OpenAI bringt GPT-4.1: Neue Modellfamilie soll Agenten, lange Kontexte und Coding verbessern

OpenAI führt mit GPT-4.1 drei neue Modelle in seine API ein. Sie sollen GPT-4o in nahezu allen Bereichen übertreffen – bei geringeren Kosten und höherer Geschwindigkeit.
Mit GPT-4.1, GPT-4.1 mini und GPT-4.1 nano stellt OpenAI eine neue Modellfamilie vor, die sich gezielt an Entwickler:innen richtet. Die KI-Systeme sollen in nahezu allen Bereichen leistungsfähiger, schneller und günstiger sein als ihre Vorgänger – darunter GPT-4o und GPT-4.5 Preview.
Die neuen Modelle sind ausschließlich über die API zugänglich und richten sich laut OpenAI explizit an professionelle Anwendungen. Für Nutzer:innen von ChatGPT bedeutet das: GPT-4.1 steht (vorerst) nicht direkt zur Verfügung – viele Verbesserungen seien jedoch bereits in GPT-4o eingeflossen, so das Unternehmen. Weitere sollen folgen.
Maßgeschneidert für Entwickler:innen
OpenAI betont, dass die GPT-4.1-Reihe gezielt auf Rückmeldungen aus der Entwickler:innen-Community hin entwickelt wurde. Im Fokus stehen typische Anforderungen moderner Softwareentwicklung: zuverlässige Formatierung, strukturierte Antworten, stabilere Codeausgabe – insbesondere im Frontend-Bereich – sowie besseres Langzeitgedächtnis für Agentenanwendungen. OpenAI legt großen Wert darauf, dass die KI "Code Diffs" beherrscht, also gezielte Änderungen an der Codebasis vornimmt, anstatt Dateien von Grund auf neu zu schreiben.
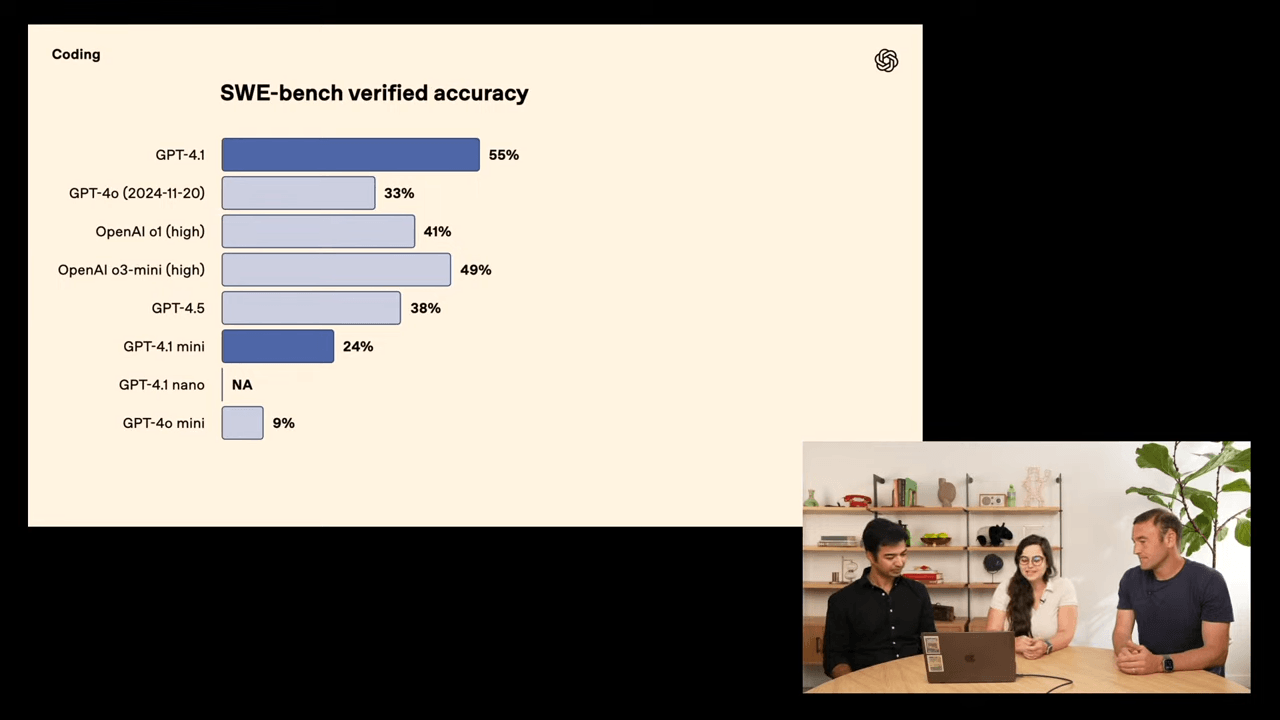
Das Flaggschiff GPT-4.1 übertrifft laut OpenAI seinen Vorgänger GPT-4o in zahlreichen Benchmarks: Im SWE-Bench Verified, einem Test für reale Softwareentwicklungsaufgaben, erreicht es 54,6 Prozent - ein Plus von über 21 Prozentpunkten gegenüber den eigenen Modellen. Einen Vergleich mit Claude 3.7 Sonnet, das in diesem Benchmark bis zu 70 Prozent erreicht, lässt OpenAI vermutlich bewusst aus. Auch bei mehrschrittigen Reasoning-Aufgaben zeigt GPT-4.1 eine bessere Leistung.
