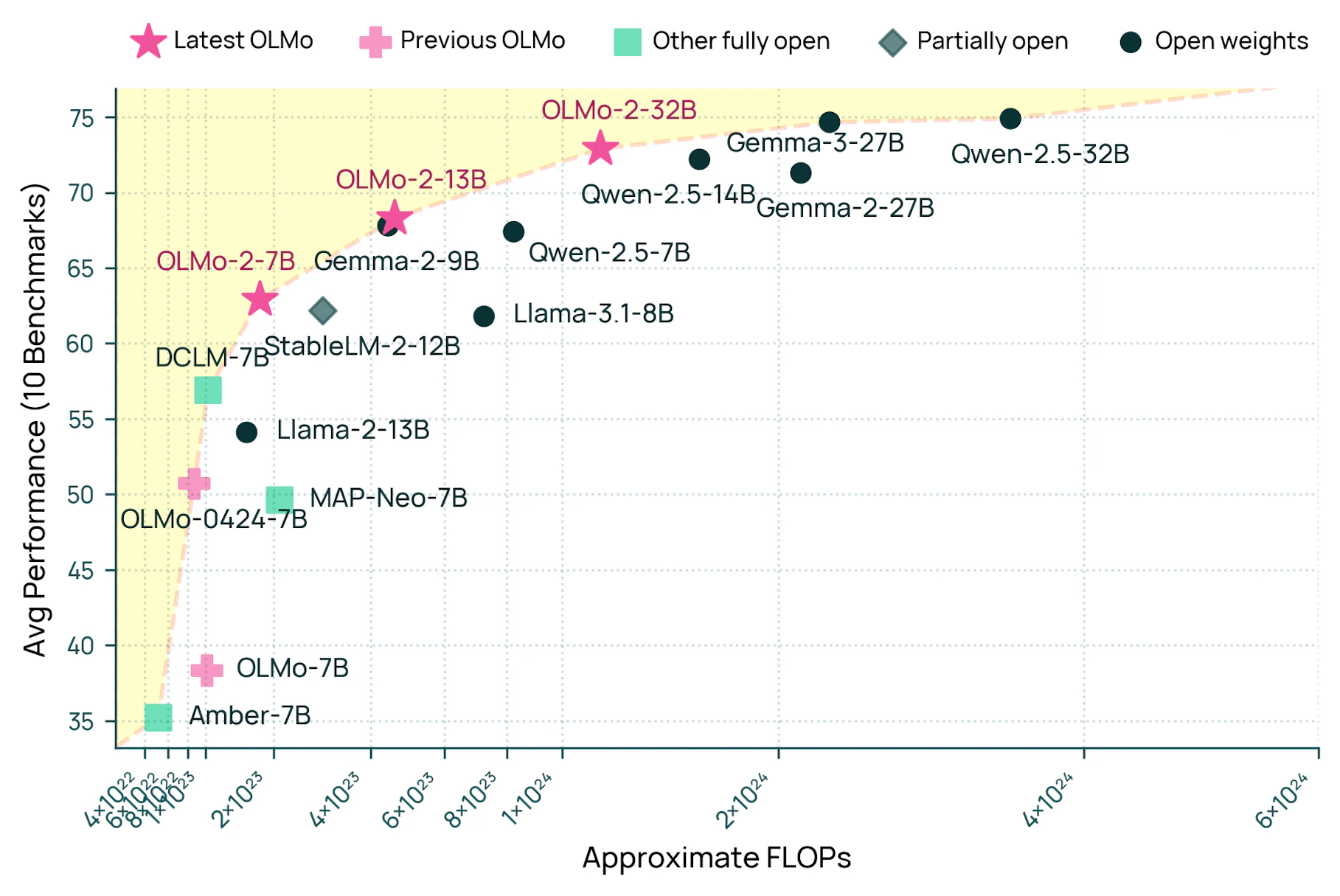
OLMo 2 32B ist das beste echte Open-Source-Modell
Es bleibt ein Katz-und-Maus-Spiel in der KI-Entwicklung zwischen dem offenen und geschlossenen Ansatz. Das neue OLMo-Modell ist so gut wie manche OpenAI-Modelle, aber vollständig transparent.
Laut einer Ankündigung vom Allen Institute for Artificial Intelligence (Ai2) markiert das neue Sprachmodell OLMo 2 32B einen wichtigen Meilenstein in der Entwicklung offener KI-Systeme.
Das Besondere: Erstmals ist ein Modell, bei dem sowohl der Programmcode als auch die Trainingsdaten und alle weiteren Details öffentlich zugänglich sind, leistungsfähiger als die etablierten, geschlossenen Systeme GPT-3.5-Turbo (veröffentlicht im März 2023) und GPT-4o mini (Juli 2024).
Bemerkenswert ist dabei der Ressourceneinsatz: Nach Angaben von Ai2 benötigte das Training von OLMo 2 32B nur ein Drittel der Rechenleistung im Vergleich zum ähnlich leistungsfähigen Modell Qwen2.5-32B. Das mache das System besonders interessant für Forschung und Entwicklung mit begrenztem Budget.
Das Training des Modells erfolgte laut Ai2 in drei aufeinander aufbauenden Phasen: Zunächst lernte das System grundlegende Sprachmuster aus einem Datensatz von 3,9 Billionen Tokens. In der zweiten Phase sei es mit hochwertigen Dokumenten und akademischen Inhalten weiter trainiert worden.
