OpenAIs o1 ist wohl mehr als nur ein elaborierter Step-by-Step-Prompt

OpenAI hat dem Modell bei o1 von Grund auf die beliebte "Schritt-für-Schritt"-Prompting-Methode beigebracht. Hinter der logischen Leistungsfähigkeit des Modells steckt jedoch noch mehr.
OpenAI hat laut eigenen Angaben mit dem o1-Modell einen Weg gefunden, die Rechenleistung bei der Inferenz zu skalieren. Mit mehr Rechenleistung und längerer Antwortzeit soll das Modell bessere Ergebnisse liefern, was einen neuen Skalierungshorizont eröffnet. Dem Modell wurde dafür die beliebte "Schritt für Schritt"-Prompting-Methode von Grund auf beigebracht.
Forscher von Epoch AI haben nun versucht, die Leistung von o1-preview in einem anspruchsvollen Multiple-Choice-Benchmark mit naturwissenschaftlichen Fragen (GPQA) zu erreichen, indem sie eine große Anzahl von Token mit GPT-4o unter Verwendung von zwei Prompting-Methoden (Revisions und Majority Voting) generierten, ähnlich wie es o1 in seinem "Denkprozess" tut.
Sie stellten fest, dass zwar eine leichte Verbesserung durch die Generierung einer großen Anzahl von Token erreicht werden kann, aber keine Anzahl von Token ausreicht, um auch nur annähernd die Leistung von o1-preview zu erreichen. Selbst bei einer hohen Anzahl generierter Token liegt die Genauigkeit der GPT-4o-Varianten deutlich unter der von o1-preview.
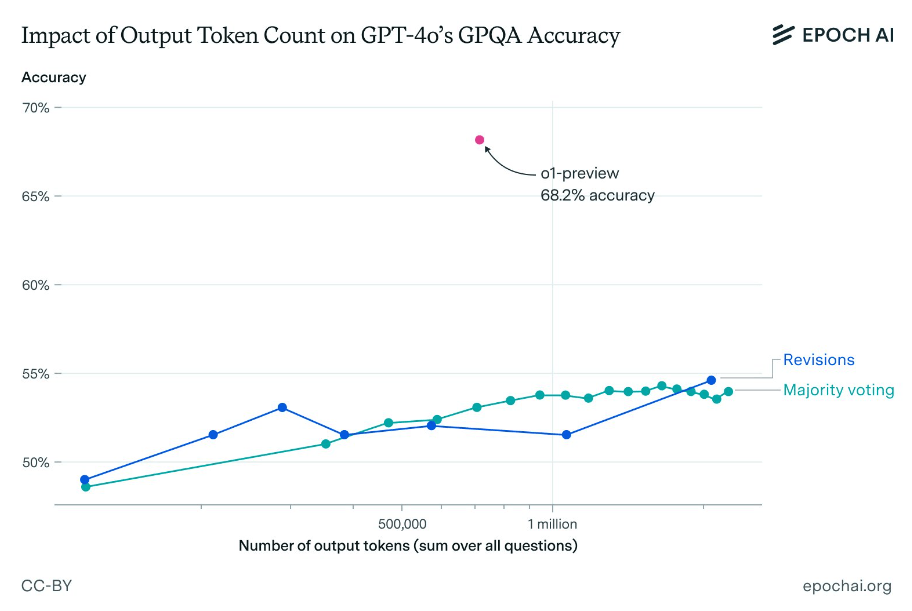
Das gilt auch, wenn man den höheren Preis pro Token von o1-preview berücksichtigt. Selbst wenn man 1000 USD für Ausgabe-Token ausgeben würde, wäre die Genauigkeit von GPT-4o immer noch mehr als 10 Prozentpunkte geringer als die von o1-preview, so die Extrapolation der Forscher.
Was macht o1 besser?
Die zentrale Schlussfolgerung ist, dass die naive Skalierung der Inferenzrechenleistung nicht ausreicht. Die überlegene Leistung von o1-preview ist wahrscheinlich auf fortgeschrittene RL-Techniken und bessere Suchmethoden zurückzuführen, was die entscheidende Rolle von algorithmischen Innovationen für den Fortschritt der KI unterstreicht.
Die Forscher weisen jedoch darauf hin, dass ihre Ergebnisse nicht unbedingt zeigen, dass algorithmische Verbesserungen den Unterschied zwischen o1-preview und GPT-4o erklären. Eine bessere Qualität der Trainingsdaten könnte ebenfalls eine Rolle spielen.
Da o1 direkt mit korrekten Denkpfaden trainiert wurde, könnte es auch sein, dass es schlicht viel effizienter ist, den gelernten logischen Schritten zu folgen, die schneller zum richtigen Ergebnis führen. Damit würde die zur Verfügung gestellte Rechenleistung besser genutzt.
Forscher der Arizona State University zeigten kürzlich, dass das neue KI-Modell von OpenAI deutliche Fortschritte bei Planungsaufgaben macht, aber weiterhin fehleranfällig ist. Laut den Forschern zeigt o1 zwar eine deutliche Verbesserung in den getesteten Logik-Benchmarks, bietet aber keine Garantie für die Richtigkeit der Lösungen. Klassische Planungsalgorithmen erreichen perfekte Genauigkeit bei kürzeren Rechenzeiten und geringeren Kosten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.