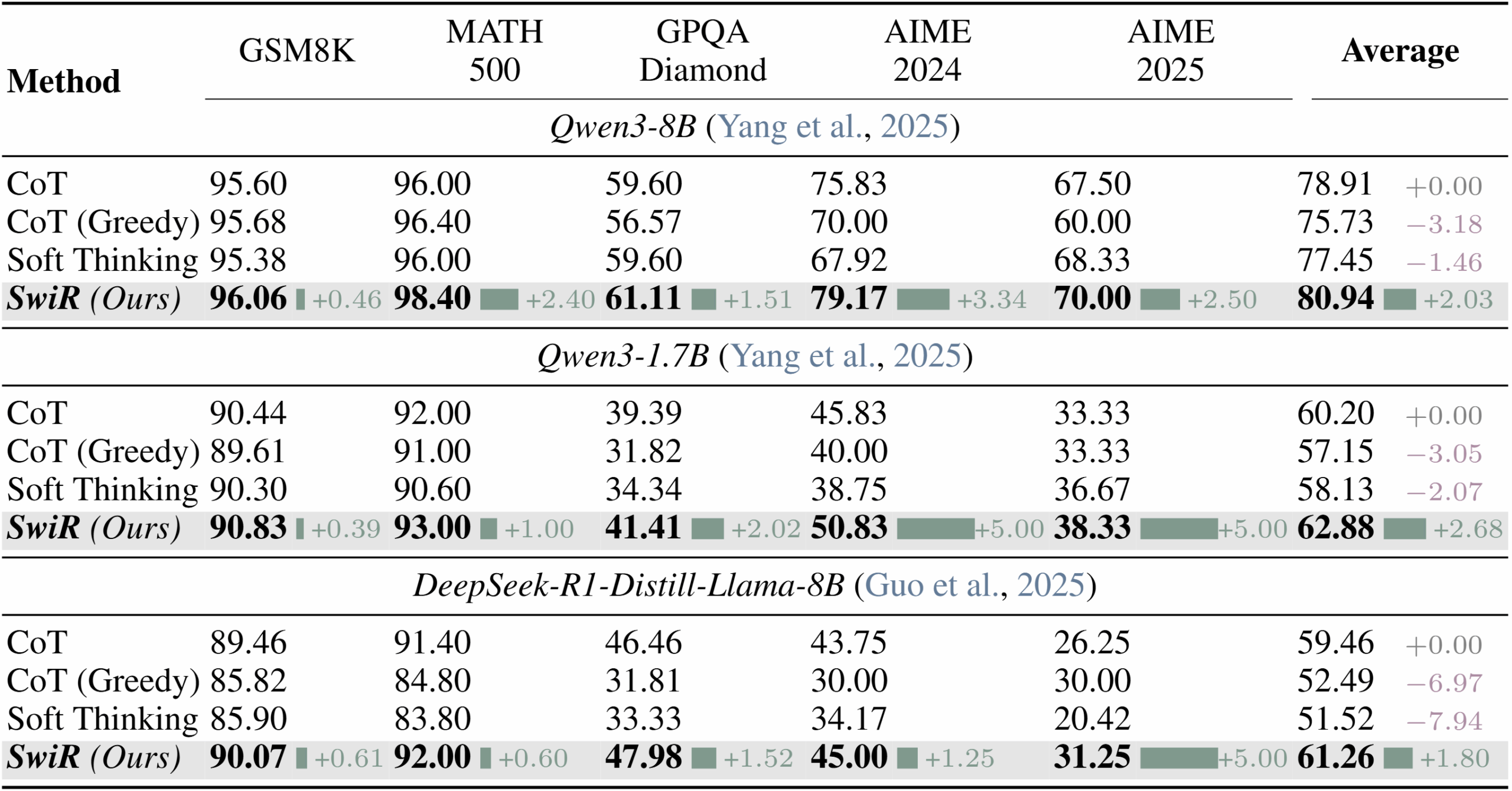
Ohne Token-Beschränkung erreichte SwiReasoning Genauigkeitssteigerungen von bis zu 2,8 Prozent bei Mathematik- und 2 Prozent bei naturwissenschaftlichen Aufgaben. Besonders bei anspruchsvollen Benchmarks zeigte sich der größte Zugewinn mit Absolutwerten von mehr als drei Prozentpunkten.
Die Forschenden schließen daraus, dass der intelligente Wechsel zwischen Denkmodi besonders bei komplexen Aufgaben mit langen Reasoning-Ketten von Vorteil ist.