Die finale Phase konzentrierte sich darauf, dem Modell beizubringen, Anweisungen zu befolgen und qualitativ hochwertige Antworten zu generieren. Dafür nutzte das Team das Tulu-3.1-Framework, das verschiedene, bewährte Trainingsmethoden wie überwachtes Lernen und Verstärkungslernen kombiniert.
Rechenarbeit effizient zwischen Trainingscomputern aufgeteilt
Für das Training entwickelte das Team eine komplett neue Software-Plattform namens OLMo-core. Diese ermöglicht es, die Rechenarbeit besser zwischen vielen Computern aufzuteilen und Zwischenergebnisse effizient zu speichern, ohne das Training zu unterbrechen.
Das Training selbst fand mithilfe von Google-Ingenieuren auf dem KI-Supercomputer Augusta statt, der aus 160 vernetzten Rechnern mit jeweils acht leistungsstarken H100-Grafikprozessoren besteht. Durch kontinuierliche Optimierungen der Software und Systemeinstellungen erreichte das Team eine Verarbeitungsgeschwindigkeit von mehr als 1.800 Token pro Sekunde pro Grafikprozessor.
Das fertige Modell war bereits mit 7 und 13 Milliarden Parametern verfügbar, nun kommt die stärkste 32B-Variante hinzu. Sie kann auf einem einzelnen Computer mit H100-GPU an spezifische Aufgaben angepasst werden.
Mit Tülu-3-405B hat Ai2 im Januar bereits ein deutlich größeres Sprachmodell veröffentlicht, das sich auf Niveau leistungsfähigerer Modelle als GPT-3.5 und GPT-4o mini befindet. Bei diesem hatte das Labor aber keinen Anteil am Pretraining und es sei zudem nicht vollständig Open-Source, erklärt Nathan Lambert von Ai2.
Fokus auf Transparenz und Nachvollziehbarkeit
Die vollständige Offenlegung aller Entwicklungsschritte ermögliche es anderen Forscher:innen, die Funktionsweise besser zu verstehen und auf den Ergebnissen aufzubauen. Zusammen mit der gezeigten Leistung sei das ein "bedeutender Wandel" für Open-Source-KI, heißt es.
Mit ein paar weiteren Fortschritten kann jeder ein Pre-Training, Mid-Training, Post-Training oder was auch immer durchführen, um ein Modell der Klasse GPT-4 zu erhalten. Dies ist ein bedeutender Wandel in der Art und Weise, wie Open-Source-KI in reale Anwendungen hineinwachsen kann.
Nathan Lambert, Ai2
In den kommenden Monaten plant das Team nach eigenen Angaben weitere Verbesserungen, insbesondere im Bereich des logischen Schlussfolgerns. Auch die Unterstützung für längere Texteingaben, also ein größeres Kontextfenster, soll bald erweitert werden.
Was heißt eigentlich Open-Source-KI?
In der KI-Szene und in der Berichterstattung darüber wird der Open-Source-Begriff häufig inflationär verwendet. Grundsätzlich gibt es drei Säulen eines KI-Modells, die es zu einer wirklich quelloffenen Veröffentlichung und der Nachvollziehbarkeit benötigt: den Modellcode zur Ausführung (meist in Python auf GitHub gehostet); die Modellgewichte bzw. Parameter (meist auf Hugging Face gehostet); und das verwendete Trainingsmaterial.
Gerade letzteres wird von anderen Forschungslaboren, die sich Open-Source-Entwicklung auf die Fahne schreiben, oft unter Verschluss gehalten. Nicht so bei Ai2, die den verwendeten Trainingsdatensatz Dolmino kostenlos zur Verfügung stellen. Schon 2023 hatte Ai2 mit Dolma einen Datensatz für sich und andere Labore zusammengestellt, der nun auch in jenen für OLMo 2 eingeflossen ist.
Zusätzlich hat das Team verschiedene Checkpoints, also Versionen des Sprachmodells zu unterschiedlichen Zeitpunkten des Trainings, hochgeladen. Ein im Dezember parallel zu den 7B- und 13B-Versionen von OLMo 2 erschienenes Paper erklärt außerdem weitere technische Hintergründe.
18 Monate zwischen Open- und Closed-Source
Die Leistungsfähigkeit kleinerer Open-Source-Modelle hat sich in den vergangenen Monaten rasant entwickelt. Nach Einschätzung von Lambert liegt der Entwicklungsrückstand zu geschlossenen Systemen nur noch bei etwa 18 Monaten. Dabei konzentrieren sich Open-Source-Entwickler primär darauf, die Effizienz ihrer Modelle zu verbessern, statt einfach die Modellgröße zu erhöhen.
Im Vergleich zum kürzlich von Google veröffentlichten Gemma 3 27B zeigt OLMo 2 32B ähnliche Leistungen im Basis-Training. Allerdings schneidet Gemma 3 nach dem Post-Training, also der Feinabstimmung des Modells, deutlich besser ab. Lambert sieht darin einen Hinweis darauf, dass die Nachbearbeitungsrezepte für Open-Source-Modelle noch Verbesserungspotenzial haben.
Er geht davon aus, dass sich die Post-Trainingsmethoden im Open-Source-Bereich bis 2025 weiter verbessern werden, angetrieben durch den Bedarf an besserer Leistung und detaillierteren Workflows für das Training von Reasoning-Fähigkeiten.
Eine Demo für OLMo 2 32B und weitere Modelle von Ai2 finden sich AllenAi Chatbot-Playground.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.