Open-Source-LLM Jamba soll dank neuer KI-Architektur deutlich effizienter sein
Das israelische KI-Unternehmen AI21 Labs hat mit Jamba ein neues KI-Sprachmodell vorgestellt, das die Technologien Transformer und Structured State Space Modeling in einer leistungsstarken Hybridarchitektur kombiniert.
AI21 Labs, ein KI-Start-up aus Israel, hat das Sprachmodell Jamba angekündigt. Es ist das erste produktionsreife Modell, das auf einer Kombination der Transformer-Architektur und der Mamba Structured State Space Model (SSM) Architektur basiert. Dadurch soll Jamba bestehende Modelle in Bezug auf Effizienz und Kontextfenster übertreffen und gleichzeitig eine hohe Ausgabequalität bieten.
Architekturinnovation für mehr LLM-Effizienz
Mamba wurde von Forschenden der Carnegie Mellon University und der Princeton University entwickelt. Die SSM-basierte LLM-Architektur optimiert gezielt die Speicherauslastung und die Verarbeitungsgeschwindigkeit, die bei reinen Transformer-Modellen mit zunehmender Kontextlänge stark abnehmen.
Allerdings erreichen reine SSM-Modelle nicht die Ausgabequalität der besten Transformer-Modelle, insbesondere bei Aufgaben, die ein gutes Gedächtnis erfordern. AI21 kombiniert daher in der Jamba-Architektur beide Ansätze und ergänzt sie durch Mixture-of-Experts (MoE)-Schichten.
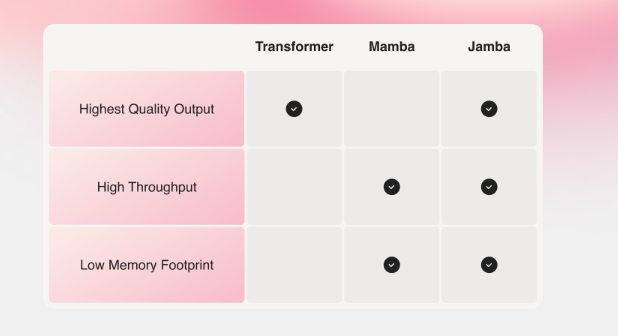
Laut AI21 ist Jamba der erste hybride SSM-Transformer, der auf Produktionsgröße skaliert wurde. Er bietet ein Kontextfenster von 256.000 Token und soll in ersten Tests eine dreimal höhere Verarbeitungsgeschwindigkeit für lange Kontexte erreichen als der Mixtral 8x7B Transformer. Jamba schafft ca. 1600 Token pro Sekunde, Mixtral ca. 550.
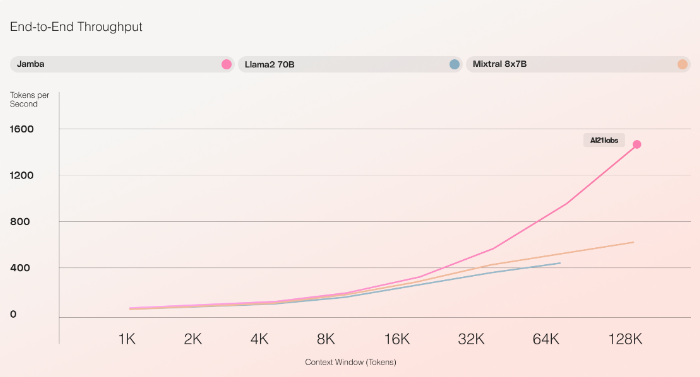
Fokus auf Effizienz bei hoher Output-Qualität
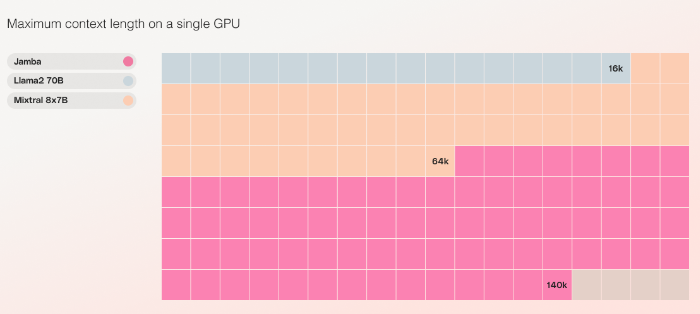
Jamba verwendet zwölf Milliarden seiner insgesamt 52 Milliarden Parameter zur Inferenz und soll diese effizienter nutzen als ein reines Transformer-Modell vergleichbarer Größe. Die zusätzlichen Parameter erhöhen die Leistungsfähigkeit des Modells, ohne den Rechenaufwand entsprechend zu erhöhen. Als bisher einziges Modell seiner Größenklasse soll Jamba bis zu 140.000 Token Kontext auf einer einzigen 80 GB High-End-GPU verarbeiten können.