GPT-4.1 mini und nano: Effizienz und Geschwindigkeit im Fokus
Neben dem Hauptmodell führt OpenAI zwei kleinere Varianten ein: GPT-4.1 mini und GPT-4.1 nano. Beide sollen eine hohe Leistung bei reduziertem Ressourcenverbrauch bieten. GPT-4.1 mini ist laut OpenAI 83 Prozent günstiger als GPT-4o und doppelt so schnell – bei gleichzeitig ähnlicher oder besserer Performance in Benchmarks wie MMMU (Multimodal Understanding) und MathVista.
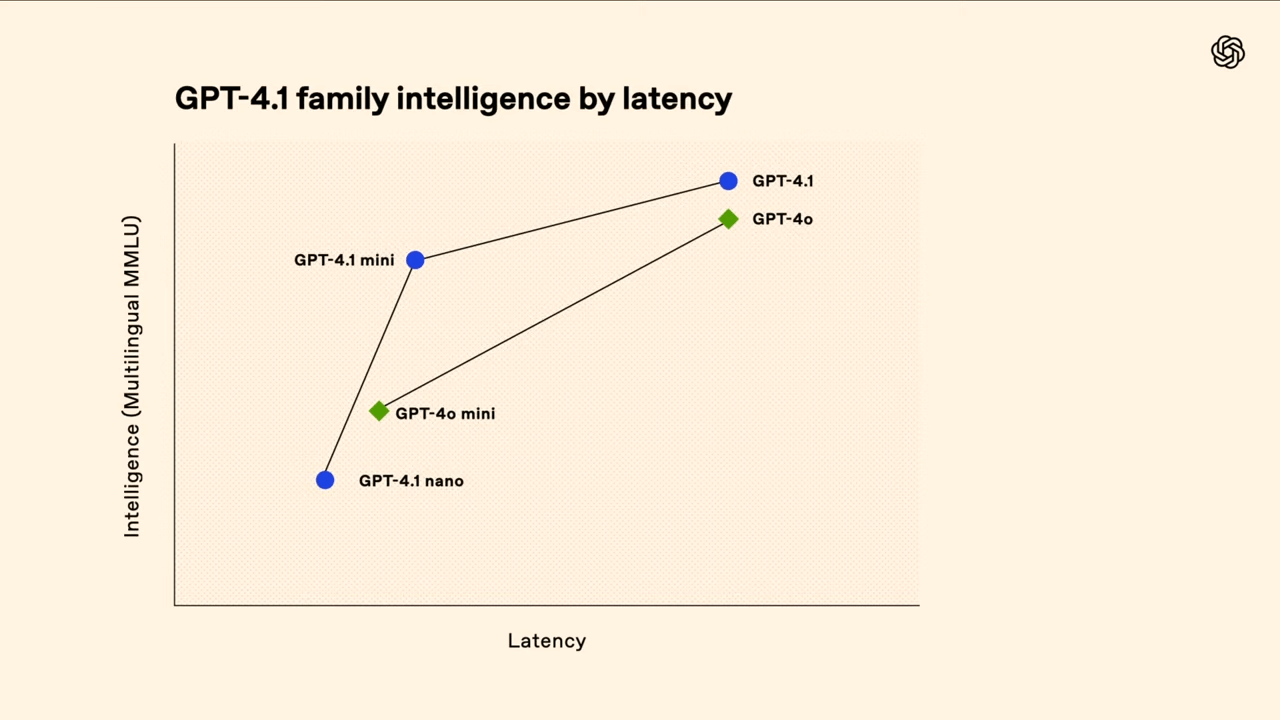
GPT-4.1 nano ist das kleinste Modell der Reihe und zielt auf besonders latenzkritische oder kostensensitive Anwendungen ab, etwa Klassifikation, Autovervollständigung und Informationsextraktion.