Deutlich höhere Token-Effizienz
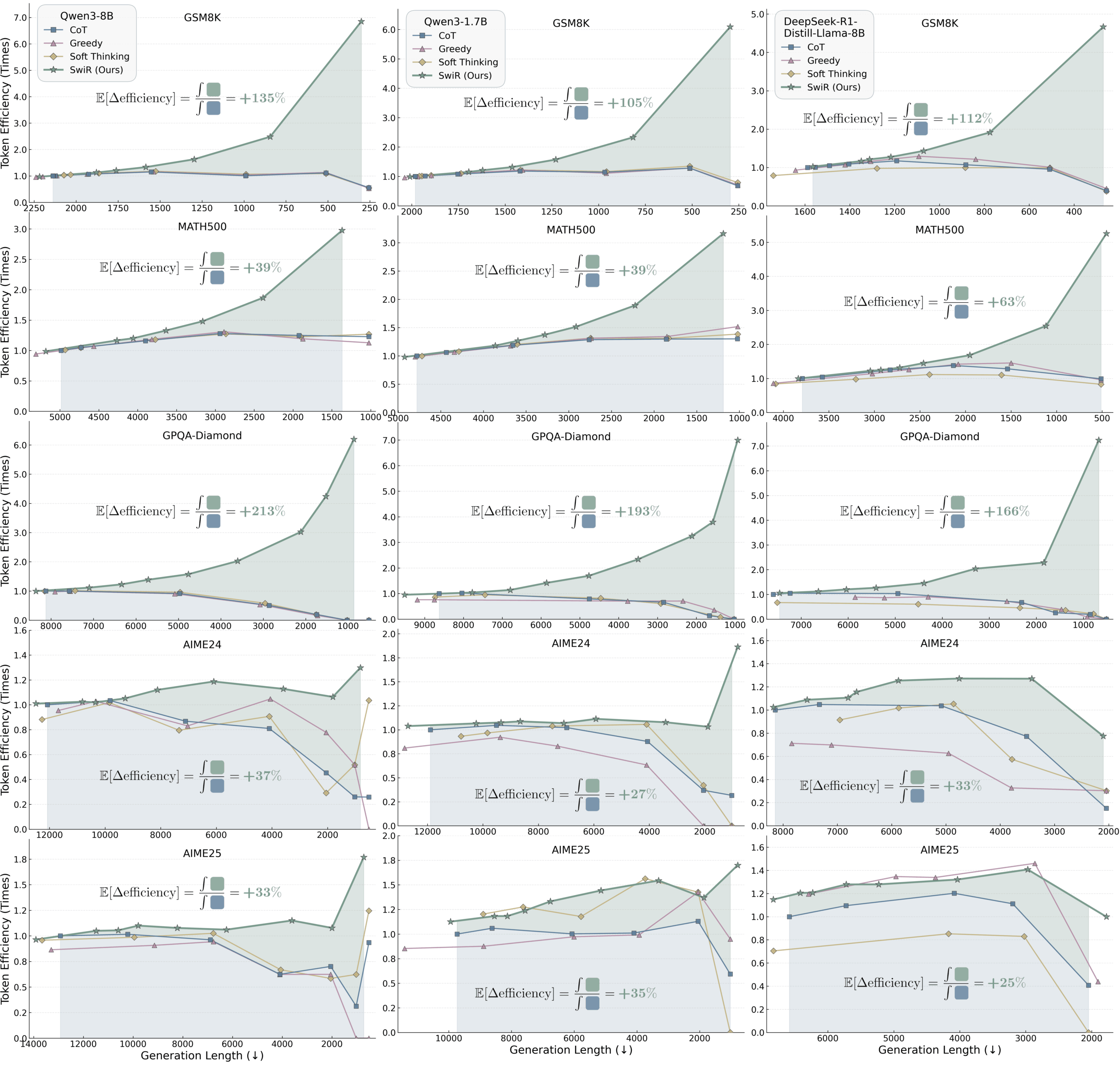
Unter begrenzten Token-Budgets traten die Vorteile noch deutlicher hervor. SwiReasoning steigerte die Token-Effizienz – also die erreichte Genauigkeit pro Token – um 56 bis 79 Prozent, in einzelnen Fällen sogar auf das 6,8-Fache gegenüber Standard-Chain-of-Thought.
Die Token-Effizienz misst, wie viel Genauigkeit pro verbrauchtem Token erreicht wird. Eine höhere Effizienz bedeutet, dass das Modell mit weniger Rechenaufwand bessere Ergebnisse erzielt.
Bei Experimenten mit mehreren Antwortversuchen benötigte SwiReasoning teils deutlich weniger Wiederholungen, um die maximale Genauigkeit zu erreichen: in einem Fall nur 13 Versuche statt 46, also 72 Prozent weniger als herkömmliche Ansätze.
SwiReasoning kommt ohne zusätzliches Training aus. Es lässt sich direkt als Ersatz für Standard-Generierungsfunktionen in bestehenden Modellen einsetzen, ohne Änderungen an Architektur oder Parametern.
Die Implementierung steht auf GitHub zur Verfügung und kann mit weiteren Effizienzmethoden wie Speicheroptimierung oder beschleunigtem Decoding kombiniert werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.