Nvidias Blackwell trainiert GPT-4 in 10 Tagen - aber löst das die Probleme aktueller Modelle?
Die Computex-Präsentation von Nvidia zeigt, warum die Skalierung großer KI-Modelle gerade erst begonnen hat. Aber werden dadurch die bestehenden Probleme heutiger Modelle gelöst?
Nvidia hat auf der Computex 2024 in Taiwan einen Ausblick auf seine GPU- und Interconnect-Roadmap bis 2027 gegeben. In seiner Keynote betonte CEO Jensen Huang die Notwendigkeit, die Leistung kontinuierlich zu steigern und gleichzeitig die Kosten für Training und Inferenz zu senken, damit jedes Unternehmen KI nutzen kann.
Huang verglich die Entwicklung der GPU-Leistung über einen Zeitraum von acht Jahren: Zwischen der "Pascal" P100 GPU-Generation und der "Blackwell" B100 GPU-Generation, die noch in diesem Jahr ausgeliefert wird, konnte die Leistung um mehr als das 1.000-fache gesteigert werden. Ein großer Teil davon ist auf die Reduzierung der Fließkomma-Genauigkeit zurückzuführen. So setzt Nvidia bei Blackwell stark auf FP4.
Durch diese Leistungssteigerung soll es laut Huang möglich sein, ein Modell wie GPT-4 mit 1,8 Billionen Parametern auf 10.000 B100-GPUs in nur zehn Tagen zu trainieren.
Allerdings sind auch die GPU-Preise in den letzten acht Jahren um den Faktor 7,5 gestiegen. Ein B100 wird voraussichtlich zwischen 35.000 und 40.000 US-Dollar kosten. Dennoch übertrifft der Leistungszuwachs den Preisanstieg bei weitem.
Skalierung jenseits der Modellgröße: Trainingsdaten und Iterationen
Die mit der neuen Hardware geplanten Supercomputer schaffen die Grundlage für eine weitere Skalierung der KI-Modelle. Diese Skalierung betrifft nicht nur die reine Erhöhung der Parameterzahl, sondern auch das Training von KI-Modellen mit deutlich mehr Daten. Insbesondere multimodale Datensätze, die verschiedene Informationsarten wie Text, Bild, Video und Audio kombinieren, werden in den nächsten Jahren die Zukunft großer KI-Modelle bestimmen. OpenAI hat kürzlich mit GPT-4o die erste Iteration eines solchen Modells vorgestellt.
Darüber hinaus ermöglicht die gestiegene Rechenleistung schnellere Iterationen beim Testen verschiedener Modellparameter. Unternehmen und Forschungseinrichtungen können so effizienter die optimale Konfiguration für ihre Anwendungsfälle ermitteln, bevor sie einen besonders rechenintensiven finalen Trainingslauf starten.
Die Beschleunigung betrifft auch den Inferenzbetrieb: Echtzeitanwendungen wie die OpenAI-Sprachdemos von GPT-4o werden möglich.
Auch die Konkurrenz, etwa Elon Musks xAI, wird solche Modelle trainieren. Er kündigte kürzlich an, dass sein KI-Startup xAI bis zum Sommer 2025 ein Rechenzentrum mit 300.000 Nvidia Blackwell B200 GPUs in Betrieb nehmen will. Außerdem soll in wenigen Monaten ein System mit 100.000 H100-GPUs online gehen. Ob sein Unternehmen diese Pläne umsetzen kann, ist unklar. Die Kosten dürften deutlich über 10 Milliarden US-Dollar liegen. Das liegt immer noch weit unter den 100 Milliarden, die OpenAI und Microsoft angeblich für Projekt Stargate veranschlagen.
Mehr Rechenleistung, mehr Echtzeit - aber dieselben Probleme?
Unklar ist jedoch, ob die Skalierung auch dazu beitragen kann, grundlegende Probleme heutiger KI-Systeme zu lösen. Dazu gehören beispielsweise ungewollte "Halluzinationen", bei denen Sprachmodelle überzeugend klingende, aber faktisch falsche Antworten generieren.
Einige Forscher, darunter die Autoren der "Platonic Representation Hypothesis", vermuten, dass die Verwendung großer Mengen multimodaler Trainingsdaten hier Abhilfe schaffen könnte. Metas KI-Chef Yann LeCun oder Gary Marcus halten solche Halluzinationen und das mangelnde Verständnis der Welt dagegen für eine grundsätzliche Schwäche generativer KI, die sich nicht allein durch Skalierung beheben lässt.
Mit der bald verfügbaren Hardware können diese Fragen experimentell beantwortet werden - verlässliche Modelle wären jedenfalls im Interesse der Unternehmen, da sie den Einsatz in vielen kritischen Anwendungsbereichen ermöglichen würden.
Nächster Schritt: "Physical AI"?
Ein möglicher Weg dorthin könnten KI-Modelle sein, die mehr von der physikalischen Welt verstehen: "Die nächste KI-Generation muss physikalisch fundiert sein, die meisten heutigen KI-Systeme verstehen die Gesetze der Physik nicht, sie sind nicht in der physikalischen Welt verankert", so Huang in seiner Präsentation.