Erste OpenAI-Modelle mit einer Million Token Kontext
Ein zentrales Merkmal aller drei Modelle ist das neue, erweiterte Kontextfenster von bis zu einer Million Token, einer Verachtfachung gegenüber OpenAIs bisherigem Limit von 128.000 Token. Damit könnten theoretisch acht vollständige React-Codebasen gleichzeitig in einem Prompt analysiert werden.
Auch wenn das Kontextfenster wie auch bei der Konkurrenz von Googles Gemini 2.0 und Metas Llama 4 technisch beeindruckend ist, bedeutet das nicht automatisch, dass das Modell alle Informationen gleich gut verarbeiten kann. Auch OpenAI wirbt mit dem als veraltet geltenden Needle-in-a-Haystack-Test, den alle drei Modellversionen mit Bravour gemeistert haben sollen - räumt aber dessen eingeschränkte Aussagekraft ein und zeigt auch den selbst entwickelten neuen MRCR-Benchmark, der die Unterscheidungsfähigkeit zwischen ähnlichen Anfragen testen soll.
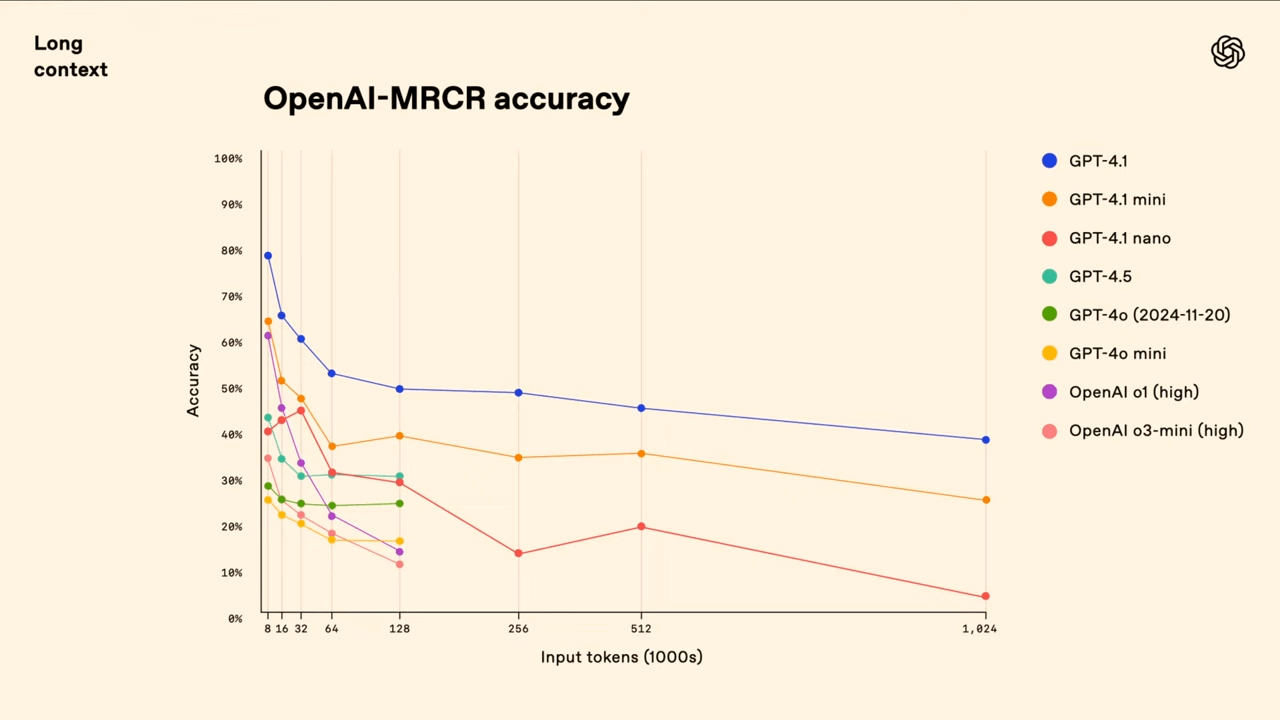
MRCR steht für „Multi-Round Coreference Resolution“ und prüft, wie gut ein Modell in der Lage ist, mehrere nahezu identische Nutzeranfragen in einem sehr langen Kontext auseinanderzuhalten. In diesem Test werden etwa zwei, vier oder acht gleichartige Aufforderungen wie „Schreibe ein Gedicht über Tapire“ im Kontext verteilt. Das Modell muss dann gezielt auf eine bestimmte Instanz dieser Anfragen reagieren – zum Beispiel: „Gib mir das dritte Gedicht über Tapire“. Die Schwierigkeit liegt in der hohen Ähnlichkeit der Anfragen und ablenkenden Elementen im Kontext, wodurch klassische Suchstrategien wie einfache Schlüsselwortsuche versagen.
