o1: Nutzer teilen erste Eindrücke zu OpenAIs neuem KI-Modell

Die Ankündigung des neuen OpenAI-Modells war mit großen Erwartungen verbunden. Nun liegen erste externe Einschätzungen vor, die einige Hoffnungen bestätigen, andere aber auch enttäuschen.
OpenAIs Veröffentlichung des neuen "Strawberry"-Modells, seit gestern offiziell bekannt als o1-preview und o1-mini, hat in der KI-Community für Aufsehen gesorgt. Das Modell, das darauf ausgelegt ist, vor einer Antwort besonders ausführlich zu "denken", könnte einen bedeutenden Fortschritt in den Fähigkeiten großer Sprachmodelle darstellen. Doch ganz so klar ist das bisher nicht. KI-Expert:innen und Forscher:innen teilen ihre ersten Eindrücke und Meinungen zu o1, die zum Teil auf eigenen Erfahrungen dank des frühzeitigen Zugriffs auf das Modell basieren.
Selbst KI-Kritiker Gary Marcus ist zunächst beeindruckt
Gary Marcus, ein bekannter KI-Forscher und Kritiker des starken KI-Fokus auf reine generative Modelle, teilte seine Gedanken über das neue Modell auf X mit. Er räumt ein, dass das Modell "definitiv beeindruckend" sei, weist aber insbesondere auf die Einschränkungen hin. Er sieht das neue Modell nicht als einen Schritt in Richtung einer allgemeinen KI und bemängelt das Fehlen detaillierter Informationen über die Funktionsweise des Modells und das Fehlen einer vollständigen Offenlegung der Benchmarks.
Außerdem fehlt das neue "vollständige" Modell, das OpenAI in Benchmarks gezeigt hat. Stattdessen bekommen zahlende Abonnent:innen mit o1-Preview lediglich eine Vorschau. Dies schränkt die Möglichkeiten der wissenschaftlichen Gemeinschaft ein, die Fähigkeiten von o1 gründlich zu testen und die Behauptungen von OpenAI zu überprüfen.
Die Kernfunktionalität von o1 ist es, sich buchstäblich Zeit zum Nachdenken zu nehmen. In der Erzählung von OpenAI werden die Ergebnisse umso besser, je mehr Zeit o1 zum Nachdenken hat - aber Marcus bezweifelt das, da es dafür noch keine stichhaltigen Beweise gebe.
Das Argument, dass es coole Sachen in ein paar Sekunden macht, und deshalb erstaunlich sein wird, wenn man es einen Monat laufen lässt, ist SEHR spekulativ und wird wahrscheinlich nicht annähernd so gut funktionieren, wie OpenAI Sie glauben machen will. (Ich sehe nicht einmal Daten, die zeigen, dass es einen großen Unterschied macht, ob man das System eine Woche oder eine Minute laufen lässt.)
Gary Marcus auf X
"Erstaunlich, aber noch eingeschränkt"
Der Wissenschaftler Ethan Mollick, der seit einigen Wochen Zugang zu o1 hat, teilte seine Erkenntnisse in einem ausführlichen Beitrag. Er beschreibt das Modell als "erstaunlich, noch eingeschränkt und, vielleicht am wichtigsten, ein Signal dafür, wohin die Dinge gehen." Mollick hebt die Fähigkeit des Modells hervor, schwierige Probleme zu lösen, die Planung und Iteration erfordern, wie neuartige Mathematik- oder Wissenschaftsfragen.
Mollick weist aber auch darauf hin, dass das Modell seinen Vorgänger nicht in allen Bereichen schlägt. So sei es zum Beispiel beim Schreiben nicht überlegen, was auch die eigenen Auswertungen von OpenAI zeigten. Er demonstriert die Fähigkeiten und Grenzen des Modells anhand eines komplexen Kreuzworträtsels, bei dem das Modell zunächst Schwierigkeiten hatte, es aber nach einem entscheidenden Hinweis richtig löste.