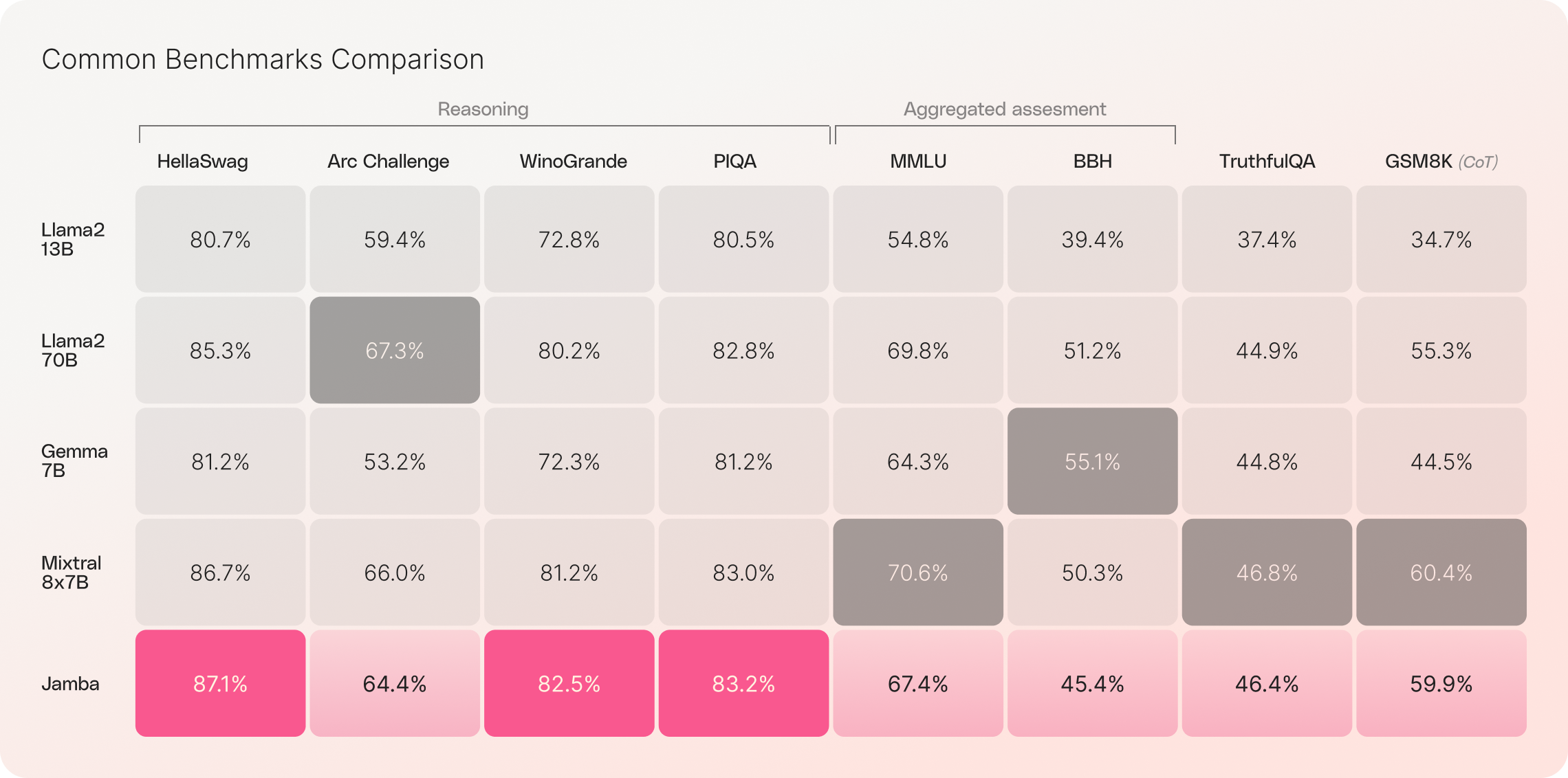
In Benchmarks liegt Jamba auf Augenhöhe mit Mixtral8x7B, bietet dabei allerdings die oben erwähnten Vorteile in Geschwindigkeit und Effizienz.
AI21 stellt die Gewichte des Jamba-Modells unter der Open-Source-Lizenz Apache 2.0 zur Verfügung und lädt Entwickler ein, mit dem Modell zu experimentieren und es weiterzuentwickeln. In Kürze wird auch eine Instruct-Version von Jamba als Beta über die Plattform von AI21 Labs verfügbar sein.
Jamba wird auch über den API-Katalog von Nvidia angeboten. Entwickler von Unternehmensanwendungen können Jamba dort über den Nvidia NIM Inference Microservice anbieten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.