Open-Source-Modell DeepCoder-14B soll OpenAIs o3-mini bei Code-Aufgaben erreichen
Agentica und Together AI veröffentlichen mit DeepCoder-14B ein neues offenes KI-Modell für Programmieraufgaben. Nach Angaben der Entwickler:innen soll es die Leistung proprietärer Systeme erreichen.
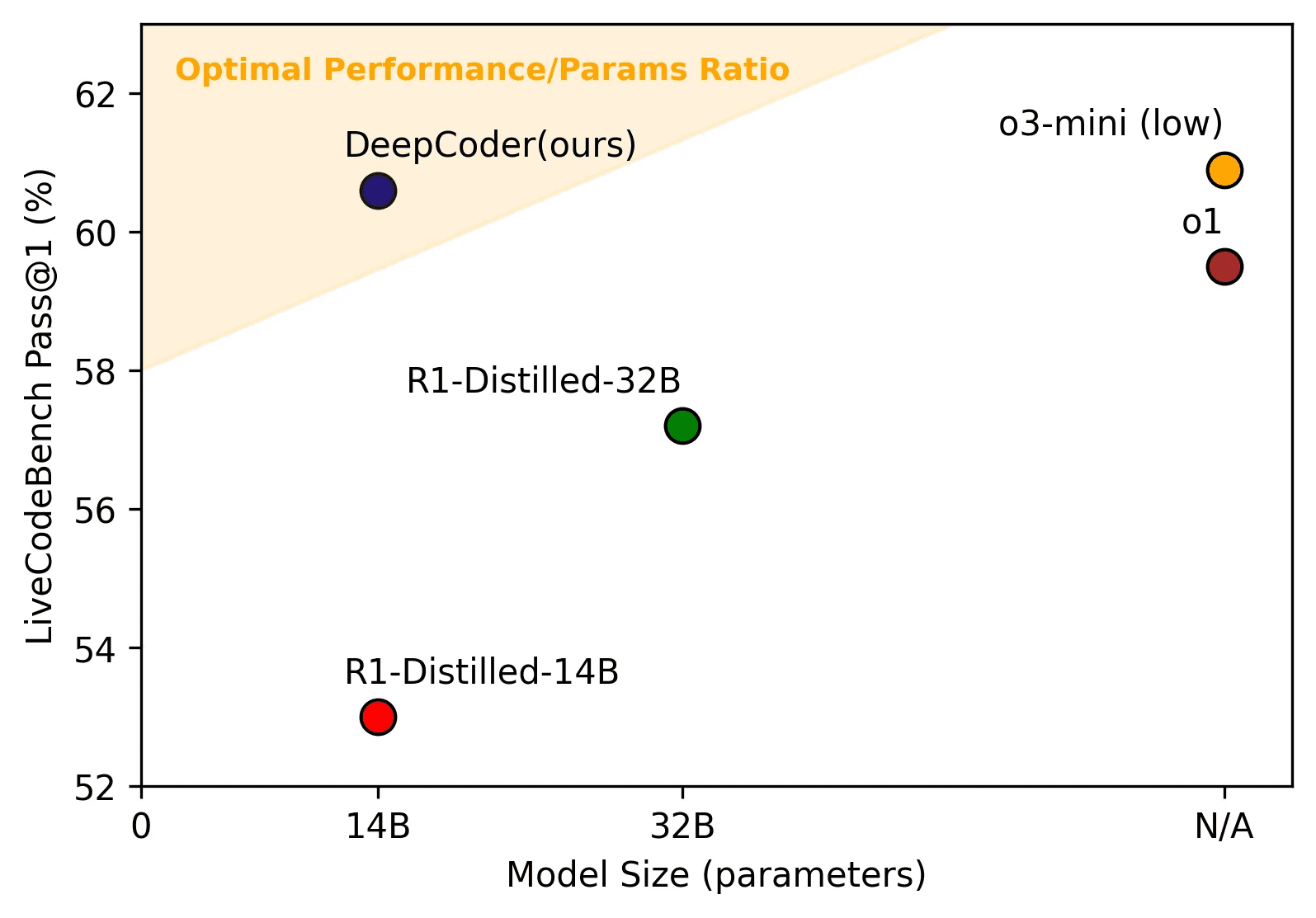
Der Trend zu kompakten Sprachmodellen mit offenen Trainingsdaten setzt sich im neuesten Modell von Together AI fort. Im LiveCodeBench-Test liegt DeepCoder-14B angeblich auf dem Niveau von OpenAIs geschlossenem o3-mini-Modell, ist aber mutmaßlich deutlich kleiner und damit auch auf weniger leistungsfähiger Infrastruktur einsetzbar.
Für das Training stellten die Forschenden einen Datensatz aus 24.000 Programmieraufgaben aus drei Quellen zusammen: dem TACO-Verified-Datensatz mit 7.500 Problemen, PrimeIntellects SYNTHETIC-1 mit 16.000 Problemen sowie 600 LiveCodeBench-Problemen.