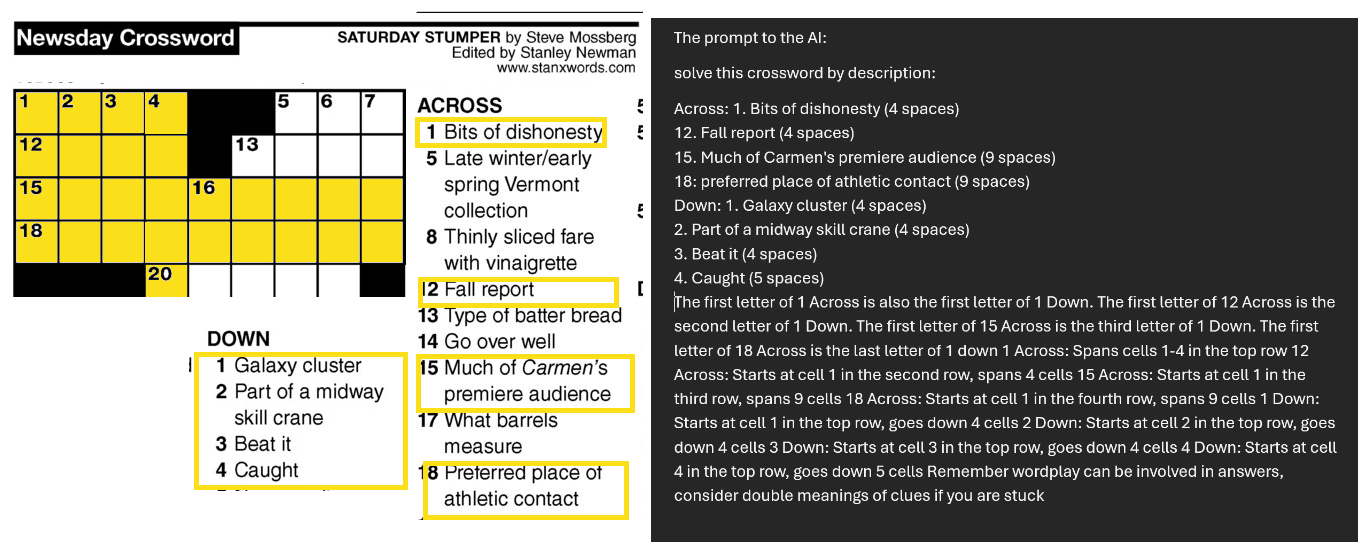
Mollick merkt an, dass die Planungsfähigkeiten des Modells zwar eine Form von Handlungsfähigkeit darstellen, aber dennoch Fehler und Halluzinationen auftreten und es durch die zugrundeliegende Intelligenz von GPT-4o begrenzt bleibt.
Prompts werden (noch) wichtiger?
Andrew Mayne, ehemaliger OpenAI-Mitarbeiter und ein weiterer KI-Experte mit frühzeitigem Zugang zum Modell, gab auf X Ratschläge zur effektiven Nutzung von o1. Er betont, wie wichtig es sei, das Modell als einen "wirklich klugen Freund" zu betrachten und detaillierte, gut durchdachte Prompts zu liefern.
Mayne empfiehlt, o1-mini für Aufgaben zu verwenden, die weniger Weltwissen erfordern, aber von schrittweisem Denken profitieren. Er beobachtete, dass o1 dazu neigt, sowohl die Schritte als auch die vollständige Antwort zu geben, während o1-mini sich nur auf die Schritte konzentriert.
Laut OpenAI sollten Prompts einfach und direkt formuliert werden und das Modell nicht zu stark leiten, da sie Anweisungen bereits gut verstehen würden. Auf ergänzende Chain-of-Thought-Anweisungen (Schritt für Schritt) sollte verzichtet werden, da die Modelle bereits intern logisch schlussfolgern würden.