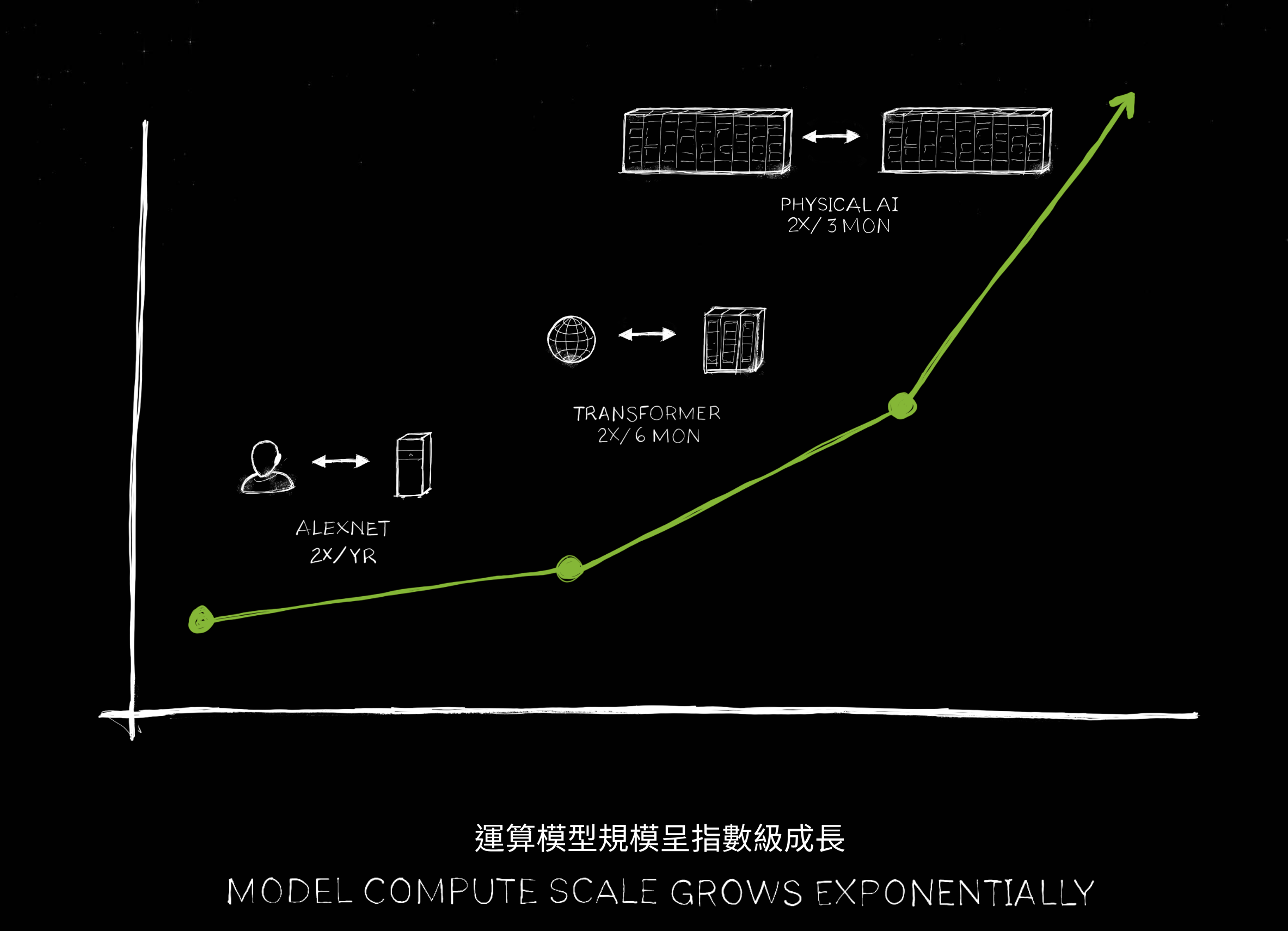
Er erwartet, dass solche Modelle nicht nur aus Videos lernen, wie OpenAIs Sora, sondern auch in Simulationen und voneinander lernen - ähnlich Systemen wie Deepminds AlphaGo. "Die Datengenerierung wird daher wohl weiter zunehmen, und mit jeder Datengenerierung muss auch die Rechenleistung wachsen, die wir anbieten können. Wir müssen in eine Phase eintreten, in der die KI in der Lage ist, die Gesetze der Physik zu lernen und Daten aus der physikalischen Welt zu verstehen und darauf aufzubauen. Wir gehen davon aus, dass die Modelle weiter wachsen werden und wir auch größere GPUs brauchen."
Jährliche Chip-Updates sollen Nvidias Dominanz erhalten
Dieser Anstieg an benötigter Rechneleistung liegt natürlich im Interesse des Unternehmens - und Nvidia gab auch Details zu den nächsten GPU-Generationen bekannt: 2025 soll "Blackwell Ultra" (B200) folgen, 2026 "Rubin" (R100) und 2027 "Rubin Ultra". Hinzu kommen Verbesserungen bei den zugehörigen Interconnects und Netzwerk-Switches. Für 2026 ist zudem mit "Vera" ein Nachfolger für Nvidias "Grace"-Arm-CPU geplant.

Mit Blackwell Ultra, Rubin und Rubin Ultra will Nvidia seine Vormachtstellung im Hardwaremarkt für KI-Anwendungen durch jährliche Updates weiter ausbauen. Mit den Hopper-Chips hat das Unternehmen hier bereits eine Quasi-Monopolstellung erreicht. AMD und Intel versuchen mit eigenen KI-Beschleunigern an dieser Vormachtstellung zu rütteln.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.