Wenngleich sich GPT-4.1 hier an die Spitze setzt, offenbart die Grafik auch den dramatischen Leistungsabfall von 80 auf rund 50 Prozent bei vollständiger Nutzung des Kontextfensters. In einer Demo während des Livestreams benötigte GPT-4.1 weit mehr als eine Minute, um eine nachträglich eingefügte Zeile aus einer 450.000 Token langen Log-Datei zu identifizieren.
Ergänzend dazu testet der neue Graphwalks-Benchmark die Fähigkeit des Modells, logische Zusammenhänge über große Textmengen hinweg zu erkennen. Dabei wird der Text mit einem Netzwerk aus verbundenen Punkten (einem sogenannten Graphen) gefüllt. Das Modell soll dann herausfinden, welche Punkte in einer bestimmten Entfernung zu einem Startpunkt liegen – so, wie man in einem Stadtplan alle Orte sucht, die zwei Straßen entfernt sind. Diese Aufgabe kann man nicht einfach durch Lesen lösen, sondern das Modell muss die Verbindungen verstehen und „mitdenken“. Graphwalks prüft damit, ob ein KI-Modell wirklich in der Lage ist, über längere Abschnitte hinweg logisch zu schlussfolgern – eine wichtige Fähigkeit für komplexe Aufgaben wie juristische Analysen oder das Verstehen großer Codebasen.
GPT‑4.1 erzielt in diesem Benchmark mit Kontextlängen unter 128.000 Tokens eine Genauigkeit von 61,7 % und schlägt damit GPT‑4o (42 %) deutlich. Auch bei Kontexten über 128.000 Tokens bleibt GPT‑4.1 führend, obwohl die Genauigkeit dort auf 19 % sinkt – ein Zeichen dafür, wie herausfordernd diese Aufgaben bleiben. Kleinere Modelle wie GPT‑4.1 mini oder nano schneiden hier deutlich schwächer ab.
Kostenlos in Windsurf zum Start
Verschiedene Unternehmen berichten dennoch von messbaren Verbesserungen durch GPT-4.1. Der Legal-Tech-Anbieter Blue J meldet eine um 53 Prozent höhere Genauigkeit bei komplexen Steuerszenarien. Beim Datenanalyse-Tool Hex verdoppelte sich die Erfolgsquote bei SQL-Abfragen. Thomson Reuters konnte die Genauigkeit juristischer Dokumentanalyse um 17 Prozent steigern, Carlyle erreichte eine 50-prozentige Verbesserung bei der Extraktion aus langen Finanztexten.
Das Coding-Start-up Windsurf hatte ebenfalls Vorabzugang zu dem neuen OpenAI-Modell und bestätigt erhebliche Verbesserungen. Nutzer:innen können über die gleichnamige Entwicklungsumgebung für die nächsten sieben Tage kostenlos auf GPT-4.1 zugreifen, danach soll es erheblich rabattiert angeboten werden. Das könnte eine wirksame Werbemaßnahme auf dem aktuell heiß umkämpften Markt der "Vibe-Coding"-Programme sein, den vor allem Cursor dominiert.
GPT-4.5 wird abgestellt
Mit der neuen Modellfamilie verfolgt OpenAI auch eine aggressive Preispolitik: GPT-4.1 ist 26 Prozent günstiger als GPT-4o bei mittleren Anfragen. Die Eingabe kostet 2 US-Dollar, die Ausgabe 8 Dollar pro Million Token. GPT-4.1 nano ist mit 10 Cent pro Million Eingabetoken das günstigste Modell der OpenAI-API. Langkontextverarbeitung ist ohne Aufpreis enthalten, Prompt-Caching wird mit bis zu 75 Prozent rabattiert.

Das erst vor wenigen Wochen vorgestellte GPT-4.5 Preview wird am 14. Juli 2025 deaktiviert. "Wir brauchen diese GPUs wirklich dringend zurück", scherzen die Hosts im Livestream. OpenAI empfiehlt Entwickler:innen, frühzeitig auf GPT-4.1 umzusteigen. Einen aktualisierten Prompting-Guide stellt das Unternehmen hier bereit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.