Zur Klarheit empfiehlt OpenAI die Verwendung von Abgrenzungen wie dreifachen Anführungszeichen, XML-Tags und Überschriften. Bei der Nutzung der Modelle für Retrieval Augmented Generation (RAG) rät OpenAI davon ab, zu viel zusätzlichen Kontext hinzuzufügen, da dies die Antworten der Modelle verkomplizieren könnte.
Entwickler Simon Willison geht in einem Blogbeitrag auf die Details der neuen Modelle ein und hob wichtige Informationen aus der API-Dokumentation hervor. So stört ihn die Einführung von "Reasoning Tokens", die in der API-Antwort nicht sichtbar sind, aber dennoch abgerechnet und als Output-Tokens gezählt werden. Sie stellen den "Denkprozess" des Modells dar.
Ich bin mit dieser Entscheidung überhaupt nicht zufrieden. Als jemand, der mit und für LLMs entwickelt, sind Interpretierbarkeit und Transparenz alles für mich - die Vorstellung, dass ich eine komplexe Eingabe machen kann und wichtige Details darüber, wie diese Eingabe bewertet wurde, vor mir verborgen bleiben, fühlt sich wie ein großer Rückschritt an.
Simon Willison
Willison ist frustriert von OpenAIs Entscheidung, diese Reasoning Tokens zu verbergen, und erinnert daran, dass Interpretierbarkeit und Transparenz bei der Entwicklung von LLMs Vorrang haben sollten.
Erste Experimente mit o1-preview
Da OpenAI das Modell schnell für viele ChatGPT-Nutzer:innen freigeschaltet hat, finden sich bereits zahlreiche Beispielinteraktionen mit dem neuen Modell. Einige davon demonstrieren eindrucksvoll den Fortschritt, andere lassen Zweifel aufkommen. ChatGPT, auch mit dem neuen GPT-4o, hat bekanntermaßen Probleme, Wörter mit bestimmten Buchstaben aufzulisten oder Buchstaben zu zählen. Berühmt wurde der Test, die "R"s in "Strawberry" zu zählen, den GPT-4o nicht zuverlässig bewältigen kann.
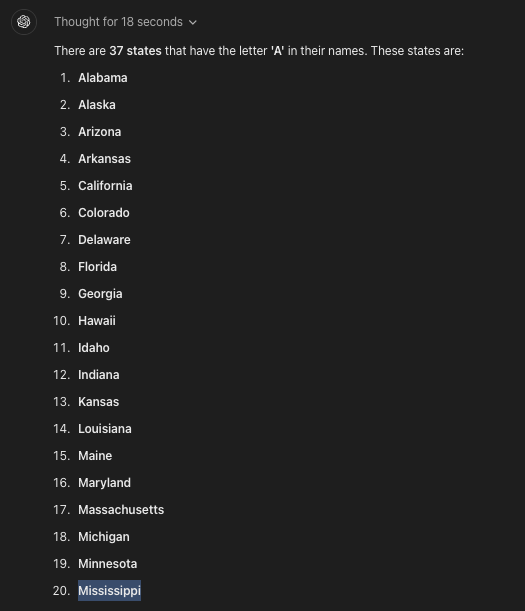
Während o1-preview diese Zählaufgabe endlich verlässlich meistert, versagt es laut einem Beitrag von Ed Zitron dabei, alle US-Staaten zu nennen, die ein "a" enthalten - denn an 20. Stelle ist "Mississippi" zu lesen. Dabei soll o1-preivew zuvor 18 Sekunden nachgedacht haben.
Allerdings gibt es auch positive Beispiele, etwa beim Schreiben eines Gedichtes, das sehr spezifischen Regeln folgen soll. Kein anderes Sprachmodell hätte diese komplexe Aufgabe erfüllen können, so Mehran Jalali.

Ammaar Reshi hat o1 mit dem KI-Entwickler Cursor kombiniert und demonstriert, dass sich so in unter zehn Minuten eine iOS-Wetter-App programmieren lässt, inklusive Animationen.
Video: Ammaar Reshi/X
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.