Um die Datenqualität zu gewährleisten, musste laut den Entwickler:innen jede Aufgabe mindestens fünf Testfälle enthalten und eine verifizierte Lösung aufweisen. Bekannte Datensätze wie KodCode und LeetCode seien als zu einfach eingestuft worden, andere hätten zu viele fehlerhafte oder fehlende Testfälle enthalten. Das Training erfolgte den Angaben zufolge über zweieinhalb Wochen auf 32 H100-GPUs von Nvidia.
Für das Training nutze das System eine "sparse Outcome Reward"-Funktion: Das Modell erhalte nur dann eine Belohnung, wenn der generierte Code alle Testfälle bestehe. Bei Problemen mit sehr vielen Tests würden die 15 anspruchsvollsten ausgewählt.
Schrittweise Erweiterung des Kontextfensters und längere Antworten
Das Kontextfenster des Modells wurde nach Angaben der Entwickler:innen schrittweise von 16.000 auf 32.000 Token erweitert. Bei Tests mit einem 16.000-Token-Fenster habe das System eine Genauigkeit von 54 Prozent erreicht, bei 32.000 Token seien es 58 Prozent gewesen. Mit einem auf 64.000 Token erweiterten Kontextfenster habe das Modell schließlich mit 60,6 Prozent seinen Spitzenwert erreicht.
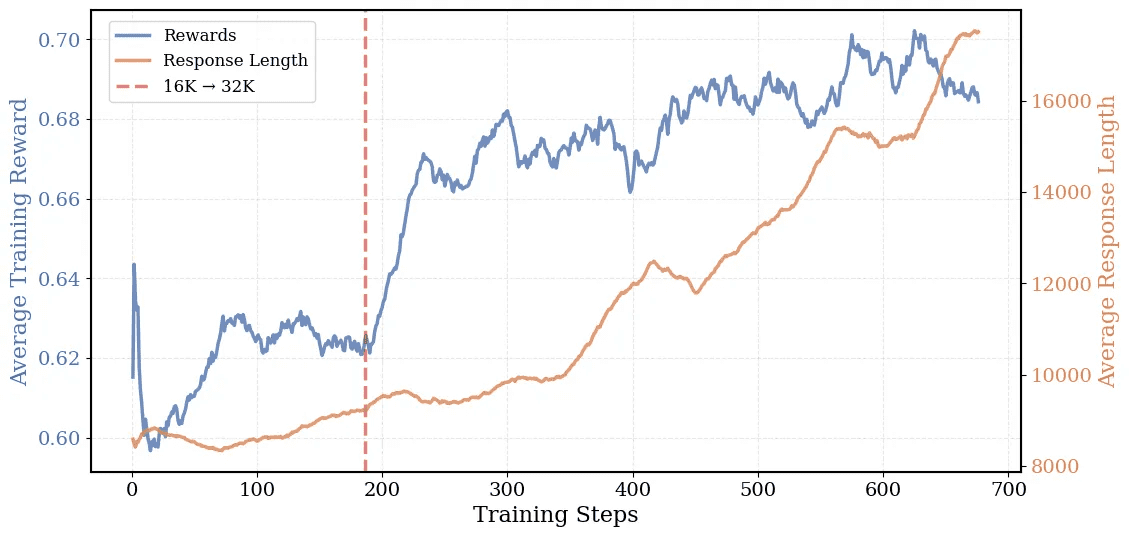
Diese Skalierung unterscheide das System von anderen Modellen wie DeepSeek-R1-Distill-Qwen-14B, auf dem DeepCoder-14B basiert und deren Leistung bei größeren Kontextfenstern stagniere. Die durchschnittliche Antwortlänge des Modells sei während des Trainings von 8.000 auf 17.500 Token gewachsen.
Neben der Programmierung soll das Modell auch bei mathematischen Aufgaben gute Ergebnisse erzielen. Bei AIME2024 habe es nach Angaben der Entwickler eine Genauigkeit von 73,8 Prozent erreicht - eine Verbesserung von 4,1 Prozent gegenüber dem Basismodell.
Die Entwickler:innen setzen nach eigenen Angaben auf ein neues Verfahren namens "One-Off Pipelining". Dieses soll die Trainingszeit halbieren, indem es Training, Belohnungsberechnung und Sampling parallel durchführt. Pro Trainingsiteration müssten über tausend Tests ausgeführt werden.
Code, Gewichte, Trainingsdaten und -logs sowie Systemoptimierungen sollen wie auch bei vorherigen Modellen von Together AI der Open-Source-Community zur Verfügung gestellt werden. OpenAI hatte kürzlich angekündigt, sich bald wieder auf seine Anfänge zu besinnen und ebenfalls ein zumindest gewichtsoffenes Reasoning-System zu veröffentlichen. Together AI geht mit der Veröffentlichung des Trainingsdatensatzes und der nötigen Rezepte noch einen Schritt weiter.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.